Урок 2. Составные условия
В прошлом уроке мы научились выбирать совершеннолетних пользователей с помощью простого SQL запроса.
SELECT last_name, first_name, birthday FROM users WHERE age >= 18Теперь попробуем немного уточнить запрос. Например, выберем всех совершенолетних мужчин. В таблицу я добавил дополнительное строковое поле sex, которое хранит m для мужчин и w для женщин:
| id | first_name | last_name | birthday | age | sex |
|---|---|---|---|---|---|
| 1 | Дмитрий | Иванов | 1996-12-11 | 20 | m |
| 2 | Олег | Лебедев | 2000-02-07 | 17 | m |
| 3 | Тимур | Шевченко | 1998-04-27 | 19 | m |
| 4 | Светлана | Иванова | 1993-08-06 | 23 | w |
| 5 | Олег | Ковалев | 2002-02-08 | 15 | m |
| 6 | Алексей | Иванов | 1993-08-05 | 23 | m |
| 7 | Алена | Процук | 1997-02-28 | 18 | w |
Давайте добавим вывод столбца sex и оставим только мужчин. Для этого в блоке условий, который начинается со слова WHERE нужно добавить AND sex = ‘m’:
SELECT last_name, first_name, birthday, sex FROM users WHERE age >= 18 AND sex = 'm'После выполнения SQL запроса получиться такая таблица:
| id | last_name | first_name | birthday | sex |
|---|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 | m |
| 3 | Шевченко | Тимур | 1998-04-27 | m |
| 6 | Иванов | Алексей | 1993-08-05 | m |
Посмотрим на SQL запрос. Сейчас блок WHERE содержит составное условие: возраст больше или равен 18 годам и пол равен m. Это простое логическое выражение, которому соответствуют все записи для которых оба условия верны. То есть у которых одновременно и возраст от 18 лет и sex = «m».
Кстати, о sex = «m». Так как мы используем равенство, в результируеющей таблице в колонке sex для всех записей у нас выводится m. Это не логично, ведь мы и так знаем, что выбираем мужчин, поэтому смысла в том, что мы эту информацию выводим в таблице нет. А значит можно удалить sex из запроса. Удалим и посмотрим на результат выполнения SQL-запроса:
SELECT last_name, first_name, birthday FROM users WHERE age >= 18 AND sex = 'm'| id | last_name | first_name | birthday |
|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 |
| 3 | Шевченко | Тимур | 1998-04-27 |
| 6 | Иванов | Алексей | 1993-08-05 |
Строки выводятся те же, однако столбца sex больше нет.
Обратите внимание, что извлекаем мы столбцы last_name, first_name, birthday, а фильтрутем по age и sex. То есть не обязательно чтобы столбцы, которые мы получаем, совпадали со столбцами в условии. Главное, чтобы все они были в таблице.
Но вернемся к составным условиям.
Кроме операции AND (И), в условии можно применять OR (ИЛИ). Давайте заменим AND на OR, а также вернем колонки sex и age:
SELECT last_name, first_name, birthday, sex FROM users WHERE age >= 18 OR sex = 'm'И посмотрим на результат:
| id | last_name | first_name | birthday | sex | age |
|---|---|---|---|---|---|
| 1 | Иванов | Дмитрий | 1996-12-11 | m | 20 |
| 2 | Лебедев | Олег | 2000-02-07 | m | 17 |
| 3 | Шевченко | Тимур | 1998-04-27 | m | 19 |
| 4 | Иванова | Светлана | 1993-08-06 | w | 23 |
| 5 | Ковалев | Олег | 2002-02-08 | m | 15 |
| 6 | Иванов | Алексей | 1993-08-05 | m | 23 |
| 7 | Процук | Алена | 1997-02-28 | w | 18 |
Получили всех мужчин, а также женщин, которым исполнилось 18 лет. В частности в SQL-таблице две женщины старше 18 лет и все мужчины, даже те, которым меньше 18. Всё это соответствует условию ИЛИ. ИЛИ возраст от 18 лет, ИЛИ мужской пол.
Теперь переключимся на таблицу products. В ней появилось поле country, которое содержит данные о стране производителе:
| id | name | count | price | country |
|---|---|---|---|---|
| 1 | Телевизор | 3 | 43200.00 | RU |
| 2 | Микроволновая печь | 4 | 3200.00 | RU |
| 3 | Холодильник | 3 | 12000.00 | UA |
| 4 | Роутер | 1 | 1340.00 | US |
| 5 | Компьютер | 0 | 26150.00 | US |
| 6 | Утюг | 6 | 3200.00 | BL |
| 7 | Пылесос | 11 | 4500.00 | UA |
Давайте выберем товары, произведененные в России, Белоруссии и на Украине. Напишем SQL-запрос:
SELECT * FROM products WHERE country = "RU" OR country = "UA" OR country = "BL"После выполнения запроса мы получим следующую таблицу:
| id | name | count | price | country |
|---|---|---|---|---|
| 1 | Телевизор | 3 | 43200.00 | RU |
| 2 | Микроволновая печь | 4 | 3200.00 | RU |
| 3 | Холодильник | 3 | 12000.00 | UA |
| 6 | Утюг | 6 | 3200.00 | BL |
| 7 | Пылесос | 11 | 4500.00 | UA |
Разберем запрос: в блоке WHERE мы используем три условия, разделенные OR (или). Во всех трех условиях мы с помощью символа равенства сравниваем значение в столбце country с одной из стран: ИЛИ Россия, ИЛИ Украина, ИЛИ Белоруссия.
Если мы хотим получить товары еще каких-то стран, то нужно добавить еще условия OR. Это не очень удобно, так как запрос становится громоздиким.
Но его можно упростить. Кроме стандартных условий сравнения AND и OR в языке SQL есть условие принадлежности IN, которое в данном случае подходит лучше. Напишем после WHERE:
SELECT * FROM products WHERE country IN ("RU", "UA", "BL")Конструкция получилась короче и понятней. И с помощью неё мы выбираем данные, в которых страна равна любом из значений перечисленных в скобках. После запуска запроса мы получим результат, аналогичный предыдущему.
Но давайте добавим к запросу еще одно условие. Например нам нужны не просто товары, а товары стоимостью до 10 000 рублей. Напишем:
SELECT * FROM products WHERE country IN ("RU", "UK", "BL") AND price < 10000И посмотрим результат:
| id | name | count | price | country |
|---|---|---|---|---|
| 2 | Микроволновая печь | 4 | 3200.00 | RU |
| 6 | Утюг | 6 | 3200.00 | BL |
| 7 | Пылесос | 11 | 4500.00 | UA |
Получили новую таблицу с тремя записями, которые удовлетовряют новому условию. И в этом условии мы совместили AND и IN. То есть в SQL-запросах можно совмещать логические операции AND и OR с оператором IN. Что делает их очень гибкими.
Теперь давай попробуем выбрать товары, стоимостью от 10000 до 20000.
Условие с country уберем и напишем:
SELECT * FROM products WHERE price >= 10000 AND price В результате получается такая таблица:
| id | name | count | price | country |
|---|---|---|---|---|
| 3 | Холодильник | 3 | 12000.00 | UA |
Выполним — получили 1 товар в этом ценовом интервале. Рассмотрим на запрос. Как видите в этой конструкции мы снова написали двойное условие по одному полю — price. И с одной строны всё логично и понятно, а с другой стороны эту конструкцию также можно упростить.
SELECT * FROM products WHERE price BETWEEN 10000 AND 20000Теперь запрос звучит так: ВЫБРАТЬ все столбцы из таблицы products, в которых цена между 10000 и 20000. Звучит более чем понятно.
После запуска мы получим всё тот же один товар.
Вообще AND, OR, IN и BETWEEN — это основные конструкции для построения условий в SQL запросах и используются они в блоке WHERE. Вы можете применять их как по одиночке, так комбинируя в самых разлчных вариантах.
Следующий урок
Урок 3. Порядок AND и OR
Вы узнаете о приоритете AND и OR, а также с ошибками, которые возникают у новичков в SQL-запросах с несколькими условиями.
Полный курс с практикой
- 57 уроков
- 261 задание
- Сертификат
- Поддержка преподавателя
- Доступ к курсу навсегда
- Можно в рассрочку
Navicat Blog
Have you ever seen a WHERE 1=1 condition in a SELECT query. I have, within many different queries and across many SQL engines. The condition obviously means WHERE TRUE, so it's just returning the same query result as it would without the WHERE clause. Also, since the query optimizer would almost certainly remove it, there's no impact on query execution time. So, what is the purpose of the WHERE 1=1? That is the question that we're going to answer here today!
Does WHERE 1=1 Improve Query Execution?
As stated in the introduction, we would expect the query optimizer to remove the hard-coded WHERE 1=1 clause, so we should not see a reduced query execution time. To confirm this assumption, let's run a SELECT query in Navicat both with and without the WHERE 1=1 clause.
First, here's a query against the Sakila Sample Database that fetches customers who rented movies from the Lethbridge store:
The execution time of 0.004 seconds (highlighted with a red outline) can bee seen at the bottom of the Messages tab.
Now, let's run the same query, except with the addition of the WHERE 1=1 clause:
Again, the execution time was 0.004 seconds. Although a query's run time can fluctuate slightly, depending on many factors, it is safe to say that the WHERE 1=1 clause had no effect.
So, why use it then? Simply put, it's.
A Matter of Convenience
The truth of the matter is that the WHERE 1=1 clause is merely a convention adopted by some developers to make working with their SQL statements a little easier, both in static and dynamic form.
In Static SQL
When adding in conditions to a query that already has WHERE 1=1, all conditions thereafter will contain AND, so it's easier when commenting out conditions on experimental queries.
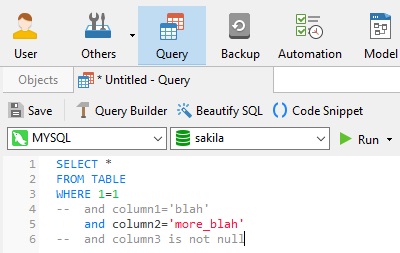
This is similar to another technique where you'd have commas before column names rather than after. Again, it's easier for commenting:
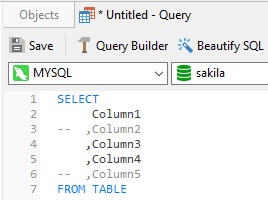
In Dynamic SQL
It's also a common practice when building an SQL query programmatically. It's easier to start with 'WHERE 1=1 ' and then append other criteria such as ' and customer.id=:custId', depending on whether or not a customer ID is provided. This allows the developer to append the next criterion in the query starting with 'and . '. Here's a hypothetical example:
stmt = "SELECT * " stmt += "FROM TABLE " stmt += "WHERE 1=1 " if user chooses option a then stmt += "and A is not null " if user chooses option b then stmt += "and B is not null " if user chooses option b then stmt += "and C is not null " if user chooses option b then stmt += "and D is not null "
Conclusion
In this blog, we learned the answer to the age-old question of "what is the purpose of the WHERE 1=1?" It's not an advanced optimization technique, but a style convention espoused by some developers.
Клёвые оптимизации SQL, не зависящие от стоимостной модели. Часть 2


Клёвые оптимизации SQL, не зависящие от стоимостной модели. Часть 1
4. Устранение "бессмысленных" предикатов
Столь же бессмысленными являются предикаты, которые (почти) всегда истинны. Как вы можете себе представить, если вы запрашиваете:
SELECT * FROM actor WHERE 1 = 1;
. то базы данных не станут его фактически выполнять, а просто проигнорируют. Я однажды отвечал на вопрос об этом на сайте Stack Overflow и именно поэтому решил написать данную статью. Оставлю проверку этого в качестве упражнения читателю, но что произойдет, если предикат чуть-чуть менее "бессмысленный"? Например:
SELECT * FROM film WHERE release_year = release_year;
Нужно ли действительно сравнивать значение с самим собой для каждой строки? Нет, ведь значения, для которого этот предикат будет FALSE, не существует, правда? Но нам все равно нужно проверить это. Хотя предикат не может оказаться равным FALSE, он вполне может оказаться везде равным NULL, опять же вследствие трёхзначной логики. Столбец RELEASE_YEAR допускает неопределенное значение, и если для какой-либо из строк RELEASE_YEAR IS NULL, то NULL = NULL даёт NULL и строку необходимо исключить. Так что запрос преобразуется в следующий:
SELECT * FROM film WHERE release_year IS NOT NULL;
Какие же из баз данных это выполняют?
DB2
Explain Plan ------------------------------------------------- ID | Operation | Rows | Cost 1 | RETURN | | 49 2 | TBSCAN FILM | 1000 of 1000 (100.00%) | 49 Predicate Information 2 - SARG Q1.RELEASE_YEAR IS NOT NULL
MySQL
Как ни жаль, но MySQL, опять-таки, не отображает предикаты в планах выполнения, так что выяснить, осуществляет ли MySQL эту конкретную оптимизацию, немного затруднительно. Можно выполнить оценку производительности и выяснить, производятся ли какие-нибудь масштабные сравнения. Или можно добавить индекс:
CREATE INDEX i_release_year ON film (release_year);
И получить взамен планы для следующих запросов:
SELECT * FROM film WHERE release_year = release_year; SELECT * FROM film WHERE release_year IS NOT NULL;
Если оптимизация работает, то планы обоих запросов должны оказаться примерно одинаковыми. Но в данном случае это не так:
ID TABLE POSSIBLE_KEYS ROWS FILTERED EXTRA ------------------------------------------------------ 1 film 1000 10.00 Using where ID TABLE POSSIBLE_KEYS ROWS FILTERED EXTRA ------------------------------------------------------ 1 film i_release_year 1000 100.00 Using where
Как вы можете видеть, два наших запроса существенно различаются в значениях столбцов POSSIBLE_KEYS и FILTERED. Так что я рискну обоснованно предположить, что MySQL это не оптимизирует.
Oracle
---------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | ---------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | |* 1 | TABLE ACCESS FULL| FILM | 1 | 1000 | ---------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - filter("RELEASE_YEAR" IS NOT NULL)
PostgreSQL
QUERY PLAN -------------------------------------------------------------- Seq Scan on film (cost=0.00..67.50 rows=5 width=386) Filter: ((release_year)::integer = (release_year)::integer)
Планы и стоимости различны. А именно, взгляните на оценку кардинальности, которая совершенно никуда не годится, в то время как вот этот предикат:
SELECT * FROM film WHERE release_year IS NOT NULL;
дает намного лучшие результаты:
QUERY PLAN --------------------------------------------------------- Seq Scan on film (cost=0.00..65.00 rows=1000 width=386) Filter: (release_year IS NOT NULL)
SQL Server
Как ни странно, но SQL Server, похоже, тоже этого не делает:
|--Table Scan(OBJECT:([film]), WHERE:([release_year]=[release_year]))
Однако по внешнему виду плана оценка кардинальности правильная, как и стоимости. Но по своему опыту работы с SQL Server я бы сказал, что, в данном случае, никакой оптимизации не происходит, поскольку SQL Server бы отобразил в плане фактически выполненный предикат (чтобы понять почему, взгляните на примеры ограничения CHECK ниже). А что же насчет "бессмысленных" предикатов по не допускающим неопределенного значения (NOT NULL) столбцам? Вышеприведенное преобразование было необходимо лишь потому, что RELEASE_YEAR может принимать неопределенное значение. Что получится, если выполнить тот же бессмысленный запрос, например, со столбцом FILM_ID?
SELECT * FROM film WHERE film_id = film_id
Теперь он соответствует отсутствию предиката вообще? Или, по крайней мере, так должно быть. Но так ли это?
DB2
Explain Plan ------------------------------------------------- ID | Operation | Rows | Cost 1 | RETURN | | 49 2 | TBSCAN FILM | 1000 of 1000 (100.00%) | 49
Никаких предикатов вообще не применяется и мы выбираем все фильмы.
MySQL
Да! (Опять же, обоснованное предположение)
ID TABLE POSSIBLE_KEYS ROWS FILTERED EXTRA ------------------------------------------------------ 1 film 1000 100.00
Обратите внимание, что столбец EXTRA теперь пуст, как будто у нас вообще нет предложения WHERE!
Oracle
---------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | ---------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | | 1 | TABLE ACCESS FULL| FILM | 1 | 1000 | ----------------------------------------------------
Опять же, никаких предикатов не применяется.
PostgreSQL
Ничего себе, опять нет!
QUERY PLAN ------------------------------------------------------ Seq Scan on film (cost=0.00..67.50 rows=5 width=386) Filter: (film_id = film_id)
Применяется фильтр и оценка кардинальности по-прежнему равна 5. Облом!
SQL Server
И тут опять нет!
|--Table Scan(OBJECT:([film]), WHERE:([film_id]=[film_id]))
Резюме
Вроде бы и простая оптимизация, но она применяется отнюдь не во всех СУБД, в частности, как ни странно, не применяется в SQL Server!
| База данных | Бессмысленные, но нужные предикаты (семантика NULL) | Бессмысленные и не нужные предикаты (семантика не NULL) |
|---|---|---|
| DB2 LUW 10.5 | Да | Да |
| MySQL 8.0.2 | Нет | Да |
| Oracle 12.2.0.1 | Да | Да |
| PostgreSQL 9.6 | Нет | Нет |
| SQL Server 2014 | Нет | Нет |
5. Проекции в подзапросах EXISTS
Что интересно, о них меня все время спрашивают на моём мастер-классе, где я отстаиваю точку зрения о том, что SELECT * обычно до добра не доводит. Вопрос состоит в том: можно ли использовать SELECT * в подзапросе EXISTS? Например, если нам нужно найти актеров, игравших в фильмах.
SELECT first_name, last_name FROM actor a WHERE EXISTS ( SELECT * -- Is this OK? FROM film_actor fa WHERE a.actor_id = fa.actor_id )
И ответ. да. Можно. Звездочка не влияет на запрос. Как убедиться в этом? Рассмотрим следующий запрос:
-- DB2 SELECT 1 / 0 FROM sysibm.dual -- Oracle SELECT 1 / 0 FROM dual -- PostgreSQL, SQL Server SELECT 1 / 0 -- MySQL SELECT pow(-1, 0.5);
Все эти базы данных сообщают об ошибке деления на нуль. Обратите внимание на интересный факт: в MySQL, при делении на нуль, в результате мы получаем NULL, а не ошибку, так что нам приходится выполнять другое запрещенное действие. Теперь, что произойдет, если мы выполним, вместо вышеприведенных, вот такие запросы?
-- DB2 SELECT CASE WHEN EXISTS ( SELECT 1 / 0 FROM sysibm.dual ) THEN 1 ELSE 0 END FROM sysibm.dual -- Oracle SELECT CASE WHEN EXISTS ( SELECT 1 / 0 FROM dual ) THEN 1 ELSE 0 END FROM dual -- PostgreSQL SELECT EXISTS (SELECT 1 / 0) -- SQL Server SELECT CASE WHEN EXISTS ( SELECT 1 / 0 ) THEN 1 ELSE 0 END -- MySQL SELECT EXISTS (SELECT pow(-1, 0.5));
Теперь ни одна из баз данных не возвращает ошибку. Все они возвращают TRUE или 1. Это значит, что ни одна из наших баз данных, на самом деле, не вычисляет проекцию (то есть предложение SELECT) подзапроса EXISTS. SQL Server, например, показывает следующий план:
|--Constant Scan(VALUES:((CASE WHEN (1) THEN (1) ELSE (0) END)))
Как вы можете видеть, выражение CASE было преобразовано в константу, а подзапрос был устранен. У других баз данных подзапрос сохраняется в плане, а относительно проекции ничего не упоминается, так что давайте взглянем еще раз на план исходного запроса в Oracle:
SELECT first_name, last_name FROM actor a WHERE EXISTS ( SELECT * FROM film_actor fa WHERE a.actor_id = fa.actor_id )
План вышеприведенного запроса выглядит следующим образом:
------------------------------------------------------------------ | Id | Operation | Name | E-Rows | ------------------------------------------------------------------ | 0 | SELECT STATEMENT | | | |* 1 | HASH JOIN SEMI | | 200 | | 2 | TABLE ACCESS FULL | ACTOR | 200 | | 3 | INDEX FAST FULL SCAN| IDX_FK_FILM_ACTOR_ACTOR | 5462 | ------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("A"."ACTOR_ID"="FA"."ACTOR_ID") Column Projection Information (identified by operation id): ----------------------------------------------------------- 1 - (#keys=1) LAST_NAME, FIRST_NAME 2 - (rowset=256) A.ACTOR_ID, FIRST_NAME, LAST_NAME 3 - FA.ACTOR_ID
Наблюдаем информацию о проекции при Id=3. На самом деле, мы даже не обращаемся к таблице FILM_ACTOR, поскольку нам этого не требуется. Предикат EXISTS можно выполнить при помощи индекса внешнего ключа по одному столбцу ACTOR_ID – всё, что нужно для данного запроса – несмотря на то, что мы написали SELECT *.
Резюме
К счастью, все наши базы данных убирают проекцию из подзапросов EXISTS:
| База данных | Проекция EXISTS |
|---|---|
| DB2 LUW 10.5 | Да |
| MySQL 8.0.2 | Да |
| Oracle 12.2.0.1 | Да |
| PostgreSQL 9.6 | Да |
| SQL Server 2014 | Да |
Публикация участника Кирилл Серый
��♂️ Капитан очевидность: зачем разработчики на SQL используют конструкцию «WHERE 1=1» в своем коде. Иногда в коде SQL-запроса можно встретить условие, присутствие которого, на первый взгляд, лишено всякого смысла: SELECT a FROM table WHERE 1=1 AND a IS NOT NULL; Речь, естественно, идет об условии «1=1», которое всегда истинно, а значит, его можно было бы исключить из данного запроса без влияния на результат. А если влияния нет, то зачем писать «лишний» код и тем самым усложнять его чтение и исполнение? Существует, как минимум, две причины делать это: 1. Комментарии. Когда вы пишете SQL-запрос с множеством условий WHERE, в процессе работы вы можете менять активные фильтры, комментируя те строки, условия которых не должны действовать при последующем исполнении запроса. Например, вы хотите закомментировать первое условие в блоке: WHERE --a IS NOT NULL AND b IS NOT NULL и получаете ошибку синтаксиса, т.к. текст условия начинается с «AND». Конечно, вы можете использовать многострочный комментарий: WHERE /*a IS NOT NULL AND*/ b IS NOT NULL , но это занимает вечность по сравнению с использованием быстрых клавиш, которые присутствуют в каждом IDE. Добавление же в качестве первого условия «1=1» (или последнего, если вы привыкли дописывать «AND» в конце строки) позволяет выполнять комментирование, не приводящее к ошибкам синтаксиса: WHERE 1=1 --AND a IS NOT NULL AND b IS NOT NULL 2. Динамическая генерация кода. Если вы генерируете SQL-запрос, включая некоторое количество условий, динамически, вы также можете столкнуться с тем, что без условия «1=1» в некоторых ситуациях сформированный SQL-запрос будет синтаксически неверен. В следующем примере запрос, генерируемый при помощи jinja-шаблонов, при отсутствии значений фильтра filter_1 не вернет ошибку как раз потому, что первым идет условие «1=1»: WHERE 1=1 AND column_1 IN > AND column_2 IN > С причинами разобрались, но как быть с тем, что проверки условий потребляют ресурсы? В данном случае не стоит беспокоиться на этот счет. Дело в том, что современные СУБД спроектированы так, чтобы не расходовать лишние ресурсы на проверки константных условий, которым и является «1=1». Таким образом, его добавление практически не оказывает влияния на время выполнения SQL-запроса. PS Пользуясь случаем, хотел бы рассказать и о «брате-близнеце» условия «1=1» — «1=0». Всегда ложное условие, являющееся единственным или объединенное (AND) с другими, приводит к тому, что результат запроса вернет 0 строк. Мне нравится применять эту хитрость при копировании структуры таблиц: SELECT a, b, c INTO table_2 FROM table_1 WHERE 1=0; Такой запрос скопирует всю структуру (названия и типы данных полей) таблицы table_1 в таблицу table_2, но не ее данные, что сэкономит ресурсы БД, если в самих данных нет необходимости. #sql
- Копировать
мне всегда было привычно наоборот писать where true не знала, что where 1=1 наиболее распространен)
Analytics Engineer @ Smartcat
Почему where 1=1, а не where true? ��
Чтобы просмотреть или add a comment, выполните вход
Больше актуальных публикаций
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
3 мес. Отредактировано
�� Платные обучающие курсы для middle-разработчиков: Стоит ли вкладываться в них? Многие middle-разработчики сталкиваются с вопросом о целесообразности покупки обучающих курсов. Сегодня я хочу поделиться своими размышлениями на эту тему и приглашаю вас присоединиться к обсуждению. Лично я склоняюсь к мнению, что покупка обучающих курсов для middle-разработчиков часто оправдывает себя не полностью. Однако моя точка зрения основана лишь на личном опыте, и я буду рад услышать ваше мнение. В моем опыте обучения и развития как middle-разработчика я отметил несколько факторов, которые влияют на мое мнение: — Ценность сертификатов. Для middle-разработчиков сертификаты о прохождении курсов имеют значительно меньшую ценность по сравнению с джунами. Мы определяемся не столько сертификатами, сколько портфолио и реальными навыками. — Самостоятельное обучение. С middle-уровнем опыта мы обычно умеем искать информацию самостоятельно, что делает покупку курсов менее обязательной. — Конкретная практика. Middle-разработчикам часто нужны конкретные знания и навыки, а не обширные программы. Иногда одно видео на YouTube может быть более полезным, чем длинный курс. — Предложения на рынке. Сложность создания универсальных курсов для middle-разработчиков и различный уровень знаний делают выбор курсов сложным. — Поддержка от работодателя. Многие компании предоставляют обучение как часть компенсационного пакета, что также влияет на решение покупать платные курсы. Давайте обсудим, насколько для вас актуально обучение на платных курсах. Какие из перечисленных факторов, на ваш взгляд, оказывают наибольшее влияние на решение middle-разработчиков приобретать обучающие курсы?
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
�� Формирование JSON в SQL Server. Если парсинг данных в формате JSON давно стал рутиной любого инженера данных, то как быть с формированием JSON при помощи привычных инструментов? Например, в SQL Server на этот случай припасен метод FOR JSON, с которым я и хочу познакомить вас сегодня. У этого метода есть несколько опций и параметров, используя которые, можно с легкостью достичь требуемого результата. Разберем эти методы на примере подготовленной таблицы со следующими данными клиентов (для простоты используем таблицу с одной строкой): client_id = (не имеет значения для примера), surname = Doe, name = John, address.country = USA, address.city = Los Angeles, address.street и address.building = NULL. В приложенном файле я выделил фрагменты запроса и результата цветом, аналогичным цвету маркера в списке - надеюсь, так будет проще сориентироваться: �� FOR JSON AUTO действует прямолинейно: название поля станет ключом пары, а значение поля - ее значением. Все перечисленные поля будут ключами одного уровня. �� FOR JSON PATH учитывает точки в именах, за счет чего можно передать в качестве значения объект (значения объединятся в объект под одинаковым префиксом - "address.*"). �� INCLUDE_NULL_VALUES отображает пары без значения, если добавить его в запрос (по умолчанию, пары, где значение - null, не выводятся). �� ROOT() добавляет верхнеуровневый элемент с указанным именем. �� Если в качестве значения нужно передать массив, используется вставка подзапроса в SELECT-е или INNER JOIN таблиц (мне больше нравится первый вариант, примененный в примере). В этом случае алиас второй таблицы станет ключом для массива. Это все основные опции метода FOR JSON, которые стоит знать для старта - остальное можно при необходимости подсмотреть в документации. Когда мне пришлось постигать мудрость формирования JSON в SQL Server, я очень пожалел, что у меня нет под рукой подобной шпаргалки. В итоге пришлось обучаться методом проб и ошибок. Надеюсь, этот пост окажется полезным для всех пользователей SQL Server. #sqlserver #json
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
���� Типы таблиц в Power BI: физические, рассчитанные и виртуальные. Большинство из тех, кто регулярно создает отчеты в Power BI, знают, что хорошей практикой является создание отдельной таблицы для хранения мер вместо добавления мер прямо в таблицах с данными. Это позволят не только поддерживать порядок в отчете, но и предохраняет от потерь данных после смены источника. Начав свой путь в роли BI разработчика пару лет назад, я быстро перенял эту практику, но вместе с этим обратил внимание, что мы с коллегами создаем таблицы для мер по-разному. А точнее, я заметил разные иконки у наших таблиц с мерами на панели данных. Оставалось только изучить тему и определить чей способ «правильнее»��. Существуют три типа таблиц в Power BI. Физические (physical) таблицы – это данные из источников, загруженные в отчет. Как правило, они представляют из себя данные источника «as is», либо трансформированные при помощи редактора Power Query. Это физические данные (кеш), которые занимают место на диске, что в свою очередь негативно сказывается на размере файла с отчетом. С другой стороны, операции с такими данными занимают меньше времени, и в результате отчет работает быстрее. Рассчитанные (calculated) таблицы, в отличие от физических, основаны не на данных источников напрямую, а являются результатом расчета DAX-формулы с использованием функции, возвращающей таблицу (например, функции SELECTCOLUMNS). Эти таблицы также кешируются, поэтому обладают плюсами и минусами физических таблиц, описанными выше. Благодаря этому свойству рассчитанные таблицы используются в том числе и для ускорения работы отчетов. Виртуальные (virtual) таблицы, подобно представлениям в базах данных, представляют собой не что иное как блок кода, а потому не занимают физического места (точнее, занимают, но ничтожный объем). Эти таблицы создаются и «существуют» только в момент исполнения кода, содержащего функцию, возвращающего таблицу (например, функцию SUMMARIZE), а значит, операции с данными таких таблиц займут больше времени: сначала рассчитается таблица, затем будут произведены необходимые операции. Физические и рассчитанные таблицы можно сравнить с простыми таблицами в базах данных (сырыми данными и агрегатами – соответственно), а виртуальные – с представлениями. Стоит отметить, что, сравнивая рассчитанные столбцы и меры, можно руководствоваться теми же принципами, что и при сравнении рассчитанных и виртуальных таблиц: предпочитая меры, вы экономите на объеме файла с отчетом и времени его обновления, но проигрываете в скорости работы. Возвращаясь к предыстории: с тех пор я продолжаю использовать следующий способ создания таблицы мер, выбранный когда-то интуитивно. 1 – создать пустой запрос (Blank query) в Power Query и применить изменения; 2 – добавить в созданную таблицу меру; 3 – удалить колонку Column1 (иконка таблицы должна смениться). В итоге получаю группу мер (measure group) – частный пример виртуальной таблицы (с той лишь оговоркой, что она отображается в модели данных).
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
4 мес. Отредактировано
�� Monthly necromancy # 1. Today I would like to start a monthly section where I will remind the audience about the posts I’ve written previously (mostly in the previous month). 1. A free programming book every day. (https://lnkd.in/dFe8vZYU) I presented my pet project of a web parser written in Python with a pyppeteer library. This parser can go to the PacktPub site automatically and add to the user’s personal account a book that is new every day. 2. The secret of effective notes, parts 1 (https://lnkd.in/dZSr4M6S) & 2. (https://lnkd.in/damF8b2z) Here I told how Obsidian, a “second brain” tool, helped me upgrade my taking notes skill and productivity. Also, I provided some alternatives to Obsidian for those who don’t like it. 3. “Lest Cthulhu rise again, subscribe to the RSS, my friend”. (https://lnkd.in/dNjNaUMG) I shared a personal experience of transforming such information sources as Telegram channels into RSS feeds using the RSSHub service. 4. Music nonstop: How I collected a long-term history of my likes on Yandex Music using a yandex-music Python library. (https://lnkd.in/d7Wgr_BZ) This was a story about another pet project of mine where I collected some data that was necessary for me from the unofficial Yandex Music API using Python. 5. Nobody knows about COALESCE. (https://lnkd.in/du648Tdn) The latest post was about a COALESCE SQL function. There, I shared my thoughts about why this function is unpopular among novice analysts and showed what’s under its hood. This month was very productive for me, and I’m not going to stop. I really appreciate everybody’s reactions to my posts, and I thank you and every reader from the bottom of my heart. Stay tuned!
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
4 мес. Отредактировано
�� Никто не знает про COALESCE. При написании SQL-запросов я долгое время не использовал функцию COALESCE и вовсе не понимал ее смысла несмотря на то, что она не просто облегчает жизнь SQL-разработчика, но и предотвращает возникновение некоторых непредвиденных ошибок. По моим наблюдениям, COALESCE не проходят в рамках курсов для начинающих и ошибочно считают «магией высшего порядка». Я знаю это, потому что и сам когда-то так думал. Стоит пояснить, для чего нужен COALESCE: Эта функция принимает несколько аргументов (полей, значений, выражений и даже подзапросов) и возвращает первый из них, который не является NULL. Чаще всего на практике она применяется с указанием двух аргументов, что означает примерно следующее: «Верни значения первого аргумента, заменив в результате NULL-ы вторым». Звучит просто, но новички в SQL не спешат применять функцию на практике, и вот почему: существует более громоздкое, но универсальное решение с использованием CASE WHEN. Сравните: COALESCE(my_col, 'no data') и CASE WHEN my_col IS NULL THEN 'no data' ELSE my_col END Оба выражения вернут одинаковый результат, потому что (сюрприз!) COALESCE, это и есть CASE WHEN – под капотом. Учитывая это, неудивительно, что новички, если и решают заменять NULL-ы другими значениями, предпочитают идти сто раз хоженой дорожкой CASE WHEN, нежели обращаться к более узконаправленному COALESCE, и я их понимаю. Тем не менее, код с использованием COALESCE является более лаконичным и выглядит читабельнее даже при двух аргументах (см. пример выше), не говоря уже о трех и более. Зачем вообще заменять NULL-ы в столбце? Причин много, начиная от того, что ожидаемый результат не должен их содержать (например, результирующий набор данных планируется вставить в таблицу, где стоит ограничение NOT NULL на целевом поле), и заканчивая тем, что, как я упоминал в самом начале, это может приводить в непредвиденным ошибкам при выполнении операций со значениями или фильтрации. Приведу короткий пример: Есть поле my_col со значениями 0, 1 и NULL. Вы выполняете фильтрацию WHERE my_col <> 1 и ожидаете получить 0 и NULL, но получаете только 0. Ошибка заключается в том, что к значениям NULL не применяется сравнение равенством. Именно поэтому мы используем IS NULL и IS NOT NULL, а не = NULL и <> NULL. Заменив же значения NULL в текущем примере при помощи COALESCE - WHERE COALESCE(my_col, 'no data') <> 1 - вы получите и 0, и 'no data'. Если это позволяет бизнес логика, вы можете также заменить NULL-ы на 0, и получить только 0, как и в самом начале, но, во-первых, вы получите уже две строки, а не одну, а во-вторых, это уже будет ваше осознанное решение. Надеюсь, что сумел раскрыть тайну COALSCE для тех, кто не знал о нем или знал, но старался обходить стороной. Пишите в комментариях, используете ли COALSCE при написании SQL-запросов, и если да, то когда начали это делать относительно знакомства c базовым SQL – будет интересно узнать. И запомните первое правило клуба COALESCE: «Рассказывай всем про COALESCE». #sql
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
4 мес. Отредактировано
�� Music nonstop: Как я собрал многолетнюю историю своих лайков из Яндекс Музыки при помощи Python-библиотеки yandex-music. В своей жизни мне не раз приходилось переходить с одного музыкального стримингового сервиса на другой. При этом с содержимым медиатеки - полностью или частично - зачастую приходилось попрощаться, так как всегда имела место проблема совместимости сервисов. Что-то, конечно, рано или поздно вспоминалось, а с чем-то из понравившихся треков/альбомов/исполнителей мне, увы, пришлось попрощаться навсегда. Идеей для этого проекта послужили две вещи: 1. В скором времени я планирую попрощаться с Яндекс Музыкой, а значит, и со своей медиатекой (спойлер: уже нет); 2. Недавно я познакомился с инструментом для ведения собственной базы знаний – Obsidian (о нем я рассказывал ранее: https://lnkd.in/dZSr4M6S) - в нем я планирую держать заметки о тех исполнителях, которые мне нравятся. Да, это не так удобно, как перекочевать в другой стриминг, синхронизировав свою медиатеку нативно или при помощи сторонних сервисов, но идея того, что эти заметки будут принадлежать только мне, и зависимость от вендоров хотя бы в этом плане пропадет, меня подкупает. Все, что я собираюсь хранить, это: — название/имя исполнителя; — его дискография (желательно, с моей оценкой по пятибальной шкале); — список любимых треков (уже без оценки). Такой формат удобен исключительно для меня, но адаптировать его под иные пожелания, при необходимости, не составит труда. Разобравшись с библиотекой yandex-music (неофициальный API Яндекс Музыки: https://lnkd.in/dJfQu64G), я сперва выгрузил необходимые мне данные и разложил по markdown-файлам в нужном мне виде, а потом прошелся скриптом «косметического улучшателя», который убрал дубли в альбомах и расположил их в хронологическом порядке. В результате я загрузил почти 400 (!) файлов и сэкономил уйму времени в сравнении с переносом всех этих данных вручную. С содержимым проекта вы можете ознакомиться на моем GitHub по ссылке: https://lnkd.in/dQuy3iAK . #petproject #python #api #github
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
5 мес. Отредактировано
�� Чтобы Ктулху не воскрес, подпишись на RSS. Как RSS обрел для меня вторую жизнь и позволил разгрузить интерфейс Telegram. ℹ️ RSS – формат данных, который используется для сбора и распространения обновлений контента с веб-сайтов. Я практически отказался от соцсетей из-за их рекомендаций, «умных лент» и ограничений, которые совершенно разочаровали меня. В итоге, после перевода всех источников информации преимущественно в RSS + Telegram, последний распух до безобразия: среди каналов, которые производят контент с различной периодичностью (это может быть как несколько постов в день, так и один пост раз в 2-3 недели) стало нереально находить нужные чаты и каналы. Ни папки, ни другие функции Telegram не могли тут помочь, и потребление контента превратилось в наказание. К счастью, я узнал о том, что существует возможность подписываться на каналы в Telegram как обычные RSS-ленты. Для этого у проекта RSSHub есть готовое решение. ℹ️ RSSHub – проект с открытым исходным кодом, представляющий собой агрегатор RSS-фидов (новостных лент). Создайте ссылку на канал по шаблону: «rsshub.app/ telegram/ channel/» + имя канала. Например, «rsshub.app/ telegram/ channel/ animatron» - для канала Animatron. Важно: «имя канала» – это не то же самое, что и заголовок. Его можно найти во вкладке «Информация»). После этого готовую ссылку нужно указать в качестве источника подписки в любимой RSS-читалке. Должен добавить, что такой способ работает только с открытыми каналами. В итоге я не только гораздо удобнее структурировал источники полезной информации, но и обеспечил порядок в Telegram, что позволило мне гораздо эффективнее поддерживать общение с контактами. Благодаря RSSHub в RSS-ленту можно превратить не только Telegram, но и множество других социальных сетей. Подробнее вы можете узнать об этом на сайте проекта (https://docs.rsshub.app). Если вы ранее не пользовались RSS, но хотели бы начать, рекомендую читалку Feedly (https://feedly.com/) – она очень удобна, а бесплатного тарифа хватит большинству пользователей. #rss #telegram #productivity
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
5 мес. Отредактировано
�� Секрет эффективных заметок, ч.2 Пару дней назад я рассказывал о том, почему веду свои заметки именно в Obsidian (https://lnkd.in/davsh6gJ). Сегодня же я хотел бы рассказать о том, как именно он повысил мою эффективность. После начала работы с Obsidian я перенес туда все заметки, ранее хранившиеся в папках на различных устройствах и заметочных сервисах. С тех пор при возникновении вопросов по знакомым темам я сперва обращаюсь к заметкам – это позволяет лишний раз переосмыслить свой опыт (дополнить/исправить заметку). Если поиск не приносит результатов – ищу в интернете, а потом добавляю заметку. Кроме этого, я уже сделал несколько pet-проектов, которые позволяют мне автоматизировать рутинный/сложный процесс сохранения информации в заметках (о втором таком проекте расскажу в следующий раз). В ходе выполнения этих проектов я также получаю новые знания, оттачиваю прежние навыки и… дополняю заметки! Ключевой же момент достижения эффективности – это написание заметок самостоятельно (а не простое копирование материалов из интернета) и рефлексия. Возвращаясь к старым заметкам, вы наверняка захотите исправить или дополнить информацию, содержащуюся в них. Также возможно и то, что это подтолкнет вас к движению в ранее неизведанном направлении. В конце я хочу пожелать каждому найти заметочник по душе, ведь неважно, где и как вы делаете заметки: в Obsidian, в Блокноте или на полях. Главное – это сам факт создания заметок и их использования. А на тот маловероятный случай, если Obsidian вас не устроит, позволю себе упомянуть еще несколько аналогов, о которых вы могли не знать: — Logseq (https://logseq.com/) - максимально похож на Obsidian; — Joplin (https://joplinapp.org/) - нечто среднее между Obsidian и Evernote; — Anytype (https://anytype.io/) - находится на стадии открытой беты; приглянется фанатам Notion. #obsidian #productivity
- Копировать
Чтобы просмотреть или add a comment, выполните вход
BI-разработчик в Nexign | Power BI, SQL Server, SSRS, SSIS, SSAS, PostgreSQL, Airflow, Python
5 мес. Отредактировано
�� Секрет эффективных заметок, ч.1 На прошлой неделе я рассказывал о своем новом pet-проекте и упомянул Obsidian (https://obsidian.md/) – ПО для ведения заметок и, не побоюсь сказать, создания «второго мозга». Сегодня я хотел бы рассказать о том, чем он меня впечатлил. За последние десять лет я использовал немало заметочных сервисов (Evernote, Notion, OneNote, Nimbus и другие), но у каждого были свои минусы, и ни один из них не сделал для меня процесс ведения заметок увлекательным и по-настоящему полезным. На их фоне Obsidian имеет ряд преимуществ. Я не стану описывать их все, а упомяну только те, которые подкупили меня: 1. Все заметки хранятся локально в виде markdown-файлов. Этот формат легко прочитать чем угодно – даже Блокнотом, и он универсален для различных операционных систем и типов устройств. Хранение локально позволяет не переживать о сохранности своих данных, а также производить манипуляции с заметками как с обычными текстовыми файлами (например, читать и редактировать с помощью Python-скриптов). 2. Просто начать. «Из коробки» Obsidian предоставляет ограниченный функционал, который немногим богаче упомянутого ранее Блокнота. В отличие от Notion, который отпугнул меня с первых секунд знакомства своим функционалом «комбайна», Obsidian предоставляет пользователю возможность осмотреться, понять, чего ему не хватает, и подключить необходимый функционал, который, скорее всего, уже реализован в ядре Obsidian или силами сообщества (следующий пункт). 3. Обширная коллекция плагинов сообщества. Сообщество пользователей Obsidian не только подскажет ответы на многие вопросы, которые могут возникнуть у новичка, но и создает плагины, привносящие в Obsidian функционал, способный удовлетворить даже самого взыскательного пользователя. Лично я предпочитаю не использовать плагины, которые привносят кардинальные изменения – чтобы не лишаться плюсов, указанных в п.1, но мимо плагина DataView я просто не мог пройти. Я специально не стал упоминать о GraphView – возможности представить свою коллекцию заметок в виде нейроноподобной сети (при условии, что вы связывали сущности в заметках), потому что для меня этот способ отображения информации отошел на второй план после того, как я познакомился с плагином DataView. Однако, должен отметить, что это отличная «фишка», которая впечатляет при первом знакомстве. О том же, как Obsidian позволил мне повысить эффективность, я рассказал в продолжении: https://lnkd.in/damF8b2z. #obsidian #productivity
- Копировать
Чтобы просмотреть или add a comment, выполните вход