nchar и nvarchar (Transact-SQL)
Символьные типы данных имеют фиксированный (nchar) или переменный (nvarchar) размер. Начиная с SQL Server 2012 (11.x) при использовании параметров сортировки с поддержкой дополнительных символов эти типы данных хранят весь диапазон символьных данных Юникод и используют кодировку UTF-16. Если указаны параметры сортировки без поддержки дополнительных символов, эти типы данных хранят только подмножество символьных данных, поддерживаемых кодировкой UCS-2.
Аргументы
nchar [ ( n ) ]
Строковые данные фиксированного размера. n определяет размер строки в парах байтов и должен быть значением от 1 до 4000. Размер хранилища — дважды n байт. В случае с кодировкой UCS-2 размер при хранении определяется как дважды n байт, а количество хранимых символов равно n. Для кодировки UTF-16 размер хранилища по-прежнему составляет два раза n байтов, но количество символов, которые могут быть сохранены, может быть меньше n , так как дополнительные символы используют две пары байтов (также называемые суррогатной парой). Синонимами типа nchar по стандарту ISO являются типы national char и national character.
nvarchar [ ( n | max ) ]
Строковые данные переменного размера. n определяет размер строки в парах байтов и может быть значением от 1 до 4000. Значение max указывает, что максимальный размер при хранении составляет 2^31-1 символов (2 ГБ). Размер при хранении определяется как дважды n байт + 2 байта. В случае с кодировкой UCS-2 размер при хранении определяется как дважды n байт + 2 байта, а количество хранимых символов равно n. Для кодировки UTF-16 размер хранилища по-прежнему составляет 2 байта + 2 байта, но количество символов, которые могут быть сохранены, может быть меньше n, так как дополнительные символы используют две пары байтов (также называемые суррогатной парой). Синонимами типа nvarchar по стандарту ISO являются типы national char varying и national character varying.
Remarks
Распространенное заблуждение заключается в том, что при использовании nchar(n) и nvarchar(n)n определяет количество символов. Однако в nchar(n) и nvarchar(n)n определяет длину строки в парах байтов (0–4000). n никогда не определяет количество хранимых символов. Это аналогично определению char(n) и varchar(n).
Неправильное представление возникает из-за того, что при использовании символов, определенных в диапазоне Юникода от 0 до 65 535, на каждую пару байтов может храниться по одному символу. Однако в более высоких диапазонах Юникода (от 65 536 до 1 114 111) один символ может использовать две пары байтов. Например, в столбце, определенном как nchar(10), компонент Компонент Database Engine может хранить 10 символов, использующих одну пару байтов (диапазон Юникода от 0 до 65 535), но менее 10 символов при использовании двух пар байтов (диапазон Юникода от 65 536 до 1 114 111). Дополнительные сведения о хранении символов Юникода и их диапазонах см. в разделе Различия в хранении UTF-8 и UTF-16.
Если значение n в определении данных или инструкции объявления переменной не указано, длина по умолчанию равна 1. Когда n не указано функцией CAST, длина по умолчанию равна 30.
При использовании nchar или nvarchar рекомендуется:
- использовать nchar, если размеры записей данных в столбцах одинаковые;
- использовать nvarchar, если размеры записей данных в столбцах существенно отличаются;
- использовать nvarchar(max), если размеры записей данных в столбцах существенно отличаются и длина строки может превышать 4000 пар байтов.
sysname — это системный определяемый пользователем тип данных, который функционально эквивалентен nvarchar(128), за исключением того, что он не допускает значения NULL. Тип sysname используется для ссылки на имена объектов баз данных.
Объектам, использующим nchar или nvarchar , назначаются параметры сортировки по умолчанию для базы данных, если только определенные параметры сортировки не назначены с помощью COLLATE предложения .
SET ANSI_PADDING всегда ON для nchar и nvarchar. SET ANSI_PADDING OFF не применяется к типам данных nchar или nvarchar .
Префиксировать символьные строковые константы Юникода буквой N , чтобы сообщить о входных данных UCS-2 или UTF-16 в зависимости от того, используются ли параметры сортировки SC. N Без префикса строка преобразуется в кодовую страницу базы данных по умолчанию, которая может не распознавать определенные символы. Начиная с SQL Server 2019 (15.x), при использовании параметров сортировки с поддержкой UTF-8 кодовая страница по умолчанию может хранить кодировку Юникода UTF-8.
При префиксе строковой константы буквой N неявное преобразование приведет к созданию строки UCS-2 или UTF-16, если преобразуемая константа не превышает максимальную длину для строкового типа данных nvarchar (4000). В противном случае неявное преобразование приведет к большому значению nvarchar(max).
Каждому ненулевому столбцу varchar(max) и nvarchar(max) необходимо дополнительно выделить 24 байта памяти, которые учитываются в максимальном размере строки в 8060 байт во время операции сортировки. Эти дополнительные байты могут неявно ограничивать число ненулевых столбцов varchar(max) или nvarchar(max) в таблице. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Такой большой размер строки может приводить к ошибкам (например, ошибке 512), которые пользователи не ожидают во время обычных операций. Примерами операций могут служить обновление ключа кластеризованного индекса или сортировка полного набора столбцов.
Преобразование символьных данных
Сведения о преобразовании символьных данных см. в статье char и varchar (Transact-SQL).
См. также раздел
- ALTER TABLE (Transact-SQL)
- Функции CAST и CONVERT (Transact-SQL)
- COLLATE (Transact-SQL)
- Инструкция CREATE TABLE (Transact-SQL)
- Типы данных (Transact-SQL)
- DECLARE @local_variable (Transact-SQL)
- LIKE (Transact-SQL)
- SET ANSI_PADDING (Transact-SQL)
- SET @local_variable (Transact-SQL)
- Поддержка параметров сортировки и Юникода
- Однобайтовые и многобайтовые кодировки
varchar(max)-varchar(max) и в продакшн
Недавно поучаствовал в дискуссии на тему влияния на производительность указания длины в столбцах с типом nvarchar. Доводы были разумны у обеих сторон и поскольку у меня было свободное время, решил немного потестировать. Результатом стал этот пост.
Спойлер – не всё так однозначно.
Все тесты проводились на SQL Server 2014 Developer Edition, примерно такие же результаты были получены и на SQL Server 2016 (с небольшими отличиями). Описанное ниже должно быть актуально для SQL Server 2005-2016 (а в 2017/2019 требуется тестирование, поскольку там появились Adaptive Memory Grants, которые могут несколько исправить положение).
Нам понадобятся – хранимая процедура от Erik Darling sp_pressure_detector, которая позволяет получить множество информации о текущем состоянии системы и SQL Query Stress – очень крутая open-source утилита Adam Machanic/Erik Ejlskov Jensen для нагрузочного тестирования MS SQL Server.
О чём вообще речь
Вопрос, на который я стараюсь ответить – влияет ли на производительность выбор длины поля (n)varchar (далее везде просто varchar, хотя всё актуально и для nvarchar), или можно использовать varchar(max) и не париться, поскольку если длина строки < 8000 (4000 для nvarchar) символов, то varchar(max) и varchar(N) хранятся IN-ROW.
Готовим стенд
create table ##v10 (i int, d datetime, v varchar(10)); create table ##v100 (i int, d datetime, v varchar(100)); create table ##vmax (i int, d datetime, v varchar(max));Создаём 3 таблицы из трёх полей, разница только в длине varchar: 10/100/max. И заполним их одинаковыми данными:
;with x as (select 1 x union all select 1) , xx as (select 1 x from x x1, x x2) , xxx as (select 1 x from xx x1, xx x2, xx x3) , xxxx as ( select row_number() over(order by (select null)) i , dateadd(second, row_number() over(order by (select null)), '20200101') d , cast (row_number() over(order by (select null)) as varchar(10)) v from xxx x1, xxx x2, xxx x3 ) --262144 строк insert into ##v10 --varchar(10) select i, d, v from xxxx; insert into ##v100 --varchar(100) select i, d, v from ##v10; insert into ##vmax --varchar(max) select i, d, v from ##v10; В итоге каждая таблица будет содержать 262144 строк. Столбец I (integer) содержит неповторяющиеся числа от 1 до 262145; d (datetime) уникальные даты и v (varchar) – cast (I as varchar(10)). Чтобы это было чуть больше похоже на реальную жизнь, создаём уникальный кластерный индекс по i:
create unique clustered index #cidx10 on ##v10(i); create unique clustered index #cidx100 on ##v100(i); create unique clustered index #cidxmax on ##vmax(i);Поехали
Сначала посмотрим планы выполнения разных запросов.
Во-первых, проверим, что отбор по полю varchar не зависит от его длины (если там хранится < 8000 символов). Включаем действительный план выполнения и смотрим:
select * from ##v10 where v = '123'; select * from ##v100 where v = '123'; select * from ##vmax where v = '123';
Как ни странно, разница, хоть и небольшая, но есть. План запроса с varchar(max) сначала выбирает все строки, а потом их отфильтровывает, а varchar(10) и varchar(100) проверяют совпадения при сканировании кластерного индекса. Из-за этого, сканирование занимает практически в 3 раза больше времени – 0,068 секунд против 0.022 у varchar(10).
Теперь посмотрим, что будет, если просто выводить varchar-колонку, а отбирать данные по ключу кластерного индекса:
select * from ##v10 where i between 200000 and 201000; select * from ##v100 where i between 200000 and 201000; select * from ##vmax where i between 200000 and 201000; 
Тут всё понятно – для таких запросов никакой разницы нет.
Теперь интересная часть. Предыдущим запросом мы получили всего-то 1001 строку, а теперь хотим отсортировать их по неиндексированной колонке. Пробуем:
select * from ##v10 where i between 200000 and 201000 order by d; select * from ##v100 where i between 200000 and 201000 order by d; select * from ##vmax where i between 200000 and 201000 order by d;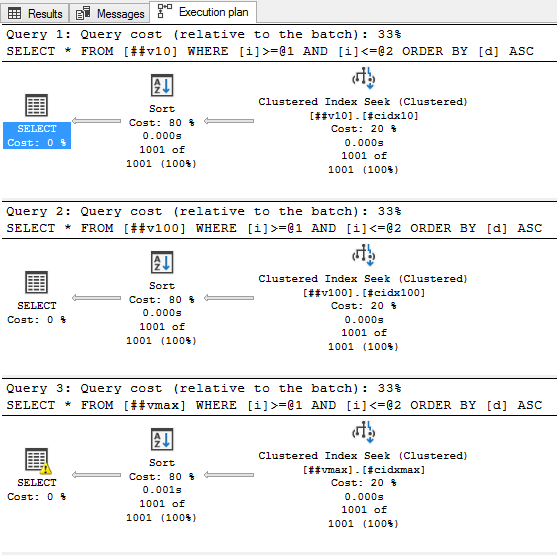
Ой, а что там такое жёлтенькое?
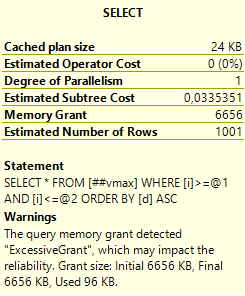
Забавно, т.е. запрос запросил и получил 6,5 мегабайт оперативной памяти для сортировки, а использовал только 96 килобайт. А насколько будет хуже, если строк будет побольше. Ну, пусть будет не 1000, а 100000:
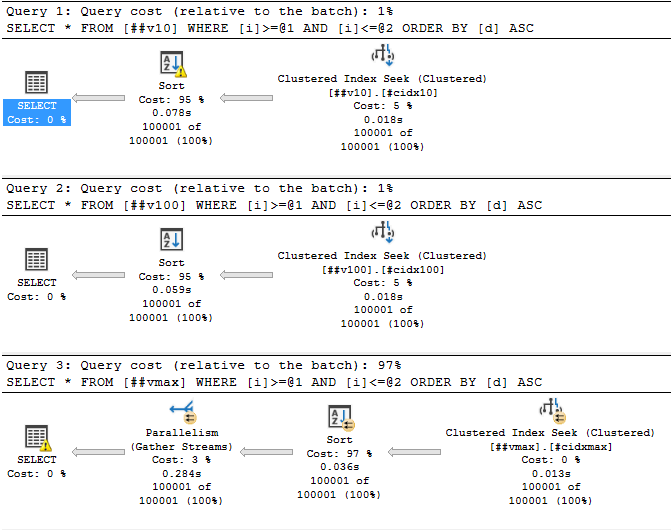
А вот тут уже посерьёзнее. Причём первый запрос, который работает с самым маленьким varchar(10) тоже чем-то недоволен:
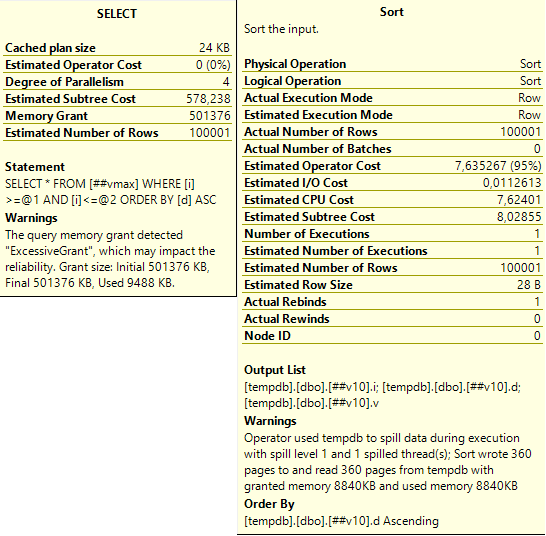
Слева тут предупреждение последнего запроса: запрошено 500 мегабайт, а использовано всего 9,5 мегабайт. А справа – предупреждение сортировки: запрошено было 8840 килобайт, но их не хватило и ещё 360 страниц (по 8 кб) было записано и прочитано из tempdb.
И тут напрашивается вопрос: WTF?
Ответ – так работает оптимизатор запросов SQL Server. Чтобы что-то отсортировать, это что-то нужно сначала поместить в память. Как понять сколько памяти нужно? Вообще, нам известно сколько какой тип данных занимает места. А что же со строками переменной длины? А вот с ними интереснее. При выделении памяти для сортировок/hash join, SQL Server считает, что в среднем они заполнены наполовину. И выделяет под них память как (размер / 2) * ожидаемое количество строк. Но varchar(max) может хранить аж 2Гб – сколько же выделять? SQL Server считает, что там будет половина от varchar(8000) – т.е. примерно 4 кб на строку.
Что интересно – такое выделение памяти приводит к проблемам не только с varchar(max) – если размер ваших varchar’ов любовно подобран так, что большая часть из них заполнена наполовину и больше – это тоже ведёт к проблемам. Проблемам иного плана, но не менее серьёзным. На рисунке выше есть описание – SQL Server не смог корректно выделить память для сортировки маленького varchar’а и использовал tempdb для хранения промежуточных результатов. Если tempdb лежит на медленных дисках, или активно используется другими запросами – это может стать очень узким местом.
SQL Query Stress
Теперь посмотрим, что происходит при массовом выполнении запросов. Запустим SQL Query Stress, подключим его к нашему серверу, и скажем выполнить все эти запросы по 10 раз в 50 потоках.
Результаты выполнения первого запроса:
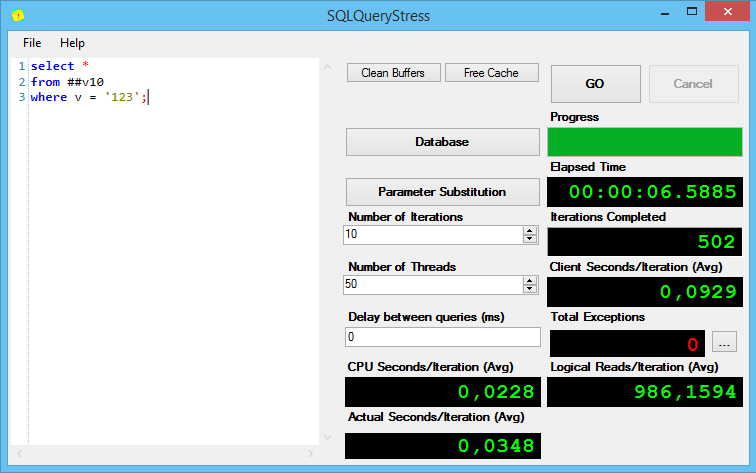
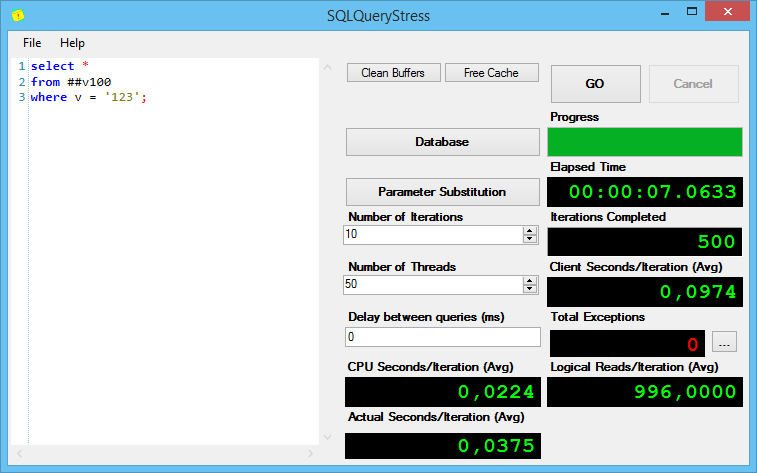
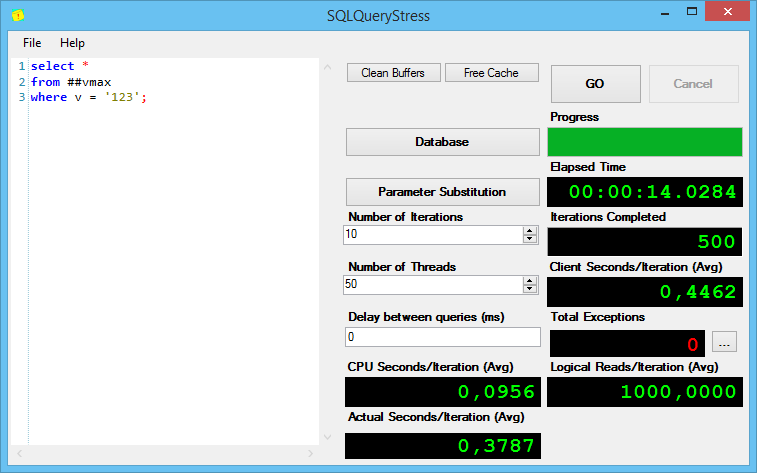
Интересно, но без индексов, при поиске varchar(max) показывает себя хуже всех, причём солидно так хуже по процессорному времени на итерацию и общему времени выполнения.
sp_pressure_detector не показывает тут ничего интересного, поэтому её вывод не привожу.
Результаты выполнения второго запроса:
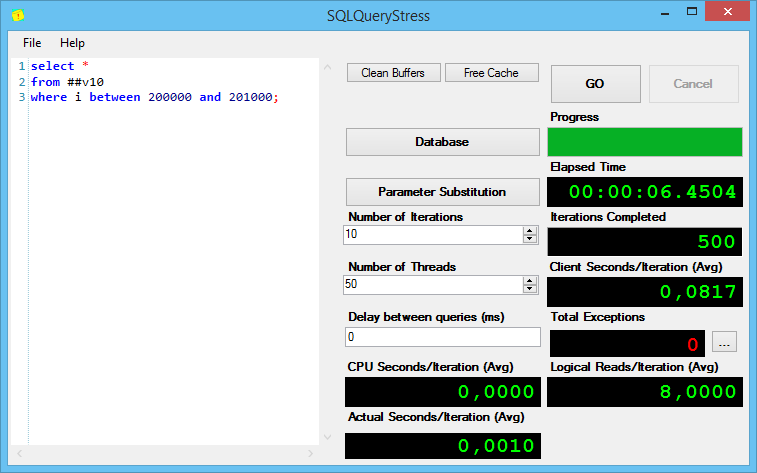
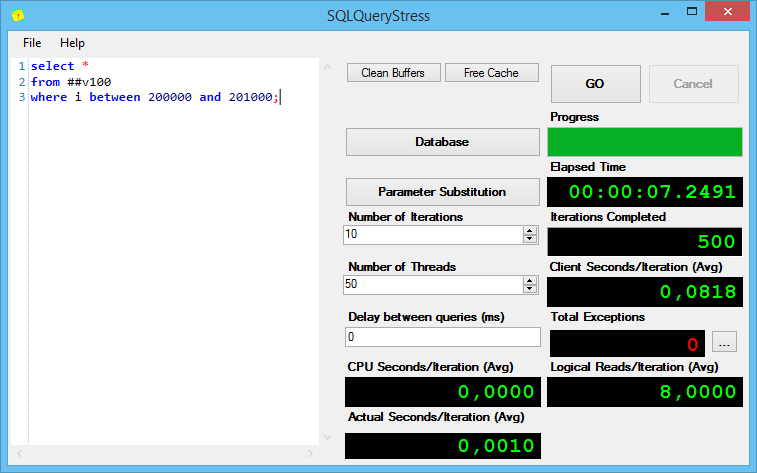

Тут всё ожидаемо – одинаково хорошо.
Теперь интересная часть. Запрос с сортировкой полученной тысячи строк:

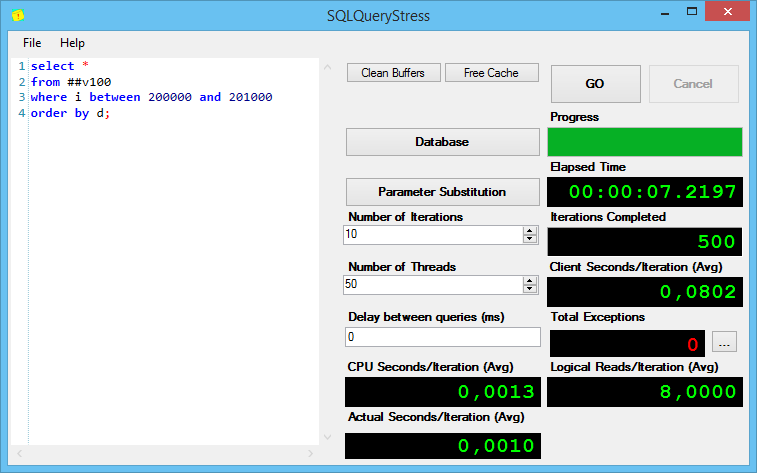
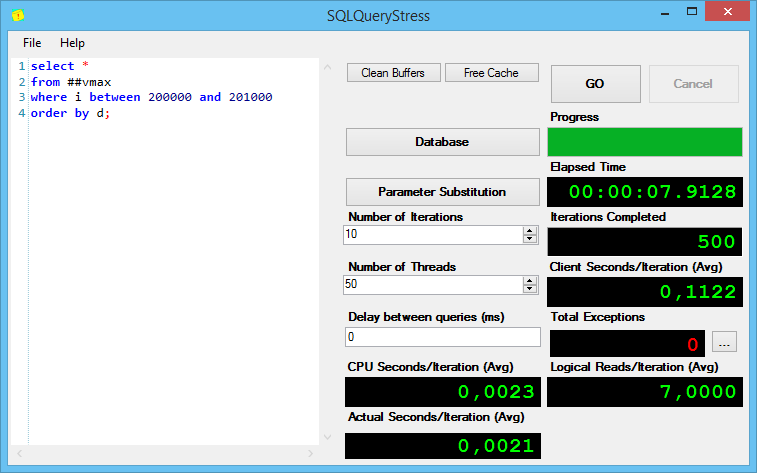
Тут всё оказалось точно также, как и с предыдущим запросом – строк не много, сортировка проблем не вызывает.
Теперь последний запрос, который сортирует неоправданно много строк (я добавил в него top 1000, чтобы не тянуть весь сортированный список):

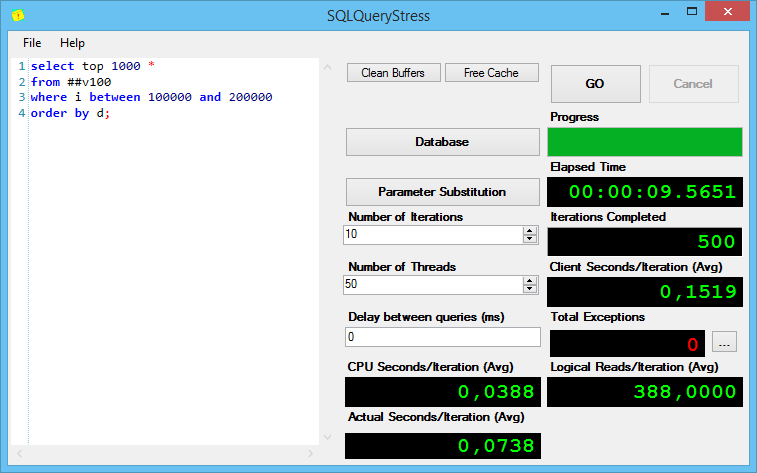
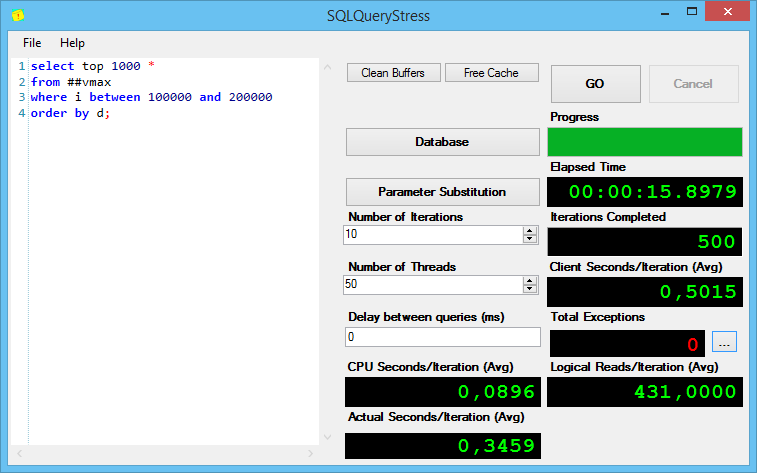
И вот тут привожу вывод sp_pressure_detector:

Что он нам говорит? Все сессии запрашивают по 489 МБ (на сортировку), но только на 22 из них SQL Server’у хватило памяти, даже учитывая, что используют все эти 22 сессии всего по 9 МБ!
Всего доступно 11 Гб памяти, 22 сессиям было выделено по 489.625 и у SQL Server’a осталось всего-то 258 доступных мегабайт, а новые сессии тоже хотят получить по 489. Что делать? Ждать, пока освободится память – они и ждут, даже не начиная выполняться. Что будут делать пользователи, если в их сессиях выполняются такие запросы? Тоже ждать.
Кстати, обратите внимание на рисунок с varchar(10) – запросы с varchar(10) выполнялись дольше, чем запросы с varchar(100) – и это при том, что у меня tempdb на очень быстром диске. Чем хуже диск под tempdb – тем медленнее будет выполняться запрос.
Отдельное примечание для SQL Server 2012/2014
В SQL Server 2012/2014 есть ещё одна забавная шутка с sort spills. Даже если вы используете тип char/nchar – это не гарантирует отсутствие spill’ов в tempdb. MS признала проблему в оптимизаторе, когда он выделял слишком мало памяти для сортировки, даже если количество строк было оценено верно.
create table ##c6 (i int, d datetime, v char(6)); insert into ##c6 (i, d, v) select i, d, v from ##v10 select * from ##c6 where i between 100000 and 200000 order by d;
Включаем документированный флаг трассировки (НЕ ДЕЛАЙТЕ ЭТОГО НА ПРОДЕ БЕЗ НЕОБХОДИМОСТИ):
DBCC TRACEON (7470, -1);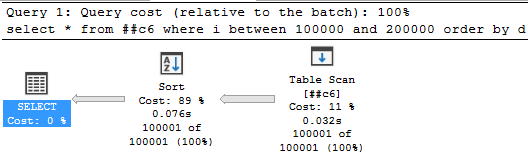
Восклицательный знак у сортировки пропал, spill’а больше нет.
Выводы
С осторожностью используйте сортировку в своих запросах, там где у вас есть колонки (n)varchar. Если сортировка всё же нужна, крайне желательно, чтобы по колонке сортировки был индекс.
Учтите, что чтобы получить сортировку совсем необязательно явно использовать order by – её появление возможно и при merge join’ах, например. Та же проблема с выделением памяти возможна и при hash join’ах, например, вот с varchar(max):
select top 100 * from ##vmax v1 inner hash join ##v10 v2 on v1.i = v2.i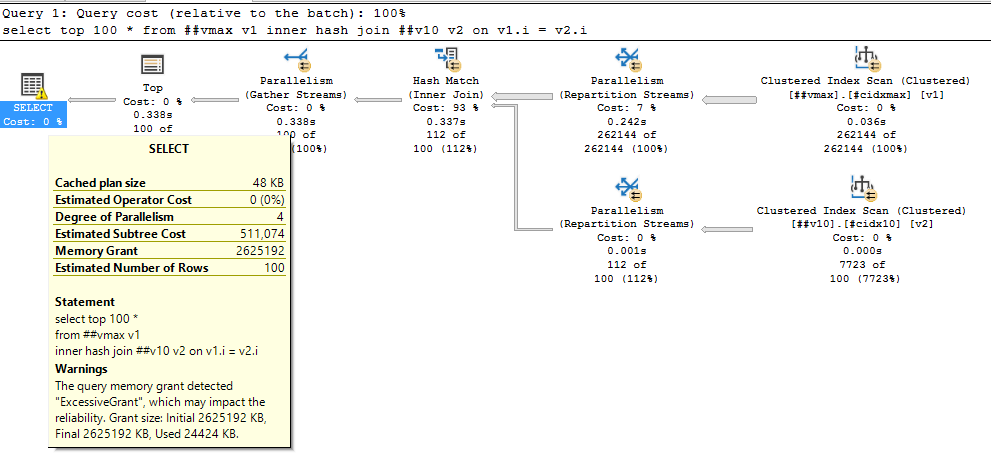
Выделено 2.5 ГИГАБАЙТА памяти, используется 25 мегабайт!
Главный для меня вывод: размер колонки (n)varchar – ВАЖЕН! Если размер слишком маленький – возможны spill’ы в tempdb, если слишком большой – возможны слишком большие запросы памяти. При наличии сортировок разумным будет объявлять длину varchar как средняя длина записи * 2, а в случае SQL Server 2012/2014 — даже больше.
Неожиданный для меня вывод: varchar(max), содержащий меньше 8000 символов, реально работает медленнее, при фильтрах по нему. Пока не знаю как это объяснить — буду копать ещё.
Бонусный вывод для меня: уже почти нажав «опубликовать» я подумал, что ведь и с varchar(max) можно испытать проблему «маленького varchar’a». И правда, при хранении в varchar(max) больше чем 4000 символов (2000 для nvarchar) — сортировки могут стать проблемой.
insert into ##vmax(i, d, v) select i, d, replicate('a', 4000) v from ##v10; select * from ##vmax where i between 200000 and 201000 order by d; 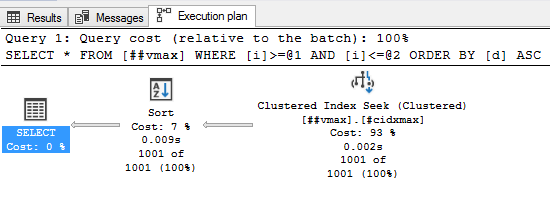
truncate table ##vmax; insert into ##vmax(i, d, v) select i, d, replicate('a', 4100) v from ##v10; select * from ##vmax where i between 200000 and 201000 order by d;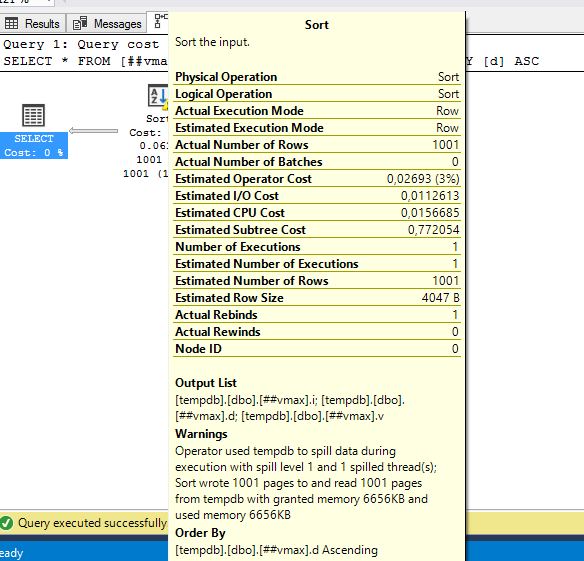
Почему в самом начале я написал, что не всё так однозначно? Потому что, например, на моём домашнем ноуте с полумёртвым диском, spill’ы в tempdb при сортировке «маленьких» varchar приводили к тому, что такие запросы выполнялись на ПОРЯДКИ медленнее, чем аналогичные запросы с varchar(max). Если у вас хорошее железо, возможно, они не станут такой проблемой, но забывать о них не стоит.
Что было бы ещё интересно — посмотреть есть ли какие-то проблемы из-за слишком больших/маленьких размеров varchar’ов в других СУБД. Если у вас есть возможность проверить — буду рад, если поделитесь.
Маленький бонус
Отловить такие проблемы с помощью кэша планов запросов, к сожалению, не получится. Вот примеры планов из кэша: никаких предупреждений в них, увы, нет.
Типы char и varchar (Transact-SQL)
Символьные типы данных имеют фиксированный (char) или переменный (varchar) размер. Начиная с SQL Server 2019 (15.x) при использовании параметров сортировки с поддержкой UTF-8 эти типы данных хранят весь диапазон символьных данных Юникод и используют кодировку UTF-8. Если указаны параметры сортировки без поддержки UTF-8, эти типы данных хранят только подмножество символьных данных, поддерживаемых соответствующей кодовой страницей указанных параметров сортировки.
Аргументы
char [ ( n ) ]
Строковые данные фиксированного размера. n определяет размер строки в байтах и должно иметь значение от 1 до 8000. Для наборов символов однобайтовой кодировки, таких как Latin , размер хранилища равен n байтам, а количество символов, которые можно хранить, также равно n. Для многобайтовых кодировок размер при хранения тоже равен n байт, но количество хранимых символов может быть меньше n. Синонимом по стандарту ISO для типа char является character. Дополнительные сведения о кодировках см. в статье Однобайтовые и многобайтовые кодировки.
varchar [ ( n | max ) ]
Строковые данные переменного размера. Используйте n для определения размера строки в байтах и может быть значением от 1 до 8 000 или использовать максимальное значение, чтобы указать размер ограничения столбца до максимального объема хранилища 2^31-1 байт (2 ГБ). Для наборов символов кодировки с одним байтом, например Latin , размер хранилища равен n байтам + 2 байтам, а количество символов, которые можно сохранить, также равно n. Для многобайтовых кодировок размер при хранения тоже равен n байт + 2 байта, но количество хранимых символов может быть меньше n. Синонимы ISO для varchar являются разными или символьными. Дополнительные сведения о кодировках см. в статье Однобайтовые и многобайтовые кодировки.
Замечания
Распространенное заблуждение заключается в том, чтобы думать, что с char(n) и varchar(n), n определяет количество символов. Однако в char(n) и varchar(n) n определяет длину строки в байтах (от 0 до 8 000). n никогда не определяет количество хранимых символов. Это аналогично определению nchar(n) и nvarchar(n).
Неправильное представление происходит, так как при использовании однобайтовой кодировки размер хранилища char и varchar составляет n байтов, а число символов также равно n. Однако для многобайтовой кодировки, например UTF-8, более высокие диапазоны Юникода (от 128 до 114 111) приводят к одному символу с использованием двух или более байтов. Например, в столбце, определенном как char(10), ядро СУБД может хранить 10 символов, использующих однобайтовое кодирование (диапазон Юникода от 0 до 127), но менее 10 символов при использовании многобайтовой кодировки (диапазон Юникода от 128 до 114 111). Дополнительные сведения о хранении символов Юникода и их диапазонах см. в разделе Различия в хранении UTF-8 и UTF-16.
Если значение n в определении данных или инструкции объявления переменной не указано, длина по умолчанию равна 1. Если n не указан при использовании CAST и CONVERT функциях, длина по умолчанию составляет 30.
Объекты, использующие char или varchar , назначаются параметры сортировки по умолчанию базы данных, если только не назначено определенное параметры сортировки с помощью COLLATE предложения. Параметры сортировки контролируют кодовую страницу, используемую для хранения символьных данных.
Многобайтовые кодировки в SQL Server включают следующие:
- двухбайтовые кодировки (DBCS) для некоторых языков Восточной Азии, использующих кодовые страницы 936 и 950 (китайский), 932 (японский) или 949 (корейский).
- UTF-8 с кодовой страницей 65001. Область применения: SQL Server 2019 (15.x) и более поздних версий.
Если у вас есть сайты, поддерживающие несколько языков, примите к сведению следующие рекомендации:
- Для поддержки Юникода и минимизации проблем с преобразованием символов рекомендуем использовать параметры сортировки с поддержкой UTF-8 (начиная с SQL Server 2019 (15.x)).
- Если используется предыдущая версия SQL Server ядро СУБД, рекомендуется использовать типы данных Юникод nchar или nvarchar, чтобы свести к минимуму проблемы с преобразованием символов.
Если вы используете char или varchar, рекомендуется:
- Если размеры записей данных столбцов постоянны, используйте char.
- Если размеры записей данных столбцов значительно изменяются, используйте varchar.
- использовать varchar(max), если размеры записей данных в столбцах существенно отличаются и длина строки может превышать 8000 байт.
Если SET ANSI_PADDING выполняется OFF либо CREATE TABLE ALTER TABLE выполняется, столбец char, определенный как NULL, обрабатывается как varchar.
Для каждого столбца varchar(max) или nvarchar(max) требуется 24 байта дополнительного фиксированного выделения, которое подсчитывает ограничение строки 8060 байтов во время операции сортировки. Это может неявно ограничивать число ненулевых столбцов varchar(max) или nvarchar(max), которые могут быть созданы в таблице.
При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Такой размер строки может вызывать ошибки (например, ошибку 512) во время некоторых обычных операций, таких как обновление ключа кластеризованного индекса, или сортировки полного набора столбцов, которая происходит только во время выполнения операции.
Преобразование символьных данных
При преобразовании символьного выражения в символьный тип данных другой длины значения, слишком длинные для нового типа данных, усекаются. Тип uniqueidentifier считается символьным типом, используемым при преобразовании из символьного выражения, поэтому на него распространяются правила усечения при преобразовании в символьный тип. См. раздел «Примеры».
Если символьное выражение преобразуется в символьное выражение другого типа данных или размера, например из char(5) в varchar(5) или из char(20) в char(15), то преобразованному значению присваиваются параметры сортировки входного значения. Если несимвольное выражение преобразуется в символьный тип данных, то преобразованному значению присваиваются параметры сортировки, заданные по умолчанию в текущей базе данных. В любом случае необходимые параметры сортировки можно присвоить с помощью предложения COLLATE.
Преобразования страниц кода поддерживаются для типов данных char и varchar, но не для текстового типа данных. Как и в ранних версиях SQL Server, о потере данных во время преобразования кодовых страниц не сообщается.
Символьные выражения, которые преобразуются в приближенный тип данных numeric, могут содержать необязательную экспоненциальную нотацию Это нотация является строчным или верхним регистром e E , за которым следует необязательный знак плюс ( + ) или минус ( — ), а затем число.
Символьные выражения, которые преобразуются в точный числовый тип данных, должны состоять из цифр, десятичной запятой и необязательного плюса ( + ) или минуса ( — ). Начальные пробелы не учитываются. Разделители запятой, такие как разделитель 123,456.00 тысяч, не допускаются в строке.
Символьные выражения, преобразованные в типы данных money или smallmoney , также могут включать необязательный десятичный знак и знак доллара ( $ ). Разделители запятой, как и в $123,456.00 , разрешены.
Когда пустая строка преобразуется в int, его значение становится 0 . Когда пустая строка преобразовывается в дату, ее значением становится значение даты по умолчанию, то есть 1900-01-01 .
Примеры
А. Отображение значения по умолчанию n при использовании в объявлении переменной
В следующем примере показано значение по умолчанию n равно 1 для типов данных char и varchar , когда они используются в объявлении переменной.
DECLARE @myVariable AS VARCHAR = 'abc'; DECLARE @myNextVariable AS CHAR = 'abc'; --The following returns 1 SELECT DATALENGTH(@myVariable), DATALENGTH(@myNextVariable); GO B. Отображение значения по умолчанию n при использовании varchar с CAST и CONVERT
В следующем примере показано, что значение по умолчанию n равно 30, если типы данных char или varchar используются с CAST и CONVERT функциями.
DECLARE @myVariable AS VARCHAR(40); SET @myVariable = 'This string is longer than thirty characters'; SELECT CAST(@myVariable AS VARCHAR); SELECT DATALENGTH(CAST(@myVariable AS VARCHAR)) AS 'VarcharDefaultLength'; SELECT CONVERT(CHAR, @myVariable); SELECT DATALENGTH(CONVERT(CHAR, @myVariable)) AS 'VarcharDefaultLength'; C. Преобразование данных для отображения
В следующем примере два столбца преобразуются в символьные типы, после чего к ним применяется стиль, применяющий к отображаемым данным конкретный формат. Тип денег преобразуется в символьные данные и стиль 1 , который отображает значения с запятыми каждые три цифры слева от десятичной точки и две цифры справа от десятичной запятой. Тип даты и времени преобразуется в символьные данные и стиль 3 , который отображает данные в формате dd/mm/yy . WHERE В предложении тип денег привязывается к типу символов для выполнения операции сравнения строк.
USE AdventureWorks2022; GO SELECT BusinessEntityID, SalesYTD, CONVERT (VARCHAR(12),SalesYTD,1) AS MoneyDisplayStyle1, GETDATE() AS CurrentDate, CONVERT(VARCHAR(12), GETDATE(), 3) AS DateDisplayStyle3 FROM Sales.SalesPerson WHERE CAST(SalesYTD AS VARCHAR(20) ) LIKE '1%'; BusinessEntityID SalesYTD DisplayFormat CurrentDate DisplayDateFormat ---------------- --------------------- ------------- ----------------------- ----------------- 278 1453719.4653 1,453,719.47 2011-05-07 14:29:01.193 07/05/11 280 1352577.1325 1,352,577.13 2011-05-07 14:29:01.193 07/05/11 283 1573012.9383 1,573,012.94 2011-05-07 14:29:01.193 07/05/11 284 1576562.1966 1,576,562.20 2011-05-07 14:29:01.193 07/05/11 285 172524.4512 172,524.45 2011-05-07 14:29:01.193 07/05/11 286 1421810.9242 1,421,810.92 2011-05-07 14:29:01.193 07/05/11 288 1827066.7118 1,827,066.71 2011-05-07 14:29:01.193 07/05/11 D. Преобразование данных uniqueidentifer
В следующем примере значение uniqueidentifier преобразуется в тип данных char.
DECLARE @myid uniqueidentifier = NEWID(); SELECT CONVERT(CHAR(255), @myid) AS 'char'; Следующий пример показывает усечение данных, когда значение является слишком длинным для преобразования в заданный тип данных. Так как тип данных uniqueidentifier ограничен 36 символами, все символы, выходящие за пределы этой длины, будут усечены.
DECLARE @ID NVARCHAR(max) = N'0E984725-C51C-4BF4-9960-E1C80E27ABA0wrong'; SELECT @ID, CONVERT(uniqueidentifier, @ID) AS TruncatedValue; String TruncatedValue -------------------------------------------- ------------------------------------ 0E984725-C51C-4BF4-9960-E1C80E27ABA0wrong 0E984725-C51C-4BF4-9960-E1C80E27ABA0 (1 row(s) affected) См. также
- nchar и nvarchar (Transact-SQL)
- CAST и CONVERT (Transact-SQL)
- COLLATE (Transact-SQL)
- Преобразование типов данных (ядро СУБД)
- Типы данных (Transact-SQL)
- Оценка размера базы данных
- Поддержка параметров сортировки и Юникода
- Однобайтовые и многобайтовые кодировки
Размер строки влияет на производительность SQL Server


24 Мая 2016 Программирование  3
3  0
0
В MS SQL Server ты можешь создавать поля типа varchar(max) и с точки зрения производительности это чуть лучше, чем text. Если размер текста в поле меньше 8k, то сервер будет пытаться сохранить его вместе с остальными данным в той же странице. Если больше 8 кило, то данные точно уйдут в отдельное хранилище, что отрицательно скажется на производительности, если массово выбирать данные.
Обычно для запросов, которые возвращают данные для сеток или списков данных, не нужно возвращать текстовые поля. Трудно представить себе сетку, где будет большой текст. Разве что блоги. Например, у меня запись блога состоит из двух текстовых полей — первое показывается в списке, а второе, когда вы открываете саму статью. Не знаю как MySQL, но в MS SQL Server эти текстовые поля притормаживали бы запросы.
За счёт того, что я показываю на блоге записи постранично, максимум 10 записей на странице, то потри не смертельны, но на нагрузке на сервер это все же сказывается. Для сайтов с большим трафиком я бы все же сделал поле Intro, которое у меня отображается в списке не текстовым, а varchar. 1000 символов должно хватить с головой. Главное не выполнять запросов типа SELECT *, но к сожалению этим грешат многие программисты. Да и я сам такой же.
Об этом поведении я знал уже давно и я стараюсь использовать такие большие стоки только когда это действительно необходимо. Но на этой неделе я работал над тормозным запросом, у которого были все необходимые индексы, но он выполнился 12 секунд. Ну да, он возвращал 17 тысяч строк, но все равно 12 секунд это много.
Я потратил целый день на этот запрос и в шоке узнал, что проблемой были nvarchar поля размером в 512 символов. Причём эта таблица была совершенно пустая. Я попробовал обновить статистику, перестроить индексы, но ничего не помогало. Хотя какую статистику обновлять на пустой таблице? Я обновил статистику на все таблицы — не помогло. Причём план выполнения не показывает, что вина именно в этой пустой таблице, он показывает, что данные тормозят в Worktable, где обрабатываются данные с нескольких таблиц.
Просто для прикола — создаю копию этой таблицы, но запрос все равно тормозит. Создаю ещё одну копию, но на этот раз измеряю размер полей с 512 символов на 112. Скорость выполнения взлетает и запрос работает уже не 12 секунд, а 3 секунды. Попробовал с таблицей с размером полей в 200 символов и запрос снова начал тормозить.
Очень странно, я надеялся, что оптимизатор SQL сервера увидит, что таблица пустая и не будет тупить. Хотя. В чем то это даже хорошо, ведь это у меня она пустая, а на рабочем сервере пользователи могут занести туда данные и потом вычисляй в чем проблема.
В общем, с удивлением узнал, что даже при пересечении границы размера поля в 200 символов, SQL Server может начать тормозить, причем очень сильно. До этого не сталкивался с такой проблемой.
Понравилось? Кликни Лайк, чтобы я знал, какой контент более интересен читателям. Заметку пока еще никто не лайкал и ты можешь быть первым