Как строить красивые графики на Python с Seaborn
Визуализация данных — это метод, который позволяет специалистам по анализу данных преобразовывать сырые данные в диаграммы и графики, которые несут ценную информацию. Диаграммы уменьшают сложность данных и делают более понятными для любого пользователя.
Есть множество инструментов для визуализации данных, таких как Tableau, Power BI, ChartBlocks и других, которые являются no-code инструментами. Они очень мощные, и у каждого своя аудитория. Однако для работы с сырыми данными, требующими обработки, а также в качестве песочницы, Python подойдет лучше всего.
Несмотря на то, что этот путь сложнее и требует умения программировать, Python позволит вам провести любые манипуляции, преобразования и визуализировать ваши данные. Он идеально подходит для специалистов по анализу данных.
Python — лучший инструмент для data science и этому много причин, но самая важная — это его экосистема библиотек. Для работы с данными в Python есть много замечательных библиотек, таких как numpy , pandas , matplotlib , tensorflow .
Matplotlib , вероятно, самая известная библиотека для построения графиков, которая доступна в Python и других языках программирования, таких как R. Именно ее уровень кастомизации и удобства в использовании ставит ее на первое место. Однако с некоторыми действиями и кастомизациями во время ее использования бывает справиться нелегко.
Разработчики создали новую библиотеку на основе matplotlib , которая называется seaborn . Seaborn такая же мощная, как и matplotlib , но в то же время предоставляет большую абстракцию для упрощения графиков и привносит некоторые уникальные функции.
В этой статье мы сосредоточимся на том, как работать с seaborn для создания первоклассных графиков. Если хотите, можете создать новый проект и повторить все шаги или просто обратиться к моему руководству по seaborn на GitHub.
Что такое Seaborn?
Seaborn — это библиотека для создания статистических графиков на Python. Она основывается на matplotlib и тесно взаимодействует со структурами данных pandas.
Архитектура Seaborn позволяет вам быстро изучить и понять свои данные. Seaborn захватывает целые фреймы данных или массивы, в которых содержатся все ваши данные, и выполняет все внутренние функции, нужные для семантического маппинга и статистической агрегации для преобразования данных в информативные графики.
Она абстрагирует сложность, позволяя вам проектировать графики в соответствии с вашими нуждами.
Установка Seaborn
Установить seaborn так же просто, как и любую другую библиотеку, для этого вам понадобится ваш любимый менеджер пакетов Python. Во время установки seaborn библиотека установит все зависимости, включая matplotlib , pandas , numpy и scipy .
Давайте уже установим seaborn и, конечно же, также пакет notebook , чтобы получить доступ к песочнице с данными.
pipenv install seaborn notebookПомимо этого, перед началом работы давайте импортируем несколько модулей.
import seaborn as sns import pandas as pd import numpy as np import matplotlibСтроим первые графики
Перед тем, как мы начнем строить графики, нам нужны данные. Прелесть seaborn в том, что он работает непосредственно с объектами dataframe из pandas , что делает ее очень удобной. Более того, библиотека поставляется с некоторыми встроенными наборами данных, которые можно использовать прямо из кода, и не загружать файлы вручную.
Давайте посмотрим, как это работает на наборе данных о рейсах самолетов.
flights_data = sns.load_dataset("flights") flights_data.head()Визуализация в Python. Seaborn
Для демонстрации визуализации данных при помощи библиотеки Seaborn будем использовать таблицу bank.csv, взятую из открытых источников, и доработанную мной для демонстрации возможностей нашей библиотеки.
Рассмотрим решение некоторых задач при помощи Seaborn:
1. Импортируем нужные библиотеки:
import pandas as pd from matplotlib import pyplot as plt import seaborn as sns
2. При помощи библиотеки Pandas открываем нужную таблицу
bank_data = pd.read_csv(‘C:/bank.csv’,delimiter=’,’) bank_data.head(S)
3. Количество записей и столбцов можно узнать при помощи функции »shape» из Pandas. В представленных банковских данных 4521 строка и 17 столбцов
bank_data.shape
4. При помощи функции »describe», все из той же Pandas, можно получить подробную информацию о столбцах, таких как: количество, среднее, минимальное и максимальное значения
bank_data.describe()
Из результатов, полученных при помощи оговоренной ранее функции, можно сделать ряд выводов:
- Минимальный возраст равен 19 лет, максимальный 87 лет, а средний возраст клиентов составляет 41 год;
- Минимальный баланс составляет -3313, максимальный 71188, а средний 1422,66;
- Максимальная продолжительность взаимодействия с клиентом длилась 3025 секунд, а минимальное время равняется 4 секундам;
- В рамках одного договора максимальное взаимодействие с клиентом равно 50, минимальное 1.
Далее будем визуализировать имеющиеся данные, а также рассмотрим, как некоторые столбцы соотносятся с целевым столбцом.
1. Соотношение баланса и взятых кредитов, среди клиентов с балансом от 0 до 1400, больше тех, кто не подали заявку на кредит, чем тех, кто это сделал
sns.set_style(‘whitegrid’) plt.figure(figsize = (14,7)) sns.barplot(bank_data[‘loan’], y = bank_data[‘balance’])
2. Из следующей диаграммы можно понять, что больше клиентов заключили договор на кредит, при этом с ними связывались 3 раза.
sns.set_style(‘whitegrid’) plt.figure(figsize = (14,7)) sns.barplot(x = bank_data[‘loan’], y = bank_data[‘campaign’])
Теперь рассмотрим работу с данными, которые представляют из себя категории. Для большего понимания они приведены ниже.
1. Из диаграмм, приведенных ниже, можно сделать вывод, что люди, занимающие руководящие должности, заключили договор на кредит в большем количестве относительно остальных.
sns.set_style(‘whitegrid’) plt.figure(figsize = (14,7)) sns.countplot(bank_data[‘job’])
2. Из диаграммы, приведенной далее, можно сделать вывод, что среди заключивших договор на кредит больше людей состоящих в браке, чем одиноких или с неизвестным семейным положением.
sns.set_style(‘whitegrid’) plt.figure(figsize = (14,7)) sns.countplot(bank_data[‘marital’])
3. В кредитовании в большей степени участвовали люди со средним образованием.
Топ-10 библиотек Python для Data Science
Уже довольно давно Python очаровывает ученых, занимающихся данными. Чем больше я взаимодействую с ресурсами, литературой, курсами, тренингами и людьми в науке о данных, тем более глубокие знания Python приобретаю. При этом, когда я только начинал развивать свои навыки Python, у меня был целый список библиотек, о которых мне предстояло узнать. И вот, через некоторое время.
Специалисты в области Data Science точно знают о библиотеках Python, которые можно использовать в науке о данных, но когда в интервью просят назвать их или указать их функцию, мы часто попадаем впросак или, возможно, не помним более 5 библиотек (это случилось со мной: / )
Сегодня я подготовил список из 10 библиотек Python, которые помогают в области Data Science, когда их использовать, каковы их особенности и преимущества.
В этой статье я кратко изложил 10 наиболее полезных библиотеках Python для data scientist’ов и инженеров, основываясь на моем недавнем опыте и исследованиях. Читайте статью до конца, чтобы узнать о 4 бонусных библиотеках!
1. Pandas
Pandas — это пакет Python с открытым исходным кодом, который предоставляет высокоэффективные, простые в использовании структуры данных и инструменты анализа для помеченных данных на языке программирования Python. Pandas расшифровывается как библиотека анализа данных Python. Кто-нибудь знал об этом?
Когда использовать? Pandas — это идеальный инструмент для обработки данных. Он предназначен для быстрой и простой обработки данных, чтения, агрегирования и визуализации.
Pandas берет данные в файле CSV или TSV или базу данных SQL и создает объект Python со строками и столбцами, который называется фреймом данных. Фрейм данных очень похож на таблицу в статистическом программном обеспечении, скажем, в Excel или SPSS.
Что можно делать с помощью Pandas?
1. Индексирование, манипулирование, переименование, сортировка, объединение фрейма данных;
2. Обновить, добавить, удалить столбцы из фрейма данных;
3. Восстановить недостающие файлы, обработать недостающие данные или NAN;
4. Построить гистограмму или прямоугольную диаграмму.
Это делает Pandas фундаментальной библиотекой в изучении Python для Data Science. Если вам интересно узнать 10 приемов Python Pandas, которые сделают вашу работу более эффективной, читайте нашу статью.
2. NumPy
NumPy — один из самых фундаментальных пакетов в Python — универсальный пакет для обработки массивов. Он предоставляет высокопроизводительные объекты многомерных массивов и инструменты для работы с массивами. NumPy — это эффективный контейнер универсальных многомерных данных.
Основной объект NumPy — это однородный многомерный массив. Это таблица элементов или чисел одного и того же типа данных, проиндексированная набором натуральных чисел. В NumPy размеры называются осями, а число осей называется рангом. Класс массива NumPy называется ndarray, он же array.
Когда использовать? NumPy используется для обработки массивов, в которых хранятся значения одного и того же типа данных. NumPy облегчает математические операции над массивами и их векторизацию. Это значительно повышает производительность и, соответственно, ускоряет время выполнения.
Что можно делать с помощью NumPy?
1. Основные операции с массивами: добавление, умножение, срез, выравнивание, изменение формы, индексирование массивов;
2. Расширенные операции с массивами: стековые массивы, разбиение на секции, широковещательные массивы;
3. Работа с DateTime или линейной алгеброй;
4. Основные нарезки и расширенное индексирование в NumPy Python.
О 4 приемах Python NumPy, которые должен знать каждый новичок, читайте здесь.
3. SciPy
Библиотека SciPy является одним из ключевых пакетов, которые составляют стек SciPy. Теперь есть разница между SciPy Stack и библиотекой SciPy. SciPy основывается на объекте массива NumPy и является частью стека, который включает в себя такие инструменты, как Matplotlib, Pandas и SymPy с дополнительными инструментами.
Библиотека SciPy содержит модули для эффективных математических процедур, таких как линейная алгебра, интерполяция, оптимизация, интеграция и статистика. Основной функционал библиотеки SciPy построен на NumPy и его массивах.
Когда использовать? SciPy использует массивы в качестве базовой структуры данных. Он имеет различные модули для выполнения общих задач научного программирования, таких как линейная алгебра, интеграция, матанализ, обыкновенные дифференциальные уравнения и обработка сигналов.
Что можно делать с помощью SciPy?
1. Математические, научные, инженерные вычисления;
2. Процедуры численной интеграции и оптимизации;
3. Поиск минимумов и максимумов функций;
4. Вычисление интегралов функции;
5. Поддержка специальных функций;
6. Работа с генетическими алгоритмами;
7. Решение обыкновенных дифференциальных уравнений.
4. Matplotlib
Это, несомненно, моя любимая и основная библиотека Python. Вы можете создавать истории с данными, визуализированными с помощью Matplotlib. Еще одна библиотека из стека SciPy — Matplotlib — строит 2D-фигуры.
Когда использовать? Matplotlib — это библиотека Python, предоставляющая API для встраивания графиков в приложения. Очень напоминает MATLAB, встроенный в язык программирования Python.
Что можно делать с помощью Matplotlib?
Гистограммы, столбцовые диаграммы, точечные диаграммы, круговые диаграммы — Matplotlib может отображать широкий спектр визуализаций. Приложив немного усилий, с Matplotlib, вы можете создавать любые визуализации:
1. Линейные диаграммы;
2. Точечные диаграммы;
3. Диаграммы с областями;
4. Столбцовые диаграммы и гистограммы;
5. Круговые диаграммы;
6. Диаграммы «стебель-листья»;
7. Контурные графики;
8. Поля векторов;
Matplotlib также облегчает использование меток, сеток, легенд и некоторых других объектов форматирования. В общем, речь идет обо всем, что можно нарисовать!
5. Seaborn
Итак, когда вы читаете официальную документацию по Seaborn, она определяется как библиотека визуализации данных на основе Matplotlib, предоставляющем высокоуровневый интерфейс для изображения интересных и информативных статистических графиков. Проще говоря, seaborn — это расширение Matplotlib с дополнительными возможностями.
Так в чем разница между Matplotlib и Seaborn? Matplotlib используется для основного построения столбцовых, круговых, линейных, точечных диаграмм и пр., в то время как Seaborn предоставляет множество шаблонов визуализации с меньшим количеством синтаксических правил, причем более простых.
Что можно делать с помощью Seaborn?
1. Определять отношения между несколькими переменными (корреляция);
2. Соблюдать качественные переменные для агрегированных статистических данных;
3. Анализировать одномерные или двумерные распределения и сравнивать их между различными подмножествами данных;
4. Построить модели линейной регрессии для зависимых переменных;
5. Обеспечить многоуровневые абстракции, многосюжетные сетки.
Seaborn — это отличный вариант для библиотек визуализации R, таких как corrplot и ggplot.
6. Scikit Learn
Scikit Learn, представленный миру как проект Google Summer of Code, представляет собой надежную библиотеку машинного обучения для Python. Он включает в себя алгоритмы ML, такие как SVM, random forests, k-means кластеризацию, спектральную кластеризацию, сдвиг среднего значения, перекрестную проверку и многие другие. Даже NumPy, SciPy и связанные с ними научные операции поддерживаются Scikit Learn, при этом Scikit Learn является частью SciPy Stack.
Когда использовать? Scikit-learn предоставляет ряд контролируемых и неконтролируемых алгоритмов обучения через согласованный интерфейс в Python. Scikit learn будет вашим руководством для того, чтобы модели контролируемого обучения, такие как Naive Bayes, группировали непомеченные данные, такие как KMeans.
Что можно делать с помощью Scikit Learn?
1. Классификация: обнаружение спама, распознавание изображений;
2. Кластеризация: воздействия лекарственных препаратов, цена акций;
3. Регрессия: сегментация клиентов, группировка результатов эксперимента;
4. Уменьшение размерности: визуализация, повышенная эффективность;
5. Выбор модели: повышенная точность благодаря настройке параметров;
6. Предварительная обработка: подготовка входных данных в виде текста для обработки с помощью алгоритмов машинного обучения.
Scikit Learn фокусируется на моделировании данных; не манипулировании данными. Для обобщения и манипуляции у нас есть NumPy и Pandas.
7. TensorFlow
Еще в 2017 году я получил TensorFlow USB в знак признательности за то, что был потрясающим докладчиком на мероприятии Google WTM, хаха. На USB был загружен официальный документ о TensorFlow. Не имея представления о том, что такое TensorFlow, я его погуглил.
TensorFlow — это библиотека AI, которая помогает разработчикам создавать крупномасштабные нейронные сети со многими слоями, используя графики потоков данных. TensorFlow также облегчает построение моделей глубокого обучения, продвигает современную технологию ML / AI и позволяет легко развертывать приложения на базе ML.
Одним из наиболее развитых веб-сайтов среди всех библиотек является TensorFlow. Гиганты, такие как Google, Coca-Cola, Airbnb, Twitter, Intel, DeepMind, все используют TensorFlow!
Когда использовать? TensorFlow достаточно эффективен, когда дело доходит до классификации, восприятия, понимания, обнаружения, прогнозирования и создания данных.
Что можно делать с помощью TensorFlow?
1. Распознавание голоса / звука — IoT, автомобильная промышленность, безопасность, UX/UI, телекоммуникации;
2. Анализ настроений — в основном для CRM или CX;
3. Текстовые Приложения — Обнаружение угроз, Google Translate, Gmail Smart Reply;
4. Распознавание лиц — Facebook’s Deep Face, Photo tagging, Smart Unlock;
5. Временной ряд — рекомендации от Amazon, Google и Netflix;
6. Обнаружение видео — обнаружение движения, обнаружение угроз в реальном времени в играх, безопасности, аэропортах.
Более подробно о TensorFlow рассказываем в статье.
8. Keras
Keras — это высокоуровневый API TensorFlow для создания и обучения кода глубоких нейронных сетей. Это библиотека нейронных сетей с открытым исходным кодом на Python. С Keras статистическое моделирование, работа с изображениями и текстом намного легче с упрощенным кодированием для глубокого обучения.
В чем разница между Keras и TensorFlow?
Keras — это нейросетевая библиотека, написанная на языке Python, а TensorFlow — это библиотека с открытым исходным кодом для различных задач машинного обучения. TensorFlow предоставляет как высокоуровневые, так и низкоуровневые API, в то время как Keras предоставляет только высокоуровневые API. Keras создан для Python и делает его более удобным, модульным и компонуемым, чем TensorFlow.
Что можно делать с помощью Keras?
1. Определить процентную точность;
2. Функция вычисления потерь;
3. Создать пользовательские функциональные слои;
4. Встроенные функции обработки данных и изображений;
5. Функции с повторяющимися блоками кода: глубиной 20, 50, 100 слоев.
9. Statsmodels
Когда я сначала изучил R, проведение статистических тестов и исследование статистических данных казались мне самым простым в R и я избегал Python для статистического анализа до тех пор, пока я не изучил Statsmodels в Python.
Когда использовать? Statsmodels — это универсальный пакет Python, который обеспечивает простые вычисления для описательной статистики и оценки и формирования статистических моделей.
Что можно делать с помощью Statsmodels?
1. Линейная регрессия;
3. Метод наименьшего квадрата (OLS);
4. Анализ выживания;
5. Обобщенные линейные модели и байесовская модель;
6. Однофакторный и двухфакторный анализ, проверка гипотез (в основном, что может сделать R!).
10. Plotly
Plotly — это типичная графическая библиотека для Python. Пользователи могут импортировать, копировать, вставлять или передавать данные, которые должны быть проанализированы и визуализированы. Plotly предлагает изолированную версию Python (где вы можете запустить Python, ограниченный в своих возможностях). Теперь осталось понять, что значит ограниченная версия, но я точно знаю, что Plotly облегчает задачу!
Когда использовать? Вы можете использовать Plotly, если хотите создавать и отображать фигуры, обновлять фигуры, наводить курсор на текст для получения подробной информации. Plotly также имеет дополнительную функцию отправки данных на облачные серверы. Это интересно!
Что можно делать с помощью Plotly?
Библиотека графиков Plotly имеет широкий спектр графиков, которые вы можете построить:
1. Основные диаграммы: линейные, круговые, точечные, пузырьковые, Ганта, санбёрст, древовидные, санкей, графики с областями;
2. Статистические стили и стили Seaborn: ошибки, гистограммы, диаграммы Facet и Trellis, деревообразные графики, графики-скрипки, линии тренда;
3. Научные карты: контур, троичный сюжет, логарифмический график, поля векторов, ковровый график (Carpet plot), радарчарт, тепловые карты Роза ветров и Полярный сюжет;
4. Финансовые графики;
8. Взаимодействие Jupyter Widgets.
Plotly это типичная библиотека графиков. Подумайте о визуализации и Plotly сделает это!
Итак, мы изучили путеводитель по топ 10 библиотекам Python для науки о данных, а теперь рассмотрим наши 4 бонусные библиотеки!
1. SpaСy
SpaCy — это библиотека с открытым исходным кодом, используемая для продвинутого NLP для Python и Cython (язык программирования Python, обеспечивающий ощущение и производительность в стиле C с кодом Python, а также синтаксис на основе C).
2. Bokeh
Bokeh — это библиотека Python, которую я бы назвал интерактивной визуализацией данных. С такими инструментами, как Tableau, QlikView или PowerBI, зачем нам Bokeh? Во-первых, Bokeh позволяет очень быстро строить сложные статистические графики с помощью простых команд. Он поддерживает вывод HTML, блокнота или сервера. Во-вторых, можно интегрировать визуализацию Bokeh в приложения Flask и Django или визуализации, написанные в других библиотеках, таких как matplotlib, seaborn, ggplot.
3. Gensim
Gensim — это то, что, по моему мнению, сильно отличается от того, что мы встречали до этого. Он автоматически извлекает семантические темы из документов без труда и с высокой эффективностью. Алгоритмы Gensim не контролируются, это означает, что никакой человеческий ввод не требуется — просто текстовые документы, и затем выполняется извлечение.
4. NLTK
NLTK (Natural Language Toolkit) в основном работает с человеческим языком, а не с компьютерным, чтобы применять обработку естественного языка (NLP). Он содержит библиотеки обработки текста, с помощью которых вы можете выполнять токенизацию, парсинг, классификацию, выделение, тегирование и семантическое обоснование данных. На основе функционала этой библиотеки может показаться, что она повторяется, но каждая библиотека в Python была написана для повышения некоторой эффективности.
Топ 6 библиотек Python для визуализации: какую и когда лучше использовать?
Всех желающих приглашаем на открытый онлайн-интенсив «Data Science — это проще, чем кажется». Поговорим об истории и основных вехах в развитии ИИ, вы узнаете, какие задачи решает DS и чем занимается ML. И уже на первом занятии вы сможете научить компьютер определять, что изображено на картинке. А именно, вы попробуете обучить свою первую модель машинного обучения для решения задачи классификации изображений. Поверьте, это проще, чем кажется!

Не знаете, какой инструмент визуализации использовать? В этой статье мы подробно расскажем о плюсах и минусах каждой библиотеки.
Это руководство было дополнено несколькими подробными примерами. Вы также можете отслеживать актуальные версии этой статьи здесь.
Мотивация
Если вы только собираетесь начать работу с визуализацией в Python, количество библиотек и решений вас определенно поразит:
Но какую из этих библиотек лучше выбрать для визуализации DataFrame? Некоторые библиотеки имеют больше преимуществ для использования в некоторых конкретных случаях. В этой статье приведены плюсы и минусы каждой из них. Прочитав эту статью, вы будете разбираться в функционале каждой библиотеки и будете способны подбирать для ваших потребностей оптимальную.
Мы будем использовать один и тот же набор данных, на примере которого будем рассматривать каждую библиотеку, уделяя особое внимание нескольким показателям:
Интерактивность
Хотите ли вы, чтобы ваша визуализация была интерактивной?
Визуализация в некоторых библиотеках, таких как Matplotlib, является простым статичным изображением, что хорошо подходит для объяснения концепций (в документе, на слайдах или в презентации).
Другие библиотеки, такие как Altair, Bokeh и Plotly, позволяют создавать интерактивные графики, которые пользователи могут изучать, взаимодействуя с ними.
Синтаксис и гибкость
Чем отличается синтаксис каждой библиотеки? Библиотеки низкого уровня, такие как Matplotlib, позволяют делать все, что вы захотите, но за счет более сложного API. Некоторые библиотеки, такие как Altair, очень декларативны, что упрощает построение графиков по вашим данным.
Тип данных и визуализации
Приходилось ли вам сталкиваться в работе с нестандартными юзкейсами, например, с географическим графиком, включающим большой набор данных или с типом графика, который поддерживается только определенной библиотекой?
Данные
Чтобы было проще сравнивать библиотеки, здесь представлены реальные данные с Github из этой статьи:
I Scraped more than 1k Top Machine Learning Github Profiles and this is what I Found
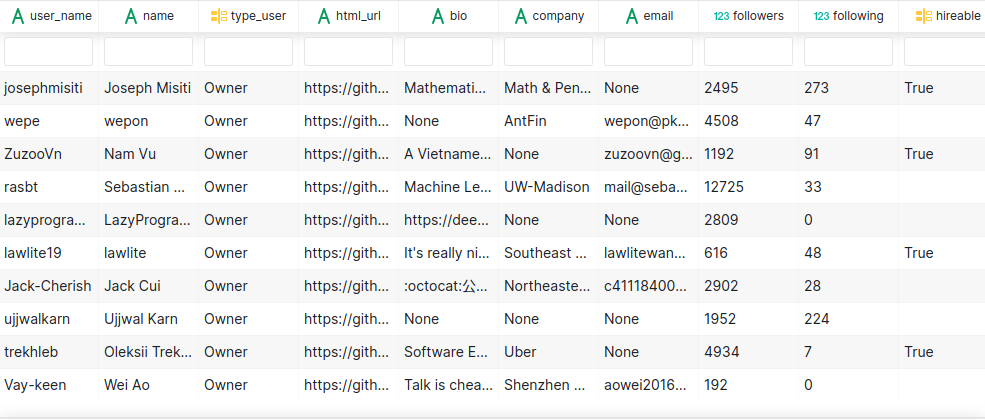
В статью включены визуализации из каждой библиотеки с помощью Datapane, который представляет собой Python фреймворк и API для публикации и совместного использования Python-отчетов. Больше реальных примеров вы можете найти в пользовательских отчетах в галереи Datapane.
Вы можете скачать файл csv здесь, либо получите данные напрямую из Datapane Blob.
import datapane as dp dp.Blob.get(name='github_data', owner='khuyentran1401').download_df()Не забудьте залогиниться со своим токеном авторизации в Datapane, если вы хотите использовать Blob. Это займет менее минуты.
Matplotlib
Matplotlib, вероятно, является самой популярной библиотекой Python для визуализации данных. Все, кто интересуется data science, наверняка хоть раз сталкивались с Matplotlib.
Плюсы
- Четко отображены свойства данных
При анализе данных возможность быстро посмотреть распределение может быть очень полезной.
Например, если я хочу быстро посмотреть распределение топ 100 пользователей с наибольшим количеством подписчиков, обычно Matplotlib мне будет вполне достаточно:
import matplotlib.pyplot as plt top_followers = new_profile.sort_values(by='followers', axis=0, ascending=False)[:100] fig = plt.figure() plt.bar(top_followers.user_name, top_followers.followers)Даже что-то вроде этого:
fig = plt.figure() plt.text(0.6, 0.7, "learning", size=40, rotation=20., ha="center", va="center", bbox=dict(boxstyle="round", ec=(1., 0.5, 0.5), fc=(1., 0.8, 0.8), ) ) plt.text(0.55, 0.6, "machine", size=40, rotation=-25., ha="right", va="top", bbox=dict(boxstyle="square", ec=(1., 0.5, 0.5), fc=(1., 0.8, 0.8), ) ) plt.show()Минусы
Matplotlib может создать любой график, но с его помощью может быть сложно построить или подогнать сложные графики, чтобы они выглядели презентабельно.
Несмотря на то, что график достаточно хорошо подходит для визуализации распределений, если вы хотите презентовать его публике, вам нужно будет откорректировать оси X и Y, что потребует больших усилий, потому что Matplotlib имеет чрезвычайно низкоуровневый интерфейс.
correlation = new_profile.corr() fig, ax = plt.subplots() im = plt.imshow(correlation) ax.set_xticklabels(correlation.columns) ax.set_yticklabels(correlation.columns) plt.setp(ax.get_xticklabels(), rotation=45, ha="right", rotation_mode="anchor")Вывод: с помощью Matplotlib можно создать что угодно, но для сложных графиков может потребоваться гораздо больше кода, чем другим библиотекам.
Seaborn
Seaborn — это библиотека Python для визуализации данных, построенная на базе Matplotlib. Она более высокоуровневая, что упрощает ее использование.
Плюсы
Предоставляет интерфейс более высокого уровня для построения похожих графиков. Другими словами, seaborn обычно строит графики, аналогичные matplotlib, но с меньшим количеством кода и более красивым дизайном.
Мы используем те же данные, что и раньше, чтобы построить аналогичный график пользовательской активности.
correlation = new_profile.corr() sns.heatmap(correlation, annot=True)Мы получаем лучший график пользовательской активности без возни x и y!
2. Делает стандартные графики красивее
Многие люди выбирают seaborn для создания широко используемых графиков, таких как столбчатые и прямоугольные диаграммы, расчетные графики, гистограммы и т. д., но не только потому, что это потребует меньше кода, они еще и визуально приятнее. Как видно на примере выше, цвета выглядят лучше, чем цвета по умолчанию в Matplotlib.
sns.set(style="darkgrid") titanic = sns.load_dataset("titanic") ax = sns.countplot(x="class", data=titanic)Минусы
Seaborn более ограничен и не имеет такой широкой коллекции графиков, как matplotlib.
Вывод: Seaborn — это версия Matplotlib более высокого уровня. Несмотря на то, что коллекция графиков не настолько большая, как в Matplotlib, созданные с помощью seaborn широко используемые графики (например, столбчатая диаграмма, прямоугольная диаграмма, график пользовательской активности и т. д.), при меньшем количестве кода будет выглядеть визуально приятнее.
Plotly
Python библиотека Plotly упрощает создание интерактивных графиков типографского качества. Он также может создавать диаграммы, аналогичные Matplotlib и seaborn, такие как линейные графики, точечные диаграммы, диаграммы с областями, столбчатые диаграммы и т. д.
Плюсы
Если вы поклонник графиков в R и вам не хватает его функционала при переходе на Python, Plotly даст вам такое же качество графиков с использованием Python!
Мой любимая версия — Plotly Express, потому что с ней можно легко и быстро создавать отличные графики одной строчкой в Python.
import plotly.express as px fig = px.scatter(new_profile[:100], x='followers', y='total_stars', color='forks', size='contribution') fig.show()2. Простота создания интерактивных графиков
Plotly также упрощает создание интерактивных графиков. Интерактивные графики не только красиво выглядят, но и позволяют публике более внимательно изучить каждую точку на графике.
Помните столбчатую диаграмму, которую мы показывали ранее в matplotlib? Давайте посмотрим, как она получится с помощью Plotly
import plotly.express as px top_followers = new_profile.sort_values(by='followers', axis=0, ascending=False)[:100] fig = px.bar(top_followers, x='user_name', y='followers', ) fig.show()Примерно за столько же строк кода мы создали интерактивный график, на котором можно навести указатель мыши на каждый столбец, чтобы увидеть, кому он принадлежит и сколько подписчиков у этого пользователя. Это означает, что пользователь вашей визуализации может изучить ее самостоятельно.
3. Легко делать сложные графики
С помощью Plotly достаточно легко создавать сложные графики.
Например, если мы хотим создать карту для визуализации местоположения пользователей GitHub, мы можем найти широту и долготу их расположения как показано здесь, а затем использовать эти данные чтобы отметить местоположение пользователей уже на карте:
import plotly.express as px import datapane as dp location_df = dp.Blob.get(name='location_df', owner='khuyentran1401').download_df() m = px.scatter_geo(location_df, lat='latitude', lon='longitude', color='total_stars', size='forks', hover_data=['user_name','followers'], title='Locations of Top Users') m.show()И, написав всего несколько строк кода, местоположения всех пользователей красиво представлены на карте. Цвет окружностей представляет количество форков, а размер — общее количество звезд.
Вывод: Plotly отлично подходит для создания интерактивных и качественных графиков при помощи всего нескольких строк кода.
Altair
Altair — это библиотека Python декларативной статистической визуализации, которая основана на vega-lite, что идеально подходит для графиков, требующих большого количества статистических преобразований.
Плюсы
1. Простая грамматика визуализации
Грамматика, используемая для визуализации, невероятно проста для понимания. Необходимо только обозначить связи между столбцами данных и каналами их преобразования, а остальная часть построения графиков обрабатывается автоматически. Это звучит довольно абстрактно, но имеет решающее значение, когда вы работаете с данными, и делает визуализацию информации очень быстрой и интуитивно понятной.
Например, для данных о Титанике выше мы хотели бы подсчитать количество людей в каждом классе. Все, что нам нужно, это использовать count() в y_axis
import seaborn as sns import altair as alt titanic = sns.load_dataset("titanic") alt.Chart(titanic).mark_bar().encode( alt.X('class'), y='count()' )2. Простота преобразования данных
Altair также упрощает преобразование данных при создании диаграммы.
Например, мы хотим определить средний возраст каждого пола на Титанике и вместо того, чтобы выполнять преобразование заранее, как в Plotly, в Altair есть возможность выполнить преобразование в коде, описывающем диаграмму.
hireable = alt.Chart(titanic).mark_bar().encode( x='sex:N', y='mean_age:Q' ).transform_aggregate( mean_age='mean(age)', groupby=['sex']) hireableЛогика здесь состоит в том, чтобы использовать transform_aggregate() для взятия среднего значения возраста ( mean(age) ) каждого пола ( groupby=[‘sex’] ) и сохранить его в переменной mean_age ). За ось Y мы берем переменную.
Мы также можем убедиться, что класс — это номинальные данные (категорийные данные в произвольном порядке), используя :N , или что mean_age — это количественные данные (меры значений, такие как числа), используя :Q .
Полный список преобразований данных можно найти здесь.
3. Связывание нескольких графиков
Altair также позволяет создавать впечатляющие связи между графиками, например, с возможностью использовать выбор интервала для фильтрации содержимого прикрепленной гистограммы.
Например, мы хотим визуализировать количество людей из каждого класса в пределах значений, ограниченных выделенным интервалом в точечной диаграмме по возрасту и плате за проезд. Тогда нам нужно написать что-то вроде этого:
brush = alt.selection(type='interval') points = alt.Chart(titanic).mark_point().encode( x='age:Q', y='fare:Q', color=alt.condition(brush, 'class:N', alt.value('lightgray')) ).add_selection( brush ) bars = alt.Chart(titanic).mark_bar().encode( y='class:N', color='class:N', x = 'count(class):Q' ).transform_filter( brush ) points & barsКогда мы перетаскиваем мышь, чтобы выбрать интервал на корреляционной диаграмме, мы можем наблюдать изменения на гистограмме ниже. В сочетании с преобразованиями и вычислениями, сделанными ранее, это означает, что вы можете создавать несколько чрезвычайно интерактивных графиков, которые выполняют вычисления на лету — даже не требуя работающего сервера Python!
Минусы
Если вы не задаете пользовательский стиль, простые диаграммы, такие как, например, столбчатые, не будут оформлены стилистически так же хорошо, как в seaborn или Plotly. Altair также не рекомендует использовать наборы данных с более чем 5000 экземплярами и рекомендует вместо этого агрегировать данные перед визуализацией.
Вывод: Altair идеально подходит для создания сложных графиков для отображения статистики. Altair не может обрабатывать данные, превышающие 5000 экземпляров, и некоторые простые диаграммы в нем уступают по стилю Plotly или Seaborn.
Bokeh
Bokeh — это интерактивная библиотека для визуализации, предназначенная для презентации данных в браузерах.
Плюсы
- Интерактивная версия Matplotlib
Если мы будем будем составлять топы интерактивных библиотек для визуализации, Bokeh, вероятно, займет первое место в категории сходства с Matplotlib.
Matplotlib позволяет создать любой график, так как эта библиотека предназначена для визуализации на достаточно низком уровне. Bokeh можно использовать как с высокоуровневым, так и низкоуровневым интерфейсом; таким образом, она способна создавать множество сложных графиков, которые создает Matplotlib, но с меньшим количеством строк кода и более высоким разрешением.
Например, круговой график Matplotlib,
import matplotlib.pyplot as plt fig, ax = plt.subplots() x = [1, 2, 3, 4, 5] y = [2, 5, 8, 2, 7] for x,y in zip(x,y): ax.add_patch(plt.Circle((x, y), 0.5, edgecolor = "#f03b20",facecolor='#9ebcda', alpha=0.8)) #Use adjustable='box-forced' to make the plot area square-shaped as well. ax.set_aspect('equal', adjustable='datalim') ax.set_xbound(3, 4) ax.plot() #Causes an autoscale update. plt.show()который, в Bokeh, может быть создан с лучшим разрешением и функциональностью:
from bokeh.io import output_file, show from bokeh.models import Circle from bokeh.plotting import figure reset_output() output_notebook() plot = figure(plot_width=400, plot_height=400, tools="tap", title="Select a circle") renderer = plot.circle([1, 2, 3, 4, 5], [2, 5, 8, 2, 7], size=50) selected_circle = Circle(fill_alpha=1, fill_color="firebrick", line_color=None) nonselected_circle = Circle(fill_alpha=0.2, fill_color="blue", line_color="firebrick") renderer.selection_glyph = selected_circle renderer.nonselection_glyph = nonselected_circle show(plot)2. Связь между графиками
В Bokeh также можно достаточно просто связывать графики. Изменение, примененное к одному графику, будет применено к другому графику с этой же переменной.
Например, если мы создаем 3 графика рядом и хотим наблюдать их взаимосвязь, мы можем связанное закрашивание
from bokeh.layouts import gridplot, row from bokeh.models import ColumnDataSource reset_output() output_notebook() source = ColumnDataSource(new_profile) TOOLS = "box_select,lasso_select,help" TOOLTIPS = [('user', '@user_name'), ('followers', '@followers'), ('following', '@following'), ('forks', '@forks'), ('contribution', '@contribution')] s1 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title=None, tools=TOOLS) s1.circle(x='followers', y='following', source=source) s2 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title=None, tools=TOOLS) s2.circle(x='followers', y='forks', source=source) s3 = figure(tooltips=TOOLTIPS, plot_width=300, plot_height=300, title=None, tools=TOOLS) s3.circle(x='followers', y='contribution', source=source) p = gridplot([[s1,s2,s3]]) show(p)Минусы
Поскольку Bokeh — это библиотека, которая имеет интерфейс среднего уровня, она часто требует меньше кода, чем Matplotlib, но требует больше кода для создания того же графика, чем Seaborn, Altair или Plotly.
Например, для создания такого же расчетного графика с данными с Титаника, помимо преобразования данных заранее, мы также должны установить ширину столбца и цвет если мы хотим, чтобы график выглядел красиво.
Если мы не добавим ширину столбцов графика, то он будет выглядеть так:
from bokeh.transform import factor_cmap from bokeh.palettes import Spectral6 p = figure(x_range=list(titanic_groupby['class'])) p.vbar(x='class', top='survived', source = titanic_groupby, fill_color=factor_cmap('class', palette=Spectral6, factors=list(titanic_groupby['class']) )) show(p)Таким образом, нам нужно вручную настраивать параметры, чтобы сделать график более красивым:
from bokeh.transform import factor_cmap from bokeh.palettes import Spectral6 p = figure(x_range=list(titanic_groupby['class'])) p.vbar(x='class', top='survived', width=0.9, source = titanic_groupby, fill_color=factor_cmap('class', palette=Spectral6, factors=list(titanic_groupby['class']) )) show(p)Если вы хотите создать красивую столбчатую диаграмму, используя меньшее количеством кода, то для вас это может быть недостатком Bokeh по сравнению с другими библиотеками
Вывод: Bokeh — единственная библиотека, чей интерфейс варьируется от низкого до высокого, что позволяет легко создавать как универсальные, так и сложные графики. Однако цена этого заключается в том, что для создания графиков с качеством, аналогичным другим библиотекам, обычно требуется больше кода.
Folium
Folium позволяет легко визуализировать данные на интерактивной встраиваемой карте. В библиотеке есть несколько встроенных тайлсетов из OpenStreetMap , Mapbox и Stamen
Плюсы
- Очень легко создавать карты с маркерами
Несмотря на то, что Plotly, Altair и Bokeh также позволяют нам создавать карты, Folium использует открытую уличную карту, что-то близкое к Google Map, с помощью минимального количества кода
Помните, как мы создавали карту для визуализации местоположения пользователей Github с помощью Plotly? Мы могли бы сделать карту еще лучше с помощью Folium:
import folium # Load data location_df = dp.Blob.get(name='location_df', owner='khuyentran1401').download_df() # Save latitudes, longitudes, and locations' names in a list lats = location_df['latitude'] lons = location_df['longitude'] names = location_df['location'] # Create a map with an initial location m = folium.Map(location=[lats[0], lons[0]]) for lat, lon, name in zip(lats, lons, names): # Create marker with other locations folium.Marker(location=[lat, lon], popup= name, icon=folium.Icon(color='green') ).add_to(m) m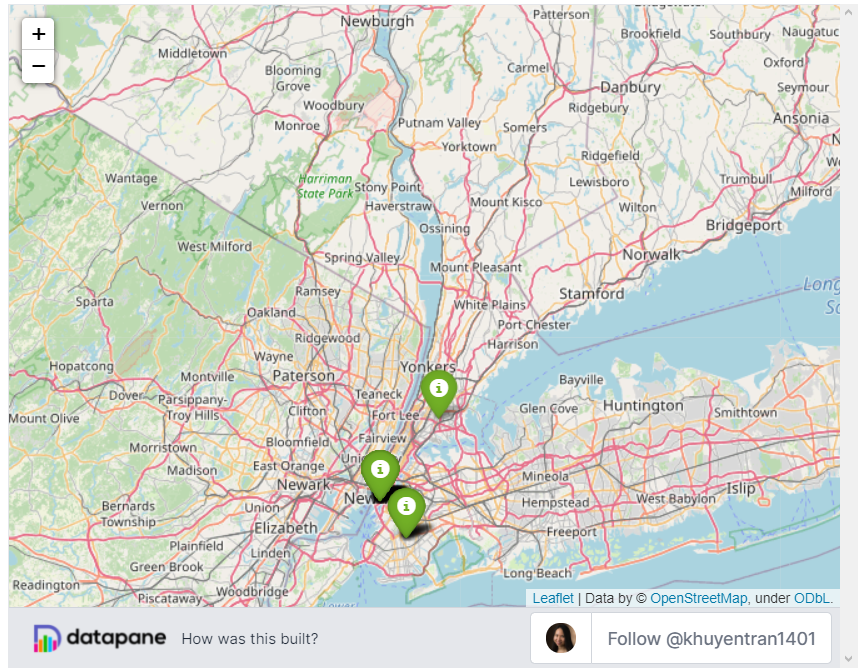
2. Добавление потенциального местоположения
Если мы хотим добавить потенциальные местоположения других пользователей, Folium упрощает это, позволяя пользователям добавлять маркеры:
# Code to generate map here #. # Enable adding more locations in the map m = m.add_child(folium.ClickForMarker(popup='Potential Location'))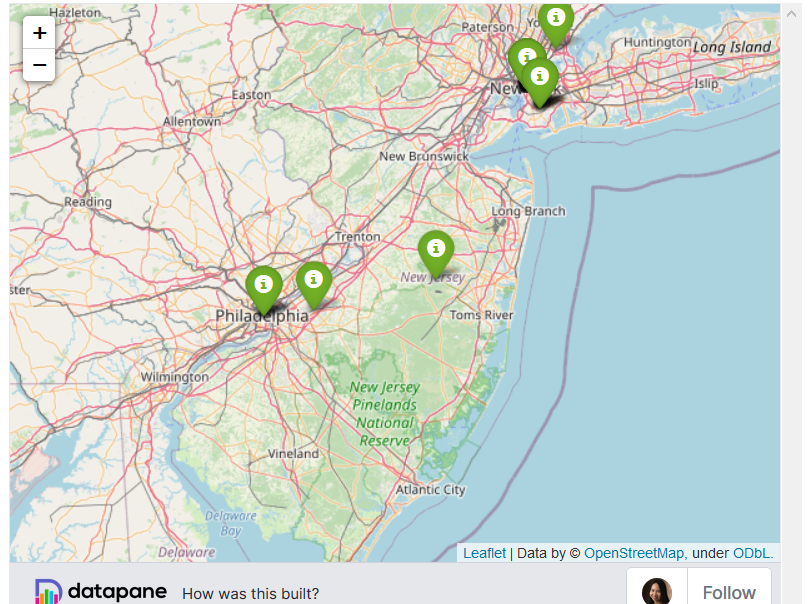
Кликните на карту, чтобы увидеть новое местоположение, созданное прямо там, где вы кликнули.
3. Плагины
У Folium есть ряд плагинов, которые вы можете использовать со своей картой, в том числе плагин для Altair. Что, если мы хотим увидеть карту пользовательской активности общего количества звездных пользователей Github в мире, чтобы определить, где находится большое количество пользователей Github с большим количеством звезд? Карта пользовательской активности в плагинах Folium позволяет вам это сделать:
from folium.plugins import HeatMap m = folium.Map(location=[lats[0], lons[0]]) HeatMap(data=location_df[['latitude', 'longitude', 'total_stars']]).add_to(m)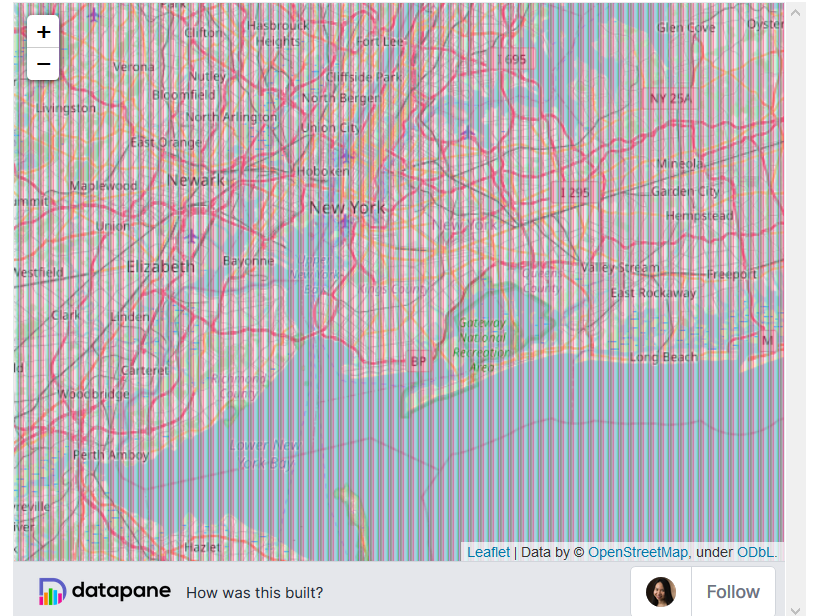
Уменьшите масштаб, чтобы увидеть полное отображение пользовательской активности на карте.
Вывод: Folium позволяет создавать интерактивную карту в несколько строк кода. Он дает вам ощущения близкие к использованию Google Map.
Заключение
Поздравляем! Вы только что узнали о шести различных инструментах визуализации. Я надеюсь, что эта статья даст вам представление о возможностях каждой библиотеки и когда их лучше использовать. Освоение ключевых функций каждой библиотеки позволит вам быстрее определять нужную библиотеку для конкретной работы по мере необходимости.
Если вы все еще не знаете, какую библиотеку использовать для ваших данных, просто выберите ту, которая вам больше нравится. Затем, если код слишком громоздкий или график не так хорош, как вы думаете, просто попробуйте другую библиотеку!
Не стесняйтесь форкать и использовать код для этой статьи из этого репозитория на Github.
Мне нравится писать об основных концепциях data science и пробовать различные алгоритмы и инструменты анализа данных. Вы можете связаться со мной в LinkedIn и Twitter.
Отметьте этот репозиторий, если хотите изучить код всех статей, которые я писал. Следите за мной на Medium, чтобы быть в курсе моих последних статей по data science.
- machinelearning
- data science
- классификация изображений
- python
- data visualization
- data analysis