Pep python что это
PEP8 можно определить, как документ, описывающий общепринятый стиль написания кода на языке Python. Python Enhanced Proposal (PEP) — переводится, как заявки по улучшению языка Python.
Помимо PEP8, так же имеются и другие документы под индексами о которых можно прочитать в PEP0. Но наибольшего внимания заслуживает именно PEP8, а так же PEP7 (В нем описывается какого стиля следует придерживаться при написании кода на C в реализации языка python)
На этой странице представлено полное описание PEP8 на русском языке. Так же вы можете ознакомится с коротким описанием PEP8.
1. Внешний вид кода
Отступы
Используйте 4 пробела на каждый уровень отступа.
На каждый уровень отсупа используйте 4 пробела. Для действительно старого кода, который вы не хотите трогать, можите продолжать использовать 8 пробелов.
Табуляция или пробелы?
Пробелы — наиболее предпочтительный метод отступов.
Табуляция может быть использоваться только для поддержки кода, в котором были использованы отступы с помощью табуляции.
В Python 3 запрещается смешивание табуляции и пробелов в отступах.
В Python 2 табуляция преобразовыватеся в пробелы.
Интерпретатор Python 2 выдает предупреждения (warnings) при использовании смешанного стиля в отступах при использовании параметра -t. При использовании прараметра -tt, интерпретатор выдаст ошибки (errors) в этих местах. Использование этих параметров очень рекомендуется.
В новых проектах для отступов настоятельно рекомендется использовать пробелы. В этом вам могут помочь многие редакторы
Максимальная длина строки
Длину строки рекомендуется ограничить 79 символами
Для более длинных блоков текста с меньшими структурными ограничениями, таким как строки документации или комментарии, длину строки следует ограничить 72 символами.
Сейчас все еще существует устройства, где длина строки ограничена 80 символам. Автоматический перенос строк на таких устройствах нарушит форматирование, и код будет труднее понять. Так же, ограничив ширину окна 80 символами, мы сможем расположить несколько окон рядом друг с другом.
Предпочтительный способ переноса длинных строк — использование подразумевающегося продолжения строки между обычными, квадратными и фигурными скобками. Если необходимо — можно добавить еще одну пару скобок вокруг выражения, но лучше использовать обратный слэш («\»).
with open('/path/to/some/file/you/want/to/read') as file_1, \ open('/path/to/some/file/being/written', 'w') as file_2: file_2.write(file_1.read())
Другой вариант — инструкция assert.
Постарайтесь сделать правильные отступы для перенесённой строки. Предпочтительнее ставить перенос после бинарного оператора, а не перед ним.
class Rectangle(Blob): def __init__(self, width, height, color='black', emphasis=None, highlight=0): if (width == 0 and height == 0 and color == 'red' and emphasis == 'strong' or highlight > 100): raise ValueError("sorry, you lose") if width == 0 and height == 0 and (color == 'red' or emphasis is None): raise ValueError("I don't think so -- values are %s, %s" % (width, height)) Blob.__init__(self, width, height, color, emphasis, highlight)
Пустые строки
Функции верхнего уровня и определения классов отделяются двумя пустыми строками.
Определения методов внутри класса разделяются одной пустой строкой.
Дополнительные отступы пустыми строками могут быть использованы для выделения группы логически связанных функций. Пустые строки могут быть пропущены, между несколькими выражениями, записанными в одну строку, например, «заглушки» функций.
Используйте пустые строки в коде функций, чтобы указать логические разделы.
Python расценивает символ Сontrol+L как незначащий (whitespace). Вы можете использовать его, так как многие редакторы обрабатывают его как разрыв страницы — таким образом логические части в файле будут на разных страницах.
Кодировка исходного файла
Кодировка Python 3 должна быть UTF-8 (ASCII в Python 2).
Файлы в ASCII (Python 2) или UTF-8 (Python 3) не должны иметь объявления кодировки.
В стандартной библиотеке, нестандартные кодировки должны использоваться только для тестирования, либо если комментарий или строка документации требует упомянуть имя автора, содержащего не ASCII символы; в остальных случаях использование \x, \u, \U или \N — наиболее предпочтительный способ включить не ASCII символы в строковых литералах.
Начиная с версии python 3.0 в стандартной библиотеке действует следующее соглашение: все идентификаторы обязаны содержать только ASCII символы, и означать английские слова везде, где это возможно. Кроме того, строки и комментарии тоже должны содержать лишь ASCII символы. Исключения составляют:
1) test case, тестирующий не-ASCII особенности программы;
2) Bмена авторов. Авторы, чьи имена основаны не на латинском алфавите, должны транслитерировать свои имена в латиницу.
Проектам с кодом открытым для широкой аудитории также рекомендуется использовать это соглашение.
Импорты
- Для каждого импорта — отдельная строка. Правильно:
import os import datetime
Неправильно:
import os, datetime
В то же время, можно писать так:
from subprocess import Popen, PIPE
- импорты из стандартной библиотеки
- импорты сторонних библиотек
- импорты модулей текущего проекта
Между каждой группой импортов вставляйте пустую строку.
Указывайте спецификации __all__ после импортов.
from myclass import MyClass from foo.bar.yourclass import YourClass
Если такое написание вызывает конфликт имен, тогда пишите:
import myclass import foo.bar.yourclass
Пробелы в выражениях и инструкциях
Следует избегать использования пробелов в следующих ситуациях:
- Внутри круглых, квадратных или фигурных скобок. Правильно:
animals(tiger[2 ], : 6>)
Неправильно:
animals ( tiger [ 1 ], eagle : 2 > )
if x == y:
if x == y :
tiger(1)
Неправильно:
tiger (1)
dict['key'] = list[index]
Неправильно:
dict ['key'] = list [index]
x = 1 y = 2 long_variable = 3
Неправильно:
x = 1 y = 2 long_variable = 3
Другие рекомендации
- Всегда окружайте следующие бинарные операторы одним пробелом с каждой стороны: операторы присваивания (=, +=, -= и другие), операторы сравнения (==, , !=, <>, =, in, not in, is, is not), логические операторы (and, or, not).
- Если используются операторы с разными приоритетами, попробуйте добавить пробелы вокруг операторов с самым низким приоритетом для того, чтобы сразу визуально отличить очередность выполнения. Используйте свои собственные суждения, но никогда не используйте более одного пробела, а так же всегда используйте одинаковое количество пробелов по обе стороны бинарного оператора. Правильно:
i = i + 1 submitted += 1 x = x*2 - 1 hypot2 = x*x + y*y c = (a+b) * (a-b)
Неправильно:
i=i+1 submitted +=1 x = x * 2 - 1 hypot2 = x * x + y * y c = (a + b) * (a - b)
def complex(real, imag=0.0): return magic(r=real, i=imag)
Неправильно:
def complex(real, imag = 0.0): return magic(r = real, i = imag)
if foo == 'blah': do_blah_thing() do_one() do_two() do_three()
Неправильно:
if foo == 'blah': do_blah_thing() do_one(); do_two(); do_three()
if foo == 'blah': do_blah_thing() for x in lst: total += x while t 10: t = delay()
Точно неправильно:
if foo == 'blah': do_blah_thing() else: do_non_blah_thing() try: something() finally: cleanup() do_one(); do_two(); do_three(long, argument, list, like, this) if foo == 'blah': one(); two(); three()
Комментарии
Комментарии, которые противоречат коду, хуже, их отсутсвие. Всегда исправляйте комментарии, когда меняете код!
Комментарии должны представлять собой законченными предложениями. Если комментарий — фраза или предложение, первое слово должно быть написано с большой буквы, если только это не имя переменной, которая начинается с маленькой буквы (никогда не изменяйте регистр переменной!).
Если комментарий короткий, можно не ставить точку в конце предложения. Блок комментариев обычно состоит из одного или более абзацев, составленных из полноценных предложений, поэтому каждое предложение должно оканчиваться точкой.
Ставьте два пробела после точки в конце предложения.
Если вы пишете по-английски, не забывайте о книге “Elements of style” Странка и Уайта. Эта книга является эталонным руководством по правильному написанию текстов на английском языке.
Программистам, которые не говорят на английском языке следует писать комментарии на английском. За исключением случаев, когда Вы на 126% уверены, что Ваш код никогда не будут читать люди не знающие вашего родного языка.
Блоки комментариев
Блок комментариев обычно объясняет код (весь, или только некоторую часть), идущий после блока, и должен иметь тот же отступ, что и сам код.
Каждая строчка такого блока должна начинаться с символа # и одного пробела после него.
Абзацы внутри блока комментариев разделяются строкой, состоящей только из одного символа #.
«Встрочные» комментарии
Старайтесь реже использовать подобные комментарии.
Такой комментарий находится в той же строке, что и инструкция. «Встрочные» комментарии должны отделяться как минимум двумя пробелами от самой инструкции. И должны начинаться с символа # и одного пробела.
Если комментарии объясняют очевидное — они не нужны, т.к. только отвлекают от чтения кода
Пример как писать не нужно:
x = x + 1 # Increment x
Строки документации
- Пишите документацию для всех public модулей, функций, классов, методов. Для не-public методов cтроки документации необязательны, но лучше описать, что делает метод. Комментарий нужно писать после строки с def.
- PEP 257 объясняет, как правильно писать документацию. Очень важно, чтобы закрывающие кавычки стояли на отдельной строке. А еще лучше, если перед ними будет ещё и пустая строка.
"""Return a foobang Optional plotz says to frobnicate the bizbaz first. """
Контроль версий
Если вам нужно использовать Subversion, CVS или RCS в ваших исходных кодах, делайте вот так:
__version__ = "$Revision: 1a40d4eaa00b $" # $Source$
Вставляйте эти строки после документации модуля перед любым другим кодом и отделяйте их пустыми строками по одной до и после.
Соглашения по именованию
Соглашения по именованию переменных в python немного туманны, поэтому их список никогда не будет полным — тем не менее, ниже мы приводим список рекомендаций, действующих на данный момент. Новые модули и пакеты должны быть написаны согласно этим стандартам, но если в какой-либо уже существующей библиотеке эти правила нарушаются, предпочтительнее писать в едином с ней стиле.
Главный принцип
Имена, которые видны пользователю как часть общественного API должны следовать конвенциям, которые отражают использование, а не реализацию.
Описание: Стили имен
Существует много разных стилей. Поможем вам распознать, какой стиль именования используется, независимо от того, для чего он используется.
Обычно различают следующие стили:
- b (одиночная маленькая буква)
- B (одиночная заглавная буква)
- lowercase (слово в нижнем регистре)
- lower_case_with_underscores (слова из маленьких букв с подчеркиваниями)
- UPPERCASE (заглавные буквы)
- UPPERCASE_WITH_UNDERSCORES (слова из заглавных букв с подчеркиваниями)
- CapitalizedWords (слова с заглавными буквами, или CapWords, или CamelCase). Замечание: когда вы используете аббревиатуры в таком стиле, пишите все буквы аббревиатуры заглавными — HTTPServerError лучше, чем HttpServerError.
- mixedCase (отличается от CapitalizedWords тем, что первое слово начинается с маленькой буквы)
- Capitalized_Words_With_Underscores (слова с заглавными буквами и подчеркиваниями. Выглядит уродливо!)
В дополнение к этому, используются следующие специальные формы записи имен с добавлением символа подчеркивания в начало или конец имени:
- _single_leading_underscore: слабый индикатор того, что имя используется для внутренних нужд. Например, from M import * не будет импортировать объекты, чьи имена начинаются с символа подчеркивания.
- single_trailing_underscore_: используется по соглашению для избежания конфликтов с ключевыми словами языка python, например:
Tkinter.Toplevel(master, class_='ClassName')
Предписания: соглашения по именованию
Имена, которых следует избегать
Никогда не используйте символы l (маленькая латинская буква «L»), O (заглавная латинская буква «o») или I (заглавная латинская буква «i») как однобуквенные идентификаторы.
В некоторых шрифтах эти символы неотличимы от цифры один и нуля. Если очень нужно l, пишите вместо неё заглавную L.
Имена модулей и пакетов
Модули должны иметь короткие имена, состоящие из маленьких букв. Можно использовать символы подчеркивания, если это улучшает читабельность. То же самое относится и к именам пакетов, однако в именах пакетов не рекомендуется использовать символ подчёркивания.
Так как имена модулей отображаются в имена файлов, а некоторые файловые системы являются нечувствительными к регистру символов и обрезают длинные имена, очень важно использовать достаточно короткие имена модулей — это не проблема в Unix, но, возможно, код окажется непереносимым в старые версии Windows, Mac, или DOS.
Когда модуль расширения, написанный на С или C++, имеет сопутствующий python-модуль (содержащий интерфейс высокого уровня), С/С++ модуль начинается с символа подчеркивания, например, _socket.
Имена классов
Имена классов должны обычно следовать соглашению CapitalizedWords .
Вместо этого могут использоваться соглашения для именования функций, если интерфейс документирован и используется в основном как функции.
Обратите внимание, что существуют отдельные соглашения о встроенных именах: большинство встроенных имен — одно слово (либо два слитно написанных слова), а соглашение CapitalizedWords используется только для именования исключений и встроенных констант.
Имена исключений
Так как исключения являются классами, к исключениями применяется стиль именования классов. Однако вы можете добавить Error в конце имени (если, конечно, исключение действительно является ошибкой).
Имена глобальных переменных
Будем надеяться, что глобальные переменные используются только внутри одного модуля. Руководствуйтесь теми же соглашениями, что и для имен функций.
Добавляйте в модули, которые написаны так, чтобы их использовали с помощью from M import *, механизм __all__, чтобы предотвратить экспортирование глобальных переменных. Или же, используйте старое соглашение, добавляя перед именами таких глобальных переменных один символ подчеркивания (которым вы можете обозначить те глобальные переменные, которые используются только внутри модуля).
Имена функций
Имена функций должны состоять из маленьких букв, а слова разделяться символами подчеркивания — это необходимо, чтобы улучшить читабельность.
Стиль mixedCase допускается в тех местах, где уже преобладает такой стиль, для сохранения обратной совместимости.
Аргументы функций и методов
Всегда используйте self в качестве первого аргумента метода экземпляра объекта.
Всегда используйте cls в качестве первого аргумента метода класса.
Если имя аргумента конфликтует с зарезервированным ключевым словом python, обычно лучше добавить в конец имени символ подчеркивания, чем исказить написание слова или использовать аббревиатуру. Таким образом, class_ лучше, чем clss. (Возможно, хорошим вариантом будет подобрать синоним).
Имена методов и переменных экземпляров классов
Используйте тот же стиль, что и для имен функций: имена должны состоять из маленьких букв, а слова разделяться символами подчеркивания.
Используйте один символ подчёркивания перед именем для непубличных методов и атрибутов.
Чтобы избежать конфликтов имен с подклассами, используйте два ведущих подчеркивания.
Константы
Константы обычно объявляются на уровне модуля и записываются только заглавными буквами, а слова разделяются символами подчеркивания. Например: MAX_OVERFLOW, TOTAL.
Проектирование наследования
Обязательно решите, каким должен быть метод класса или экземпляра класса (далее — атрибут) — public или не-public. Если вы сомневаетесь, выберите не-public атрибут. Потом будет проще сделать его public.
Public атрибуты — это те, которые будут использовать другие программисты, и вы должны быть уверены в обратной совместимости.
Мы не используем термин «private атрибут», потому что на самом деле в python таких не бывает.
Теперь сформулируем рекомендации:
- Открытые атрибуты не должны иметь в начале имени символа подчеркивания.
- Если имя открытого атрибута конфликтует с ключевым словом языка, добавьте в конец имени один символ подчеркивания. Это более предпочтительно, чем аббревиатура или искажение написания (однако, у этого правила есть исключение — аргумента, который означает класс, и особенно первый аргумент метода класса (class method) должен иметь имя cls).
- Назовите простые публичные атрибуты понятными именами и не пишите сложные методы доступа и изменения. Помните, что в python очень легко добавить их потом, если потребуется. В этом случае используйте свойства (properties), чтобы скрыть функциональную реализацию за синтаксисом доступа к атрибутам.
- Если вы планируете класс таким образом, чтобы от него наследовались другие классы, но не хотите, чтобы подклассы унаследовали некоторые атрибуты, добавьте в имена два символа подчеркивания в начало, и ни одного — в конец. Механизм изменения имен в python сработает так, что имя класса добавится к имени такого атрибута, что позволит избежать конфликта имен с атрибутами подклассов.
Общие рекомендации
- Код должен быть написан так, чтобы не зависеть от разных реализаций языка (PyPy, Jython, IronPython, Pyrex, Psyco и пр.). Например, не полагайтесь на эффективную реализацию в CPython конкатенации строк в выражениях типа a+=b или a=a+b. Такие инструкции выполняются значительно медленнее в Jython. В критичных к времени выполнения частях программы используйте ».join() — таким образом склеивание строк будет выполнено за линейное время независимо от реализации python.
- Сравнения с None должны обязательно выполняться с использованием операторов is или is not, а не с помощью операторов сравнения.
- При реализации методов сравнения, лучше всего реализовать все 6 операций сравнения (__eq__, __ne__, __lt__, __le__, __gt__, __ge__), чем полагаться на то, что другие программисты будут использовать только конкретный вид сравнения. Для минимизации усилий можно воспользоваться декоратором functools.total_ordering() для реализации недостающих методов. PEP 207 указывает, что интерпретатор может поменять y > х на х < y, y >= х на х . Однако, лучше всего осуществить все шесть операций, чтобы не возникало путаницы в других местах.
- Всегда используйте выражение def, а не присваивание лямбда-выражения к имени. Правильно:
def f(x): return 2*x
Неправильно:
f = lambda x: 2*x
try: import platform_specific_module except ImportError: platform_specific_module = None
- Если обработчик выводит пользователю всё о случившейся ошибке;
- Если нужно выполнить некоторый код после перехвата исключения, а потом вновь «бросить» его для обработки где-то в другом месте. Обычно же лучше пользоваться конструкцией «try. finally».
try: process_data() except Exception as exc: raise DataProcessingFailedError(str(exc))
try: value = collection[key] except KeyError: return key_not_found(key) else: return handle_value(value)
Неправильно:
try: # Здесь много действий! return handle_value(collection[key]) except KeyError: # Здесь также перехватится KeyError, который может быть сгенерирован handle_value() return key_not_found(key)
with conn.begin_transaction(): do_stuff_in_transaction(conn)
Неправильно:
with conn: do_stuff_in_transaction(conn)
if foo.startswith('bar'):
Неправильно:
if foo[:3] == 'bar':
if isinstance(obj, int):
Неправильно:
if type(obj) is type(1):
Когда вы проверяете, является ли объект строкой, обратите внимание на то, что строка может быть unicode-строкой. В python 2 у str и unicode есть общий базовый класс, поэтому вы можете написать:
if isinstance(obj, basestring):
if not seq: if seq:
Неправильно:
if len(seq) if not len(seq)
if greeting:
Неправильно:
if greeting == True:
PEP 8: что это такое и как применять
PEP 8, иногда обозначаемый PEP8 или PEP-8, представляет собой документ, содержащий рекомендации по написанию кода на Python. Он был составлен в 2001 году Гвидо ван Россумом, Барри Варшавой и Ником Когланом. Основная цель PEP 8 – улучшить читабельность и логичность кода на Python.

PEP расшифровывается как Python Enhancement Proposal («Предложение по усовершенствованию Python»), и их несколько. PEP — это документ для сообщества, который описывает новые функции, предлагаемые для Python, и содержит такие аспекты языка, как дизайн и стиль.
В цикле из трех статей мы разберем основные принципы, изложенные в PEP 8. Эти статьи предназначены для новичков и программистов среднего уровня, поэтому мы не будем затрагивать некоторые из наиболее сложных тем. Вы можете изучить их самостоятельно, прочитав полную документацию по PEP 8 .
Из данной серии статей вы узнаете:
- как писать Python-код, соответствующий PEP8;
- какие доводы лежат в основе рекомендаций, изложенных в PEP8;
- как настроить среду разработки так, чтобы вы могли начать писать код на Python по PEP8.
Зачем нужен PEP 8
“Читаемость имеет значение”, — Дзен Python
PEP 8 существует для улучшения читаемости кода Python. Но почему так важна удобочитаемость? Почему написание читаемого кода является одним из руководящих принципов языка Python?
Как сказал Гвидо ван Россум: «Код читают гораздо чаще, чем пишут». Вы можете потратить несколько минут или целый день на написание фрагмента кода для аутентификации пользователя. В дальнейшем вам не придётся его писать. Но перечитывать его вы точно будете. Этот фрагмент кода может остаться частью проекта, над которым вы работаете. Каждый раз, возвращаясь к этому файлу, вам нужно будет вспомнить, что делает этот код и зачем вы его написали. Поэтому удобочитаемость имеет большое значение.
Если вы новичок в Python, возможно, вам уже через несколько дней или недель будет трудно вспомнить, что делает фрагмент кода. Но если вы следуете PEP 8, вы можете быть уверены, что правильно назвали свои переменные . Вы будете знать, что добавили достаточно пробелов, чтобы обособить логические шаги. Вы также снабдили свой код отличными комментариями. Все это сделает ваш код будет более читабельным, а значит, к нему будет легче вернуться. Следование правилам PEP 8 для новичка может сделать изучение Python гораздо более приятной задачей.
Следование PEP 8 особенно важно, если вы претендуете на должность разработчика. Написание понятного, читаемого кода свидетельствует о профессионализме. Это скажет работодателю, что вы понимаете, как правильно структурировать свой код.
Работая над проектами, вам, скорее всего, придется сотрудничать с другими программистами. Здесь, опять же, очень важно писать читаемый код. Другие люди, которые, возможно, никогда раньше не встречали вас и не видели ваш стиль программирования, должны будут прочитать и понять ваш код. Наличие руководящих принципов, которым вы следуете и которые знаете, облегчит другим чтение вашего кода.
Когда стоит игнорировать PEP 8
Краткий ответ на этот вопрос – никогда. Если вы строго следуете PEP 8, то можете гарантировать, что у вас будет чистый, профессиональный и читабельный код. Это принесет пользу вам, а также сотрудникам и потенциальным работодателям.
Однако некоторые рекомендации в PEP 8 неудобны в следующих случаях:
- соблюдение PEP 8 нарушает совместимость с существующим программным обеспечением
- код, связанный с тем, над чем вы работаете, несовместим с PEP 8
- код должен оставаться совместимым со старыми версиями Python
Как проверить соответствие кода PEP 8
Чтобы убедиться, что ваш код соответствует PEP 8, необходимо многое проверить. Помнить все эти правила при разработке кода может быть непросто. Особенно много времени уходит на приведение прошлых проектов к стандарту PEP 8. К счастью, есть инструменты, которые помогут ускорить этот процесс.
Существует два класса инструментов, которые можно использовать для обеспечения соответствия PEP 8: линтеры и автоформаттеры.
Линтеры
Линтеры – это программы, которые анализируют код, помечают ошибки и предлагают способы их исправления. Они особенно полезны как расширения редактора, поскольку выявляют ошибки и стилистические проблемы во время написания кода.
Вот пара лучших линтеров для кода на Python:
pycodestyle
Это инструмент для проверки вашего кода на соответствие некоторым стилевым соглашениям в PEP8.
Установите pycodestyle с помощью pip:
$ pip install pycodestyle
Вы можете запустить pycodestyle из терминала, используя следующую команду:
$ pycodestyle code.py
code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:6:19: E711 comparison to None should be 'if cond is None:'
flake8
Это инструмент, который сочетает в себе отладчик, pyflakes и pycodestyle.
Установите flake8 с помощью pip:
$ pip install flake8
Запустите flake8 из терминала, используя следующую команду:
$ flake8 code.py
code.py:1:17: E231 missing whitespace after ',' code.py:2:21: E231 missing whitespace after ',' code.py:3:17: E999 SyntaxError: invalid syntax code.py:6:19: E711 comparison to None should be 'if cond is None:'
Замечание: Дополнительная строка в выводе указывает на синтаксическую ошибку.
Автоформаттеры
Автоформаттеры – это программы, которые автоматически реорганизуют ваш код для соответствия PEP 8. Одна из таких программ — black . Она автоматически форматирует код для приведения его в соответствие с большинством правил PEP 8. Единственное, она ограничивает длину строки до 88 символов, а не до 79, как рекомендовано стандартом. Однако вы можете изменить это, добавив флаг командной строки, как в примере ниже.
Установите black с помощью pip. Для запуска требуется Python 3.6+:
$ pip install black
Его можно запустить из командной строки, как и в случае с линтерами. Допустим, вы начали со следующего кода, который не соответствует PEP 8, в файле с именем code.py:
for i in range(0,3): for j in range(0,3): if (i==2): print(i,j)
Затем вы можете запустить следующую команду через командную строку:
$ black code.py reformatted code.py All done! ✨ ? ✨
code.py будет автоматически приведён к следующему виду:
for i in range(0, 3): for j in range(0, 3): if i == 2: print(i, j)
Если вы хотите изменить ограничение длины строки, можно использовать флаг —line-length :
$ black --line-length=79 code.py reformatted code.py All done! ✨ ? ✨
Работа двух других автоформаттеров – autopep8 и yapf – аналогична работе black .
О том, как использовать эти инструменты, хорошо написано в статье Python Code Quality: Tools & Best Practices Александра ван Тол.
В следующих статьях цикла про PEP 8 читайте:
- Нейминг и размещение кода
- Комментарии, пробелы, выбор методов
Как писать питонический код: три рекомендации и три книги

Новички в Python часто спрашивают, как писать питонический код. Проблема — расплывчатое определение слова «питонический». Подробным материалом, в котором вы найдёте ответы на вопрос выше и три полезные книги, делимся к старту курса по Fullstack-разработке на Python.
Что значит «питонический»?
Python более 30 лет. За это время накоплен огромный опыт его применения в самых разных задачах. Этот опыт обобщался, и возникали лучшие практики, которые обычно называют «питоническим» кодом.
Философия Python раскрывается в The Zen of Python Тима Питерса, доступной в любом Python по команде import this в REPL:
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!Начинающих в Python больше всего раздражает красота Zen of Python. В Zen передаётся дух того, что значит «питонический» — и без явных советов. Вот первый принцип дзена Python: «Красивое лучше, чем уродливое». Согласен на 100%! Но как сделать красивым мой некрасивый код? Что это вообще такое — «красивый код»?
Сколь бы ни раздражала эта неоднозначность, именно она делает Zen of Python таким же актуальным, как и в 1999 году, когда Тим Питерс написал этот набор руководящих принципов. Они помогают понять, как отличать питонический и непитонический код, и дают ментальную основу принятия собственных решений.
Каким же будет определение слова «питонический»? Лучшее найденное мной определение взято из ответа на вопрос «Что означает «питонический» В этом ответе питонический код описывается так:
Код, где правилен не только синтаксис, но соблюдаются соглашения сообщества Python, а язык используется так, как он должен использоваться.
Из этого делаем два ключевых вывода:
- Слово «питонический» связано скорее со стилем, чем с синтаксисом. Хотя идиомы Python часто имеют последствия за рамками чисто стилистического выбора, в том числе повышение производительности кода.
- То, что считается «питоническим», определяется сообществом Python.
Итак, у нас сложилось хотя бы какое-то представление о том, что имеют в виду программисты на Python, называя код «питоническим». Рассмотрим три конкретных и доступных способа написания более питонического кода.
1. Подружитесь с PEP8
PEP8 — это официальное руководство по стилю кода Python. PEP расшифровывается как Python Enhancement Proposal («Предложение по улучшению Python»). Это документы, предлагающие новые особенности языка. Они образуют официальную документацию особенности языка, принятие или отклонение которой обсуждается в сообществе Python. Следование PEP8 не сделает код абсолютно «питоническим», но способствует узнаваемости кода для многих Python-разработчиков.
В PEP8 решаются вопросы, связанные с символами пробелов. Например, использование четырёх пробелов для отступа вместо символа табуляции или максимальной длиной строки: согласно PEP8, это 79 символов, хотя данная рекомендация, вероятно, самая игнорируемая.
Первое, что стоит усвоить из PEP8 новичкам, — это рекомендации и соглашения по именованию. Например, следует писать имена функций и переменных в нижнем регистре и с подчёркиваниями между словами lowercase_with_underscores:
# Correct seconds_per_hour = 3600 # Incorrect secondsperhour = 3600 secondsPerHour = 3600Имена классов следует писать с прописными первыми буквами слов и без пробелов, вот так: CapitalizedWords:
# Correct class SomeThing: pass # Incorrect class something: pass class some_thing: passКонстанты записывайте в верхнем регистре и с подчёркиваниями между словами: UPPER_CASE_WITH_UNDERSCORES:
# Correct PLANCK_CONSTANT = 6.62607015e-34 # Incorrect planck_constant = 6.6260715e-34 planckConstant = 6.6260715e-34В PEP8 изложены рекомендации по пробелам: как использовать их с операторами, аргументами и именами параметров функций и для разбиения длинных строк. Хотя эти рекомендации можно освоить, годами практикуясь в чтении и написании совместимого с PEP8 кода, многое всё равно пришлось бы запоминать.
Запоминать все соглашения PEP8 не нужно: найти и устранить проблемы PEP8 в коде могут помочь такие инструменты, как flake8. Установите flake8 с помощью pip:
# Linux/macOS $ python3 -m pip install flake8 # Windows $ python -m pip install flake8flake8 можно использовать как приложение командной строки для просмотра файла Python на предмет нарушений стиля. Допустим, есть файл myscript.py с таким кодом:
def add( x, y ): return x+y num1=1 num2=2 print( add(num1,num2) )При запуске на этом коде flake8 сообщает, как и где именно нарушается стиль:
$ flake8 myscript.py myscript.py:1:9: E201 whitespace after '(' myscript.py:1:11: E231 missing whitespace after ',' myscript.py:1:13: E202 whitespace before ')' myscript.py:4:1: E305 expected 2 blank lines after class or function definition, found 1 myscript.py:4:5: E225 missing whitespace around operator myscript.py:5:5: E225 missing whitespace around operator myscript.py:6:7: E201 whitespace after '(' myscript.py:6:16: E231 missing whitespace after ',' myscript.py:6:22: E202 whitespace before ')'В каждой выводимой строке flake8 сообщается, в каком файле и в какой строке проблема, в каком столбце строки начинается ошибка, номер ошибки и её описание. Используйте эти обозначения, flake8 можно настроить на игнорирование конкретных ошибок:
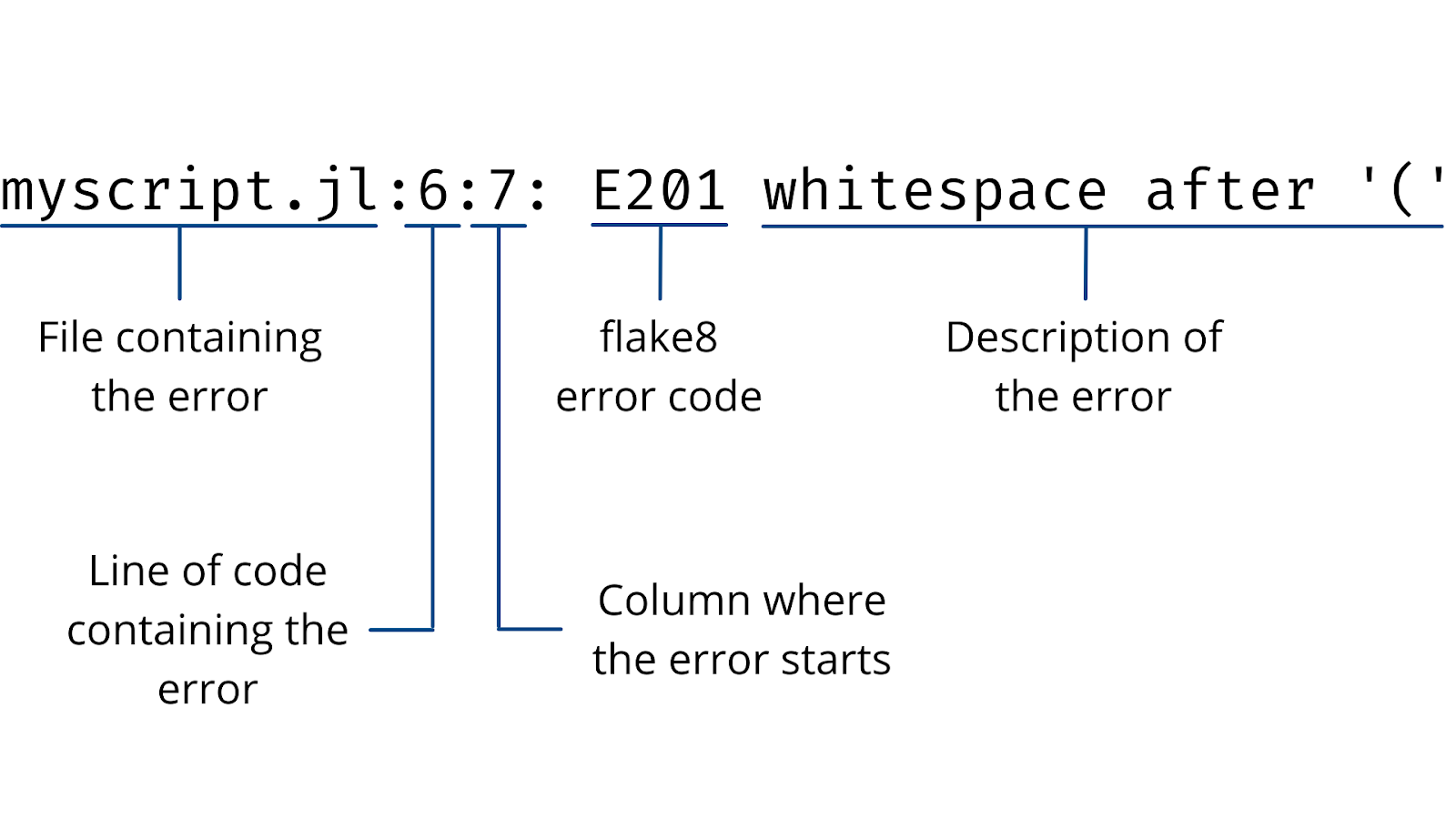
Для проверки качества кода с помощью flake8 вы даже можете настроить редакторы, например VS Code. Пока вы пишете код, он постоянно проверяется на нарушения PEP8. Когда обнаруживается проблема, во flake8 под частью кода с ошибкой появляется красная волнистая линия, найденные ошибки можно увидеть во вкладке встроенного терминала Problems:

flake8 — отличный инструмент для поиска связанных с нарушением PEP8 ошибок, но исправлять их придётся вручную. А значит, будет много работы. К счастью, весь процесс автоматизируемый. Автоматически форматировать код согласно PEP можно с помощью инструмента под названием Black.
Конечно, рекомендации PEP8 оставляют много возможностей для выбора стиля, и в black многие решения принимаются за вас. Вы можете соглашаться с ними или нет. Конфигурация black минимальна.
Установите black c помощью pip:
# Linux/macOS $ python3 -m pip install black # Windows $ python -m pip install blackПосле установки командой black —check можно посмотреть, будут ли black изменять файл:
$ black --check myscript.py would reformat myscript.py Oh no! �� �� �� 1 file would be reformatted.Чтобы увидеть разницу после изменений, используйте флаг —diff:
$ black --diff myscript.py --- myscript.py 2022-03-15 21:27:20.674809 +0000 +++ myscript.py 2022-03-15 21:28:27.357107 +0000 @@ -1,6 +1,7 @@ -def add( x, y ): - return x+y +def add(x, y): + return x + y -num1=1 -num2=2 -print( add(num1,num2) ) + +num1 = 1 +num2 = 2 +print(add(num1, num2)) would reformat myscript.py All done! ✨ �� ✨ 1 file would be reformatted.Чтобы автоматически отформатировать файл, передайте его имя команде black:
$ black myscript.py reformatted myscript.py All done! ✨ �� ✨ 1 file reformatted. # Show the formatted file $ cat myscript.py def add(x, y): return x + y num1 = 1 num2 = 2 print(add(num1, num2))Чтобы проверить совместимость с PEP8, снова запустите flake8 и посмотрите на вывод:
# No output from flake8 so everything is good! $ flake8 myscript.pyПри работе с black следует иметь в виду, что максимальная длина строки по умолчанию в нём — это 88 символов. Это противоречит рекомендации PEP8 о 79 символах, поэтому при использовании black в отчёте flake8 вы увидете ошибки о длине строки.
Многие разработчики Python используют 88 знаков вместо 79, а некоторые — строки ещё длиннее. Можно настроить black на 79 символов, или flake8 — на строки большей длины.
Важно помнить, что PEP8 — это лишь набор рекомендаций, хотя многие программисты на Python относятся к ним серьёзно. PEP8 не применяется в обязательном порядке. Если в нём есть что-то, с чем вы категорически не согласны, вы вправе это игнорировать! Если же вы хотите строго придерживаться PEP8, инструменты типа flake8 и black сильно облегчат вам жизнь.
2. Избегайте циклов в стиле C
В таких языках, как C или C++, отслеживание индексной переменной при переборе массива — обычное дело. Поэтому программисты, которые перешли на Python из C или C++, при выводе элементов списка нередко пишут:
>>> names = ["JL", "Raffi", "Agnes", "Rios", "Elnor"] >>> # Using a `while` loop >>> i = 0 >>> while i < len(names): . print(names[i]) . i += 1 JL Raffi Agnes Rios Elnor >>> # Using a `for` loop >>> for i in range(len(names)): . print(names[i]) JL Raffi Agnes Rios ElnorВместо итерации можно перебрать все элементы списка сразу:
>>> for name in names: . print(name) JL Raffi Agnes Rios ElnorЭтим вторая рекомендация не ограничивается: она намного глубже простого перебора элементов списка. Такие идиомы Python, как списковые включения, встроенные функции (min(), max() и sum()) и методы объектов, может помочь вывести ваш код на новый уровень.
Отдавайте предпочтение списковым включениям, а не простым циклам for
Обработка элементов массива и сохранение результатов в новом — типичная задача программирования. Допустим, нужно преобразовать список чисел в список их квадратов. Избегая циклов в стиле C, можно написать:
>>> nums = [1, 2, 3, 4, 5] >>> squares = [] >>> for num in nums: . squares.append(num ** 2) . >>> squares [1, 4, 9, 16, 25]Но более питонически применить списковое включение:
>>> squares = [num ** 2 for num in nums] # >> squares [1, 4, 9, 16, 25]Списковые включения понять сразу может быть трудно, но они покажутся знакомыми тем, кто помнит математическую форму записи множества.
Вот так я обычно пишу списковые включения:
- Начинаю с создания литерала пустого списка:
[]. - Первым в списковое включение помещаю то, что обычно идёт в метод .append()при создании списка с помощью цикла for:
[num ** 2]. - И, наконец, помещаю в конец списка заголовок цикла for:
[num ** 2 for num in nums].
Списковое включение — важное понятие, которое нужно освоить для написания идиоматичного кода Python, но ими не стоит злоупотреблять. Это не единственный вид списковых включений в Python. Далее поговорим о выражениях-генераторах и словарных включениях, вы увидите пример, когда спискового включения имеет смысл избегать.
Используйте встроенные функции, такие как min(), max() и sum()
Ещё одна типичная задача программирования — это поиск минимального или максимального значения в массиве чисел. Найти наименьшее число в списке можно с помощью for:
>>> nums = [10, 21, 7, -2, -5, 13] >>> min_value = nums[0] >>> for num in nums[1:]: . if num < min_value: . min_value = num . >>> min_value -5Но более «питонически» применять встроенную функцию min():
>>> min(nums) -5То же касается нахождения наибольшего значения в списке: вместо цикла применяется встроенная функция max():
>>> max(nums) 21Чтобы найти сумму чисел списка, написать цикл for можно, но более питонически воспользоваться sum():
>>> # Not Pythonic: Use a `for` loop >>> sum_of_nums = 0 >>> for num in nums: . sum_of_nums += num . >>> sum_of_nums 44 >>> # Pythonic: Use `sum()` >>> sum(nums) 44Также sum() полезна при подсчёте количества элементов списка, для которых выполняется некое условие. Например, вот цикл for для подсчёта числа начинающихся с буквы A строк списка:
>>> capitals = ["Atlanta", "Houston", "Denver", "Augusta"] >>> count_a_capitals = 0 >>> for capital in capitals: . if capital.startswith("A"): . count_a_capitals += 1 . >>> count_a_capitals 2Функция sum() со списковым включением сокращает цикл for до одной строки:
>>> sum([capital.startswith("A") for capital in capitals]) 2Красота! Но ещё более питонической эту строку сделает замена спискового включения на выражение-генератор. Убираем скобки списка:
>>> sum(capital.startswith("A") for capital in capitals) 2Как именно работает код? И списковое включение, и выражение-генератор возвращают итерируемый объект со значением True, если строка в списке capitals начинается с буквы A, и False — если это не так:
>>> [capital.startswith("A") for capital in capitals] [True, False, False, True]В Python True и False — это завуалированные целые числа. True равно 1, а False — 0:
>>> isinstance(True, int) True >>> True == 1 True >>> isinstance(False, int) True >>> False == 0 TrueКогда в sum() передаётся списковое включение или выражение-генератор, значения True и False считаются 1 и 0 соответственно. Всего два значения True и два False, поэтому сумма равна 2.
Использование sum() для подсчёта числа удовлетворяющих какому-то условию элементов списка подчёркивает важность понятия «питонический». Я нахожу такое применение sum() очень питонически. Ведь с sum() используется несколько особенностей этого языка и создаётся, на мой взгляд, лаконичный и удобный для восприятия код. Но, возможно, не каждый разработчик на Python со мной согласится.
Можно было бы возразить, что в этом примере нарушается один из принципов Zen of Python: «Явное лучше неявного». Ведь не очевидно, что True и False — целые числа и что sum() вообще должна работать со списком значений True и False. Чтобы освоить это применение sum(), нужно глубоко понимать встроенные типы Python.
Узнать больше о True и False как целых числах, а также о других неожиданных фактах о числах в Python можно из статьи 3 Things You Might Not Know About Numbers in Python («3 факта о числах в Python, которых вы могли не знать»).
Жёстких правил, когда называть и не называть код питоническим, нет. Всегда есть некая серая зона. Имея дело с примером кода, который может находиться в этой серой зоне, руководствуйтесь здравым смыслом. Для удобства восприятия всегда применяйте err и не бойтесь обращаться за помощью.
3. Используйте правильную структуру данных
Большая роль при написании чистого, питонического кода для конкретной задачи отводится выбору подходящей структуры данных. Python называют языком «с батарейками в комплекте». Некоторые батарейки из комплекта Python — это эффективные, готовые к применению структуры данных.
Используйте словари для быстрого поиска
Вот CSV-файл clients.csv с данными по клиентам:
first_name,last_name,email,phone Manuel,Wilson,mwilson@example.net,757-942-0588 Stephanie,Gonzales,sellis@example.com,385-474-4769 Cory,Ali,coryali17@example.net,810-361-3885 Adam,Soto,adams23@example.com,724-603-5463Нужно написать программу, где в качестве входных данных принимается адрес электронной почты, а выводится номер телефона клиента с этой почтой, если такой клиент существует. Как бы вы это сделали?
Используя объект DictReader из модуля csv, можно прочитать каждую строку файла как словарь:
>>> import csv >>> with open("clients.csv", "r") as csvfile: . clients = list(csv.DictReader(csvfile)) . >>> clients [, , , ]clients — это список словарей. Поэтому, чтобы найти клиента по адресу почты, например sellis@example.com, нужно перебрать список и сравнить почту каждого клиента с целевой почтой, пока не будет найден нужный клиент:
>>> target = "sellis@example.com" >>> phone = None >>> for client in clients: . if client["email"] == target: . phone = client["phone"] . break . >>> print(phone) 385-474-4769Но есть проблема: перебор списка клиентов неэффективен. Если в файле много клиентов, на поиск клиента с совпадающим адресом почты у программы может уйти много времени. А сколько теряется времени, если такие проверки проводятся часто!
Более питонически сопоставить клиентов с их почтами, а не хранить клиентов в списке. Для этого отлично подойдёт словарное включение:
>>> with open("clients.csv", "r") as csvfile: . # Use a `dict` comprehension instead of a `list` . clients = . >>> clients
Словарные включения очень похожи на списковые включения:
- Я начинаю с создания пустого словаря:
<>. - Затем помещаю туда разделённую двоеточием пару «ключ — значение»:
. - И пишу выражение с for, которое перебирает все строки в CSV:
.
Вот это словарное включение, преобразованное в цикл for:
>>> clients = <> >>> with open("clients.csv", "r") as csvfile: . for row in csv.DictReader(csvfile): . clients[row["email"]] = row["phone"]С этим словарём clients вы можете найти телефон клиента по его почте без циклов:
>>> target = "sellis@example.com" >>> clients[target] 385-474-4769Этот код не только короче, но и намного эффективнее перебора списка циклом. Но есть проблема: если в clients нет клиента с искомой почтой, поднимается ошибка KeyError:
>>> clients["tsanchez@example.com"] Traceback (most recent call last): File "", line 1, in KeyError: 'tsanchez@example.com'Поэтому, если клиент не найден, можно перехватить KeyError и вывести значение по умолчанию:
>>> target = "tsanchez@example.com" >>> try: . phone = clients[target] . except KeyError: . phone = None . >>> print(phone) NoneНо более питонически применять метод словаря .get(). Если пара с ключом существует, этот метод возвращает значение пары, иначе возвращается None:
>>> clients.get("sellis@example.com") '385-474-4769'Сравним решения выше:
import csv target = "sellis@example.com" phone = None # Un-Pythonic: loop over a list with open("clients.csv", "r") as csvfile: clients = list(csv.DictReader(csvfile)) for client in clients: if client["email"] == target: phone = client["phone"] break print(phone) # Pythonic: lookup in a dictionary with open("clients.csv", "r") as csvfile: clients = phone = clients.get(target) print(phone)Питонический код короче, эффективнее и не менее удобен для восприятия.
Используйте операции над множествами
Множества — это настолько недооценённая структура данных Python, что даже разработчики среднего уровня склонны их игнорировать, упуская возможности. Пожалуй, самое известное применение множеств в Python — это удаление повторяющихся в списке значений:
>>> nums = [1, 3, 2, 3, 1, 2, 3, 1, 2] >>> unique_nums = list(set(nums)) >>> unique_nums [1, 2, 3]Но множества этим не ограничиваются. Я часто применяю их для эффективной фильтрации значений итерируемого объекта. Работа множеств лучше всего видна, когда нужны уникальные значения.
Вот придуманный, но реалистичный пример. У владельца магазина есть CSV-файл клиентов с адресами их почты. Снова возьмём файл clients.csv. Есть также CSV-файл заказов за последний месяц orders.csv, тоже с адресами почты:
date,email,items_ordered 2022/03/01,adams23@example.net,2 2022/03/04,sellis@example.com,3 2022/03/07,adams23@example.net,1Владельцу магазина нужно отправить купон на скидку каждому клиенту, который в прошлом месяце ничего не заказывал. Для этого он может считать адреса почты из файлов clients.csv и orders.csv и отфильтровать их списковым включением:
>>> import csv >>> # Create a list of all client emails >>> with open("clients.csv", "r") as clients_csv: . client_emails = [row["email"] for row in csv.DictReader(clients_csv)] . >>> # Create a list of emails from orders >>> with open("orders.csv") as orders_csv: . order_emails = [row["email"] for row in csv.DictReader(orders_csv)] . >>> # Use a list comprehension to filter the clients emails >>> coupon_emails = [email for email in clients_emails if email not in order_emails] >>> coupon_emails ["mwilson@example.net", "coryali17@example.net"]Код нормальный и выглядит вполне питонически. Но что, если каждый месяц клиентов и заказов будут миллионы? Тогда при фильтрации почты и определении, каким клиентам отправлять купоны, потребуется перебор всего списка client_emails. А если в файлах client.csv и orders.csv есть повторяющиеся строки? Бывает и такое.
Более питонически считать адреса почты клиентов и заказов в множествах и отфильтровать множества почтовых адресов клиентов оператором разности множеств:
>>> import csv >>> # Create a set of all client emails using a set comprehension >>> with open("clients.csv", "r") as clients_csv: . client_emails = . >>> # Create a set of emails frp, orders using a set comprehension >>> with open("orders.csv", "r") as orders_csv: . order_emails = . >>> # Filter the client emails using set difference >>> coupon_emails = client_emails - order_emails >>> coupon_emails
Этот подход намного эффективнее предыдущего: адреса клиентов перебираются только один раз, а не два. Вот ещё одно преимущество: все повторы почтовых адресов из обоих CSV-файлов удаляются естественным образом.
Три книги, чтобы писать более питонический код
За один день писать чистый питонический код не научиться. Нужно изучить много примеров кода, пробовать писать собственный код и консультироваться с другими разработчиками Python. Чтобы облегчить вам задачу, я составил список из трёх книг, очень полезных для понимания питонического кода. Все они написаны для программистов уровня выше среднего или среднего.
Если вы новичок в Python (и тем более в программировании в целом), загляните в мою книгу Python Basics: A Practical Introduction to Python 3 («Основы Python: Практическое введение в Python 3»).
Python Tricks Дэна Бейдера
Короткая и приятная книга Дэна Бейдера Python Tricks: A Buffet of Awesome Python Features («Приёмы Python: набор потрясающих функций Python») — отличная отправная точка для начинающих и программистов, желающих больше узнать о том, как писать питонический код.
С Python Tricks вы изучите шаблоны написания чистого идиоматичного кода Python, лучшие практики для написания функций, эффективное применение функционала объектно-ориентированного программирования Python и многое другое.
Effective Python Бретта Слаткина
Effective Python («Эффективный Python») Бретта Слаткина — это первая книга, которую я прочитал после изучения синтаксиса Python. Она открыла мне глаза на возможности питонического кода.
В Effective Python содержится 90 способов улучшения кода Python. Одна только первая глава Python Thinking («Мыслить на Python») — это кладезь хитростей и приёмов, которые будут полезными даже для новичков, хотя остальная часть книги может быть для них трудной.
Fluent Python Лучано Рамальо
Если бы у меня была только одна книга о Python, это была бы книга Лучано Рамальо Fluent Python («Python. К вершинам мастерства»). Рамальо недавно обновил свою книгу до современного Python. Сейчас можно оформить предзаказ. Настоятельно рекомендую сделать это: первое издание устарело.
Полная практических примеров, чётко изложенная книга Fluent Python — отличное руководство для всех, кто хочет научиться писать питонический код. Но имейте в виду, что Fluent Python не предназначена для новичков. В предисловии к книге написано:
«Если вы только изучаете Python, эта книга будет трудной для вас».
У вас может сложиться впечатление, что в каждом скрипте на Python должны использоваться специальные методы и приёмы метапрограммирования. Преждевременная абстракция так же плоха, как и преждевременная оптимизация.
Опытные программисты на Python извлекут из этой книги большую пользу.
А мы поможем вам прокачать скиллы или с самого начала освоить профессию в IT, актуальную в любое время:
- Профессия Fullstack-разработчик на Python
- Профессия Data Scientist

Краткий каталог курсов и профессий
Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
- Профессия iOS-разработчик
- Профессия Android-разработчик
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
- Курс «Алгоритмы и структуры данных»
- Профессия C++ разработчик
- Профессия Этичный хакер
А также
Сравнение стандарта PEP8 и «Чистого кода» Роберта Мартина
Привет, Хабр! Признаюсь, честно, за время моего отсутствия я успел по вам соскучиться.
Прежде чем начинать изложение материала, позвольте рассказать небольшую историю, вдохновившую написать эту статью.
Был совершенно обычный день, когда мне в обеденное время написал в ВК знакомый с предложением пройти собеседование на должность разработчика на языке Python. Вакансия очень сильно заинтересовала, поскольку у меня есть большой интерес развиваться в этом языке. Пообщавшись с менеджером, сбросил ему резюме и прикрепил небольшой проект web-серверного приложения.
Главный разработчик провёл ревью и пришёл к выводу, что мне пока рано занимать такую вакантную должность. Вместе с этим HR отправил рекомендации разработчика, как и в каком направлении можно развиваться. Одно из них – чтение книги «Чистый код» под авторством Роберта Мартина
Я сначала не придал особого значения этой книге. За время обучения программированию на Python мне много рекомендовали что почитать. Что-то мне нравилось, что-то нет. Но здесь всё решил один случай.
Через три дня после собеседования я поехал на крупнейшую IT конференцию на Урале DUMP2022. Там познакомился со многими практикующими разработчиками в том числе из этой компании. Какова была моя радость, когда на одной из секций докладчик отметил мой вопрос как лучший, а подарком как раз стала эта книга.
Я понял, что это был знак. Мне действительно надо было прочитать эту книгу. И как оказалось не зря.
Нет, эта статья не очередной обзор, на парадигму автора. Это статья о сравнении двух стандартов PEP8 и «Чистого кода». Вместе с вами я посмотрю чем отличаются эти два стандарта между собой, в чём их сходство. Полученные знания углубят понимание фундаментальных принципов программирования и возможно повлияют на стиль оформления кода.
О «Чистом коде»
Книга Роберта Мартина перевернула мои взгляды о программировании на 180 градусов. До прочтения книги я не задумывался о том, что надо грамотно именовать переменные, грамотно оформлять функции, классы, дизайнерить архитектуру приложения. Про написание юнит тестов вообще промолчу. Всегда считал, что знание юнит тестов больше нужны тестировщику, а не разработчику. Какой же я наивный!
Итогом вышло полное игнорирование архитектуры кода, тестов и так далее. В общем теперь понятно, почему мне отказали в должности.
Когда закончил чтение книги, то понял, что парадигма Чистого Кода является стандартом, к которому стремятся придерживаться крупные IT компании города Екатеринбург (напр. ТОЧКА или СКБ-КОНТУР). И притом совершенно не важно на каком языке я программирую.
Автор пишет код на языке Java. К слову сказать, я не нашёл в интернете какие-либо стандарты (вроде PEP8 в Python), которые могли бы подойти для написания качественного кода на той же Java. Поэтому с осторожностью говорю, что «Чистый код» уже является в какой-то степени набором требований, к которым начинающему разработчику стоит присмотреться. И даже не важно соглашается ли он в полной мере с позицией автора или нет. Тут важно смотреть на альтернативные взгляды о проектировании кода и решать для себя какой подход наиболее подходящий, чтобы читатель кода меня правильно понял.
О стандарте PEP8
Если парадигма Clean Code является стандартом для языка Java, то в Python главным документом, по которому пишется качественный код является PEP8.
За основу написания документа взяты рекомендации создателя языка Python Гвидо ван Россума и дополнения Паула Барри. Программы, написанные по PEP8 читаются в едином стиле и его способен понять каждый Python разработчик. Использование стандарта при разработке программы можно достичь согласованности и единство кода. Я согласен с мнением автора, что согласованность кода со стандартом очень важна. Ведь меня читают другие люди.
Методика сравнения стандартов.
В качестве основного метода сравнения я выделил несколько ключевых слов, встречающиеся в PEP8 и в Чистом коде. Таким образом получился список из 8 пунктов:
- Переменные
- Функции
- Аргументы функции
- Комментарии
- Обработка ошибок
- Юнит тесты
- Классы
- Модули и системы
Переменные
Переменные находятся на самом низком уровне в программировании. Наверное, каждый согласится, что большая часть программы состоят из переменных. И для того, чтобы люди меня поняли, следует грамотно их описывать. Вот как описывают переменные эти два стандарта
CLEAN CODE
- Переменные описываются именем существительным
- Для грамотного описания переменной разработчику следует задать самому себе следующие вопросы:
Для чего они используются?
Какую роль они выполняют?
Как они используются в дальнейшем?
- Использование стандартной номенклатуры, там где это необходимо. Например, если мы используем декоратор
- Использование однозначных имён
PEP8
- Переменные отражают то, где они используются, а не что реализуют.
- Стандарт предполагает использование переменных в разных стилях
Наиболее предпочтительные для стандарта стили:
1) Одиночная маленькая буква (например «i»)
2) Одиночная заглавная буква (например «A»)
3) Слово в нижнем регистре (например «apple»)
4) Слова из маленьких букв с подчёркиваниями (‘one_two_three’)
5) Заглавные букв (СapWords, CamelCase) (например: OneTwoThree)
6) Переменные с префиксами (например: _one)
3) Следует избегать назначение в качестве переменных символы l (строчная буква эль), O (заглавная латинская буква «o») и I (латинская буква «ай»).
Выводы по блоку «Переменные»
Исходя из полученной информации на мой взгляд кажется верным факт, что CleanCode дополняет формат PEP8. Однако тут существует различные взгляды на использование префиксов в именовании переменных. Автор Clean Code утверждает, что в качественном коде префиксы не используются. Однако в Python переменные не делятся на публичные и приватные. Чтобы отделить одного от другого для именования переменных используется знак «земля» (_) перед приватным именем.
Таким образом получается закономерный вывод, что если Python разработчик хочет использовать парадигму «Clean Code» то ему следует оставить знак «_» для определения приватных методов, а во всех остальных случаях лишние префиксы исключить. Именование переменных лучше использовать начиная со слова в нижнем регистре или CamelCase стиле
Функции
В программировании функции находятся на втором уровне абстракции. Они описывают поведение переменных в динамике. Динамика определяется преобразованием входящих данных в исходящие. Входящие данные описываются аргументами (их сравнение будет чуть позже), а исходящие данные с помощью встроенного оператора return.
Примером реализации функции на языке Python является следующий код:
def function(arg1, arg2): newValue = arg1 + arg2 return newValueВ приведённом коде название функции определяется словом, идущим за def после пробельного символа. В скобках описываются аргументы, которые она принимает. И результатом выполнения данной функции является некоторое новое значение. Стоит также отметить что представленный код считается плохим с точки зрения дизайна, но хорошим в плане объяснения и понимания функции. Далее сравниваем стандарты.
CLEAN CODE
- Функция описывается глагольной формой и служит для описания поведения переменных.
- Автор рекомендует называть функцию так, чтобы она выполняла только одно действие. Эта рекомендация сопоставима с принципами SOLID.
- Размер функции ограничивается 20 строками в ширину и 120 символами в длину
- Не рекомендуется использовать дублирующий код.
- Не рекомендуется возвращать пустые значения в операторе return.
PEP8
- Рекомендуется использовать такой же стиль написания, как и при именовании переменных. Например, если мы называем переменные в стиле CamelCace, следовательно и функции мы называем в CamelCase.
- Для отделения одной функции от другой рекомендуется использовать 4 пустых строки
- Длина строки ограничивается максимум 79 знаками
Выводы по блоку «Функции».
По оформлению функций тоже видно, что сравниваемые стандарты сопоставимы и в какой-то степени дополняют друг друга. Различие описывается правилами оформления. То есть, если Мартин определяет длину кода 120 символами, то по PEP8 она ограничивается 79. Но тут мне понравилась рекомендация Мартина. Он говорит, что правильно написанная функция по оформлению сопоставима с форматом монитора на ПК. В идеале, конечно, чтобы написанный код не выходил за рамки монитора.
Аргументы функции.
Аргументы функции я немного затронул в предыдущем разделе. Здесь я немного расширю их понимание. По сути своей аргументы — это часть функции. Они являются исходными данными для их преобразования в другие данные. Ниже рассмотрим как аргументы понимает Clean Code и PEP8
CLEAN CODE
- Чем меньше аргументов принимает функция, тем легче она читается.
- Считается, что, если функция принимает три и более аргументов – это плохая функция.
- . Не допускается использовать Null (None) в качестве аргумента функции.
PEP8
- Вызов аргумента не должен отделяться пробельным символом между именем функции и значением аргумента.
- Не допускается написание пробелов, если явно задано значение аргумента.
- Не допускается использование зарезервированных слов в качестве аргументов функции.
Выводы по блоку «Аргументы функции».
В целом разделы из CLEAN CODE и PEP8 также являются сопоставимыми. Примерно одинаковую по объёму информацию можно найти как в CLEAN CODE, так и в PEP8.
Комментарии
Комментарии являются главным инструментом, описывающим программное обеспечение ВНЕ кода. Ещё в университете меня учили тому, что к любому коду нужно писать комментарий. Каково было моё удивление осознать, что в реальных проектах чем меньше комментариев, тем лучше.
В языке Python комментариями является текст, который начинается либо с решётки (#), либо с тройных кавычек. Примеры комментариев представлены ниже.
#Комментарий def function(arg1, arg2): """ Это тоже комментарий :param arg1: :param arg2: :return: """ newNumber = arg1 + arg2 return newNumber.Далее рассмотрим как видят комментарии авторы CLEAN CODE и PEP8.
CLEAN CODE
- Любой комментарий в коде является предвестником того, что он написан плохо.
- Они очень часто содержат неправдивую информацию, их достаточно сложно поддерживать и обновлять.
- Они не отражают точное поведение функции
- Если у программиста появляется мотивация писать комментарий, то это является первым признаком, что он пишет плохой код. Исключениями могут быть комментарии, содержащие авторское право и комментарии, начинающиеся с флагом #TO DO:
PEP8
- Комментарии, противоречащие коду, хуже, чем отсутствие комментариев.
- Комментарии должны являться законченными предложениями.
- Старайтесь реже использовать подробные комментарии.
Выводы по блоку «Комментарии».
В Clean Code уделяется комментариям целая глава. Исходя из этого автор разбирает их более подробно, чем в PEP 8. Если Вы новичок в программировании, то вероятнее всего знать правила оформления комментариев по PEP8 будет достаточно. Но если выходить на реальные проекты, то вместе с PEP8 следует учитывать правила комментирования по Clean Code.
Обработка ошибок
Обработка ошибок описывается стандартным набором правил, которые предусматривают, что программист заранее знает, что программный код вернёт ошибку. Примером, описывающим применение этого инструмента служит блок try.
Далее представлю пример использования этого блока на языке Python. За основу я взял задачу из тренажёра CODE WARS Найти задачу можно тут. Кстати, вот пример того, как я её реализовал.
def find_function(func, arr): res = [] for value in func: try: if value.__name__ == '': for arr_value in arr: if value(arr_value): res.append(arr_value) except AttributeError: continue return resЗдесь применяется исключение для того, чтобы цикл смог без ошибки AttributeError завершить свою работу. Этот код был написан до прочтения Clean Code. Так что не судите слишком строго. Теперь рассмотрим что предлагают авторы CleanCode и PEP8.
CLEAN CODE
- Очень желательно, чтобы ошибки не пришлось обрабатывать в коде.
- Любое исключение нарушает логику работы интерпретатора.
- Если не понять причины возникновение ошибок, то это в будущем приведёт к неработающему коду.
- Обработка исключений является нарушением принципов SOLID
- Если программист понимает, что вызова try не избежать то автор рекомендует придерживаться следующих правил:
- Перед вызовом функции необходимо её проверить на ошибки.
- Все ошибки обрабатывать с помощью блока ‘try’. Условные операторы типа “if-else” при обработке исключений лучше не использовать.
- Применение «try» лучше всего подходит для тех случаев, когда нужно исключить ненужный код.
- Использовать try необходимо в том коде, который обладает наибольшей уязвимостью.
PEP8
- Стандарт налагает ограничение на использование блоков TRY в программировании. Использование исключений допускается только в двух случаях:
- Если обработчик выводит пользователю всё о случившейся ошибке; по крайней мере, пользователь будет знать, что произошла ошибка.
- Если нужно выполнить некоторый код после перехвата исключения, а потом вновь «бросить» его для обработки где-то в другом месте.
- Авторы стандарта рекомендуют заключать в каждую конструкцию try. except минимум кода. Это необходим для того, чтобы легче отлавливать ошибки.
Выводы по блоку «Обработка ошибок».
Оба автора рекомендуют как можно меньше использовать инструмент по обработке ошибок и исключений в коде. Так же как и в предыдущем разделе в Clean Code автор рассматривает больше случаев, в котором допускается обработка ошибок. Поэтому вывод по данному разделу такой же как и по предыдущему. Если использовать Python для обучения языку, то стандарты PEP8 must have. Если вы претендуете на должность Junior разработчика, то знаний PEP8 будет уже недостаточно для прохождения собеседования. Желательно хотя бы знать базовые правила Clean Code.
ЮНИТ ТЕСТЫ
Я был слегка удивлён, когда при трудоустройстве на позицию Junior разработчика компания требует знать хотя бы основы работы Юнит Тестов. Всегда думал, что эта работа больше требуется тестировщикам, а не разработчиком. В данном разделе также следует знать, что разработка юнит-тестов не описывается стандартом PEP8.
По крайней мере мне такой информации найти не удалось. А вот, что пишет о них автор CLEAN CODE.
CLEAN CODE
- Наличие юнит-тестов по степени важности находятся наравне с функциями, описывающими логику программного кода.
- Тесты необходимы для того, чтобы разработчик программного обеспечения смог убедиться в том, что его код работает так, как он ожидает.
- Написание грамотных тестов описываются правилами TDD (Test Driven Development) и состоит из трёх пунктов:
- Пока нет юнит тестов, код нельзя допускать до массового потребителя
- Тестов всегда мало. Поэтому чем больше юнит тестов, тем больше уверенности в корректности работы программы.
- Если хотя бы один тест не удовлетворяет требованиям программы, то такую программу нельзя допускать до массового потребителя.
- Юнит тесты должны быстро выполняться.
- Предполагается, что они очень часто запускаются.
- Они работают независимо друг от друга.
- Они успешно запускаются на любой платформе и операционной системе.
- Тесты выполняются без вмешательства их разработчика.
Выводы по блоку «Юнит Тесты».
В стандарте PEP8 не описываются правила по разработке юнит тестов. Для успешного прохождения собеседования к уже знакомому PEP8 надо посмотреть как пишутся юнит-тесты на Python. Если в PEP8 не уделяется внимание юнит тестам, то за концептуальную основу можно взять CLEAN CODE.
Классы
Классы являются основой объектно-ориентированного программирования. Благодаря им мы можем разрабатывать сложные системы. В основу класса входят методы (они же описываются функцией). Примером класса, может являться например Корабль. Он обладает определённым набором функций, которые позволяют им управлять.
Далее я приведу пример класса на языке Python. Данный класс является решением Этой задачи. Это не идеальное решение. Уверен у вас будет лучше)
class Ship: def __init__(self, draft, crew): self.draft = draft self.crew = crew def is_worth_it(self): draft_crew = self.crew * 1.5 worth = self.draft - draft_crew return False if worth < 20 else TrueОпишу как видят классы авторы CLEAN CODE и PEP8.
CLEAN CODE
- Классы именуются именами существительными.
- Чем длиннее название класса, тем меньше количество функций он в себе содержит.
- Класс должен соответствовать принципам SOLID.
- В классе содержится подробное описание его зоны ответственности.
- Класс должен содержать малое количество переменных и функций.
- Устройство класса:
- Сначала объявляются публичные атрибуты класса.
- Потом идут приватные атрибуты класса.
- Затем идут публичные функции.
- Далее приватные.
PEP8
- Имена классов должны обычно следовать соглашению CapWords.
- PEP8 предполагает использование self в качестве первого аргумента метода экземпляра объекта.
- Чтобы избежать конфликтов имен с подклассами, используйте два ведущих подчеркивания (читайте префиксы).
- Обязательно решите, каким должен быть метод класса или экземпляра класса (далее - атрибут) — публичный или непубличный.
Выводы по разделу "Классы"
В Python организация классов разрабатывается несколько иначе, чем на Java. Поэтому к применению Clean Code в Python разработке следует подходить с особой осторожностью. Например, если в языке Java надо явно определять тип класса (public, private, protected), то Python такой возможности не имеет. Поэтому применение префиксов внутри класса становится оправданным, хотя в Clean Code их использование явно не приветстывуется.
Системы
Система - представляет собой набор из множества классов. Любой класс является частью системы. Примером большой системы может являться работа города. Управлять целым городом не под силу одному человеку. Поэтому у любого мэра есть определённый штат сотрудников, у которых есть свои обязанности. Если говорить, например, про Екатеринбург, то у главы города в подчинении находятся руководители администрации районов. Руководители районов с одной стороны находятся в подчинении главы Екатеринбурга, с другой стороны имеют свободу независимо от него решать поставленные сверху задачи.
В стандарте PEP8 работа системы описывается стандартами работы модуля
В программной реализации системой могут являться готовые модули. Их программную реализацию будет достаточно трудно описать, поэтому здесь будет приведено только сравнение взглядов авторов.
CLEAN CODE
- Необходимо разделять процесс проектирования системы от её эксплуатации.
- К этим процессам надо подходить с разных позиций. Можно рассмотреть процесс проектирования на примере строительства отеля. Когда его строят, то в процесс задействуются совершенно разные механизмы. Эти механизмы описываются единым общим процессом «строительство». Когда люди начинают его эксплуатировать, то здесь уже нанимается персонал, который отвечает не за строительство, а за обслуживание. Иными словами, процесс строительства и обслуживания никак не связаны между собой, за исключением только разве что наличия общего объекта.
- Программные продукты, которые не учитывают разделение имеют шанс иметь проблемы с выполнением тестов.
- Без разделения программных систем нарушается принцип единственной ответственности.
- Следует отделять идейный код от работающего кода.
- С ростом кода становится сложнее поддерживать системы.
PEP8
- Модули должны иметь короткие имена, состоящие из маленьких букв.
- Можно использовать символы подчеркивания, если это улучшает читабельность.
- Новые модули и пакеты должны быть написаны согласно стандарту PEP8, но если в какой-либо уже существующей библиотеке эти правила нарушаются, предпочтительнее писать в едином с ней стиле c с программой, нарушающей стандарты.
Выводы по блоку "Системы".
Разработку систем авторы стандартов видят с разных точек зрения. Если авторы Clean Code видят систему как совокупность объектов с устоявшимися связями, то по PEP8 аналогом такой системы является модуль. В данном разделе я тоже склоняюсь к мнению, что использовать CleanCode при проектировании системы надо с осторожностью. Главное не нарушать принципы PEP8.
Общие выводы
Данный сравнительный анализ описывает далеко не все аспекты программирования. Он весьма поверхностный. Однако полученные выводы помогут дать ответ на вопрос: что можно использовать из книги Clean Code для разработки на Python и что использовать с осторожностью. Данная статья представляет взгляд новичка на проблему проектирования. Я понимаю, что для многих даже профессионалов эта тема даётся нелегко. Поэтому буду рад замечаниям и дополнениям. Спасибо за внимание!
- Python
- Программирование
- Совершенный код
- Проектирование и рефакторинг