Есть ли возможность отредактировать файл robots.txt?
К сожалению, в данный момент такой возможности в Тильде нет.
Единственный вариант внести кардинальные изменения — экспортировать проект на собственных хостинг и произвести нужные изменения.
Если вы хотите добавить или убрать disallow, перейдите в Настройки нужной вам страницы → Facebook & SEO → Отображение в поисковой выдаче → Задать специальные мета-данные → поставьте или снимите галочку «Запретить поисковикам индексировать эту страницу» → сохраните изменения.
Похожие вопросы
- Можно ли давать отдельный доступ пользователям к проектам?
- Наблюдаются ли у вашего сервиса проблемы из-за блокировок Роскомнадзором?
- Как сделать бэкап проекта на Тильде?
- Выписался счёт для тарифа Бизнес на 15000 рублей без скидки. Почему?
- Где находится Ваш ЦОД?
Как убрать disallow в robots.txt?
Чтобы открыть страницы для индексации, необходимо перейти в настройки нужной вам страницы → Facebook & SEO → Отображение в поисковой выдаче → Задать специальные мета-данные → и снять галочку «Запретить поисковикам индексировать эту страницу» → «Сохранить изменения».
Похожие вопросы
- Поисковики не видят мой сайт, что делать?
- Как добавить robots.txt и sitemap.xml
- Как сделать страницу ошибки 404?
- Как добавить (назначить) тег H1?
- Как добавить ключевые слова для сайта?
Этот ответ был вам полезен?
Файл robots.txt
robots.txt — это текстовый файл, который содержит инструкции для поисковых роботов. Содержимое файла представлено одной или более групп директив, которые позволяют управлять индексацией сайта. Помимо индексации, существует возможность добавления служебной информации, которая помогает поисковым системам. Грамотно составленный файл robots.txt позволяет ускорить индексацию сайта, уменьшить нагрузку на сервер и улучшить поведенческие факторы. В данной статье рассматриваются: создание и редактирования файла robots.txt, синтаксис директив, расположение на хостинге, расположение в панелях управления популярных CMS, генерация. Файл robots.txt является файлом исключений и правил для поисковых роботов. Данный стандарт принят консорциумом всемирной паутины World Wide Web Consortium (W3C) 30 июня 1994 года. Следование стандарту является полностью добровольным, однако некоторые поисковые системы указывают на возможную некритическую проблему при отсутствии файла robots.txt.
Создание файла robots.txt
Чтобы создать файл robots.txt можно открыть блокнот и ввести следующие директивы:
сохранить файл с именем:
Имя файла обязательно должно быть написано прописными (маленькими) буквами.
Указанные директивы буквально расшифровываются так:
- для всех поисковых роботов,
- открыть для индексации весь сайт.
Полученный файл можно загрузить в корень сайта и номинально решить проблему валидации, которая связана с отсутствием robots.txt.
Зачем нужен файл robots.txt
Файл robots.txt содержит правила-исключения, а также служебные директивы для поисковых роботов. Правильная настройка позволяет решать основные задачи для корректной индексации сайта:
- закрытие сайта/страниц/файлов,
- указание служебной информации.
Полное закрытие веб-проекта чаще всего реализуется в случаях:
- мультирегиональной настройки ПС для поддоменов,
- создания тестового сайта-клона.
Закрытие страниц и файлов сайта реализуется в случаях, когда они:
- дублируют контент,
- содержат служебные данные,
- содержат тестовые данные,
- не несут пользы в индексе ПС.
Указание служебной информации
Ранее, для ПС Яндекс можно было указывать адрес основного хоста (директива host — неактуально), задержку между обращениями бота к сайту (crawl-delay — неактуально). Сегодня достаточно указывать адрес sitemap.xml, директиву host вытеснили канонические адреса.
Где находится файл robots.txt
Файл всегда должен располагаться на хостинге, в корне сайта. Например, у нас это выглядит так:
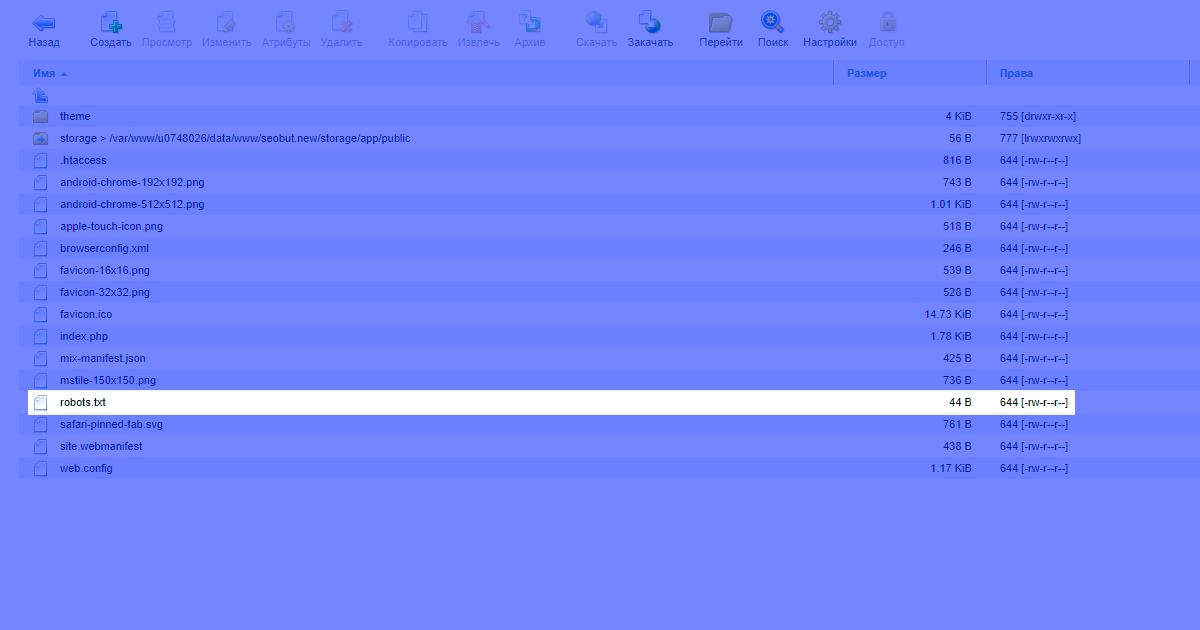
Чтобы проверить текущее содержимое файла на сайте, в адресной строке следует ввести:
где mysite.ru — доменное имя проверяемого сайта
Редактирование файла robots.txt
Для того чтобы отредактировать файл роботс, следует:
- зайти на хостинг,
- найти в корне сайта файл с именем robots.txt,
- если данный файл отсутсвует, создать его,
- открыть любым редактором текста,
- написать необходимые инстуркции,
- сохранить,
- загрузить с заменой.
Если ваш сайт на готовой cms и файлом робота управляет плагин, то можно столкнуться с проблемой, когда редактирование файла вручную не к чему не приводит.
Расположение robots в CMS
Файл робота в некоторых системах управлениях сайтами можно редактировать из административной панели. Однако, существуют ситуации, когда файл для роботов подменяется на лету специальными плагинами . Поэтому изменение файла на строне хостинга может не работать. В таком случае следует проверить наличие SEO-плагинов и их настроек.
Расположение robots в wordpress
В панели управления wordpress нет отдельного пункта меню для создания и редактирования файла robots.txt. Поэтому его модификацию можно осуществлять 2 способами:
- редактирование с хостинга,
- редактирование с использованием плагинов.
Редактирование robots.txt через плагин yoast
Рассмотрим создание и редактирование файла robots.txt в wordpress с помощью плагина yoast. Для того, чтобы создать или редактировать файл в данном плагине необходимо:
- установить плагин,
- перейти в настройки плагина,
- выбрать пункт инструменты,
- редактор файлов.
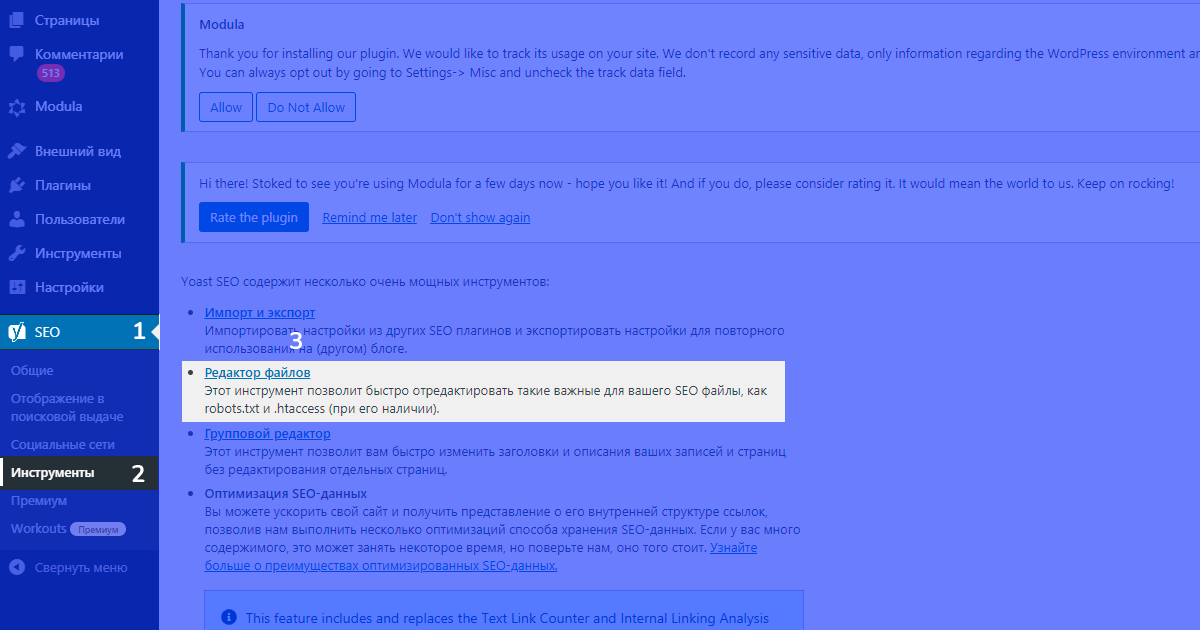
В случае, если файл робот создается через плагин впервые, yoast сообщит, что файл отсутсвует, несмотря на то, что файл может существовать. Тем не менее, если планируется редактирование файла robots из административной панели wordpress, следует нажать на кнопку создания:
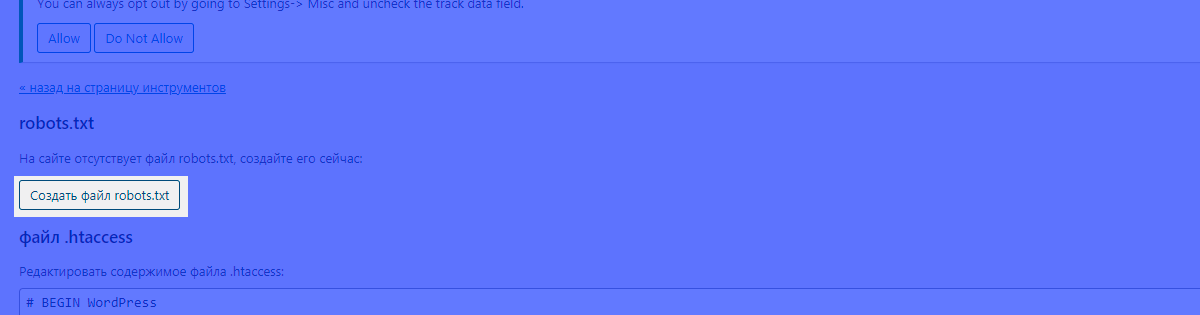
После нажатия кнопки можно увидеть базовое содержимое файла, которое можно редактировать:
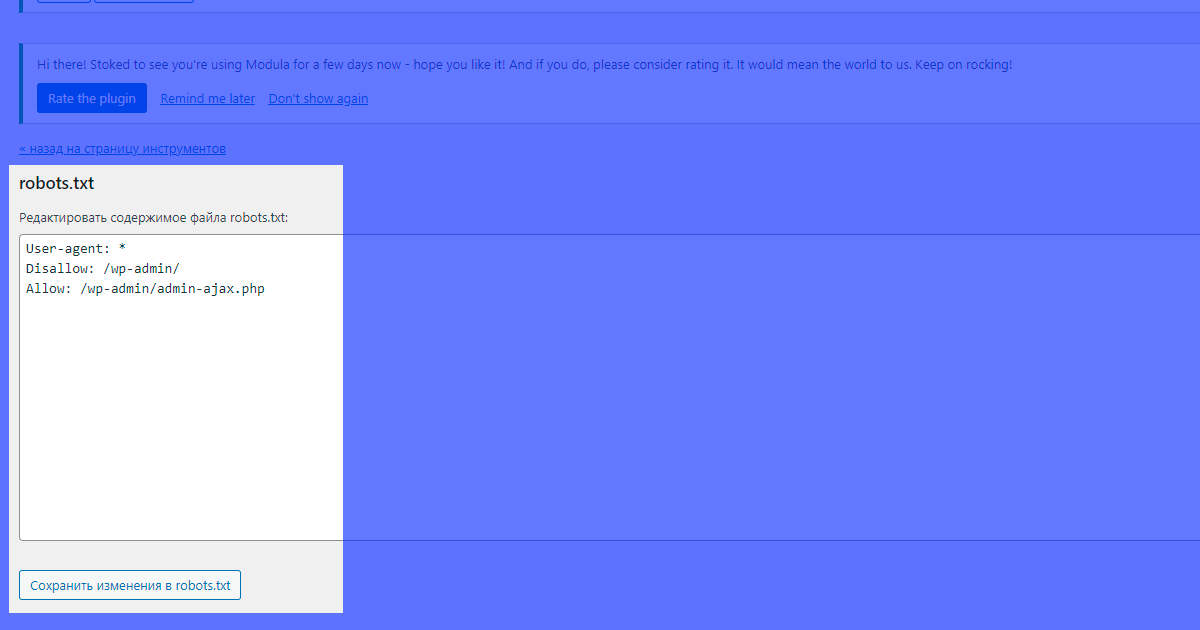
После редактирования следует сохранить изменения.
Расположение robots.txt в tilda
Tilda самостоятельно генерирует файл робота и при этом не дает возможности редактирования, о чем поддержка сообщает в своей вопросно-ответной системе. Сегодня единственное решение для редактирования файла robots.txt — экспорт проекта на собственный хостинг. После экспорта появится возможность управления файлом.
Расположение robots.txt в 1С-Битрикс
В 1С-Битрикс доступ к файлу robots из админ-панели существует. Для того, чтобы управлять файлом робота следует пройти по пути:
Маркетинг > Поисковая оптимизация > Настройка robots.txt
Проверка файла роботс
Для проверки файлов робота у поисковика Яндекс есть валидаторы:
- Проверка robots Яндекс,
- Проверка robots Google (инструмента нет).
Синтаксис
Общий синтаксис для записей файла роботс:
Правила для файла и синтаксиса
Правила для файла
- На сайте может быть только 1 такой файл;
- Файл должен располагаться в корне сайта;
- Название файла работа пишется прописными (маленькими буквами): robots.txt (Robots.txt, ROBOTS.txt неверные названия);
- Размер файла robots не должен превышать 500 КБ (500 килобайт);
- Кодировка файла должна быть UTF-8 (которая включает коды символов ASCII), другие наборы символов использовать нельзя;
- Правила указанные в файле robots действительны только для того хоста, на котором расположен данный файл;
- Файл robots должен быть доступен (код ответа сервера при обращении должен быть 200 ОК).
Правила для синтаксиса
- Каждая новая директива должна начинаться с новой строки;
- Перед директивой не должно быть пробелов/спецсимволов;
- Для комментариев используется спецсимвол: #;
- Каждая новая строка с комментарием должна начинаться со специсимвола: #;
- Файл robots без содержимого разрешает индексацию всего сайта;
- Все данные для одной директивы должны размещаться на одной строке;
- Пустая строка завершает блок инструкций для текущего User-Agent;
- При отсутсвии пустой строки, разделяющей User-Agent’ов, учитываться будет только первый;
- При указании блоков правил для User-Agent: * и User-Agent: YandexBot, будет использован User-Agent: YandexBot ;
- Все директивы проверяются сверху вниз по порядку.
- Проверка данных файла robots.txt;
- Проверка метаданных на страницах .
Данные для роботов могут отменяться последним изменением, а так как robots.txt проверяется первым, то если в файле robots.txt указано:
#для всех роботов закрыть весь сайт
User-Agent: *
Disallow: /
но при этом на всех страницах сайта будет указано:
тогда сайт может быть проиндексирован.
Директивы robots.txt
Директивы определяют задачи, которые требуется решать с помощью файла robots.txt.
| Директива | Функция |
|---|---|
| User-Agent | Указание имени поискового робота |
| Allow | Открыть для индексации |
| Disallow | Закрыть для индексации |
| Sitemap | Указание адреса для карты сайта (sitemap.xml) |
| Clean-param | Указание роботу, что страницы имеют параметры: GET, utm (ТОЛЬКО ДЛЯ ЯНДЕКС) |
| Crawl-delay | Указание в секундах скорость загрузки одной страницы до начала загрузки следующей (неактуально) |
| Host | Указывает основную версию сайта (может встречаться, однако сегодня неактуально) |
Стоит обратить внимание на директивы Host, Crawl-delay — не поддерживаются с 2018 года, а директива Clean-param используется только ПС Яндекс.
Директива User-Agent
Директива User-Agent служит указателем правил для конкретного поискового агента. Примеры использования директивы User-Agent для различных поисковых роботов:
#Для всех поисковых роботов
User-Agent: *
#Основной робот Яндекса
User-Agent: Yandex
#Основной робот Google
User-Agent: Googlebot
#Основной робот Google новостей
User-agent: Googlebot-News
Поисковых агентов существует большое множество. Некоторые поисковые роботы могут игнорировать инструкции, которые указаны в файле роботс. Список имен ботов для поисковых систем Yandex и Google, которые не игнорируют правила файла robots.txt, использование которых позволит производить более тонкую настройку индексации.
Директива Allow
Директива Allow задает правила для открытия страниц и(или) их содержимого для индексации. Примеры использования директивы Allow:
#для всех роботов открыть весь сайт
User-Agent: *
Allow: /
#для робота Яндекс открыть страницу catalog и все вложенные url
User-Agent: YandexBot
Allow: /catalog
#для всех роботов открыть страницу catalog/ и все вложенные адреса
User-Agent: YandexBot
Allow: /catalog/
Директива закрытия Disallow
Disallow — одна из самых частоиспользуемых директив, которая запрещает индексацию поисковыми роботами. Примеры самых частоиспользуемых конструкций:
#для всех роботов закрыть весь сайт
User-Agent: *
Disallow: /
#запретить индексацию для основного бота Яндекс
User-Agent: YandexBot
Disallow: /
#закрыть файл с определенным расширением
User-Agent: *
Disallow: /upload/*.jpg
#закрыть любой url который содержит slovo
User-Agent: *
Disallow: *slovo*
#закрыть все url с параметрами
User-Agent: *
Disallow: *?*
#закрыть get параметр
User-Agent: *
Disallow: *?get=*
#закрыть раздел catalog
User-Agent: *
Disallow: /catalog
#закрыть конкретную страницу page
User-Agent: *
Disallow: /page$
Зачем закрывать определенного бота
Закрытие определенного бота может быть использовано в различных ситуациях. Рассмотрим пример на гипотетическом проекте с региональной привязкой к поддоменам.
Дано: основной сайт с доменным адресом:
Который имеет поддомены со соответствующей привязкой городов:
Для Яндекса, в вебмастере можно указать каждому поддомену свой город, и добавить возможность индексации (для каждого поддомена свой файл robots.txt):
Для Google такое решение окажется непонятным, что приведет к выбрасыванию поддоменов из выдачи. Это связано с городами России, которые Гугл определяет некорректно. Поэтому для каждого поддомена и Googlebot (основного индексирующего бота Google), можно добавить запись:
В результате для каждого поддомена (для каждого свой файл робота) получится подобный robots.txt:
При этом, для основного домена запись robots.txt будет выглядеть так:
Таким образом, поисковик Яндекс будет индексировать только поддомены, а Google только основной домен и не будет создавать проблем.
Директива Sitemap
Директива sitemap необходима для указания карты сайта и используется в таком формате:
#Пример с одной картой
User-Agent: *
Allow: /
Sitemap: https://seobut.com/sitemap.xml
Обычно для современных проектов создаются составные карты, для которых достаточно указать основную. Но для понимания допустим вариант указания нескольких карт, например:
#пример указания нескольких карт
User-Agent: *
Allow: /
Sitemap: https://seobut.com/sitemap.xml
Sitemap: https://seobut.com/stitemap-blog.xml
Для показа контента сайта в ленте Google news генерируется и указывается отдельная карта сайта со своими правилами, тогда файл robots может выглядеть так:
#обычная карта
User-Agent: *
Sitemap: https://seobut.com/sitemap.xml
#карта для google новостей
User-Agent: Googlebot-News
Allow: /
Sitemap: https://seobut.com/sitemap-news.xml
Директива Clean-param
Только для поисковой системы яндекс
Директива Clean-param необходима для снижения нагрузки на сайт, ускорения индексации полезного контента с помощью исключения страниц-дублей с одинаковым и(или) бесполезным контетом. Чаще всего исключаемые страницы на сайте возникают из-за наличия: страниц результатов поиска, utm меток, страниц с GET-параметрами. Данная директива работает только ботами Яндекс, для Google используются канонические адреса и(или) директива Disallow.
Синтаксис директивы Clean-param:
[p] — неизменный игнорируемый параметр,
[&p1&p2&pN] — дополнительные игнорируемые параметры,
[path] — адрес раздела, который содержит параметры,
Например, необходимо на каждом разделе закрыть все страницы с umt-метками:
User-Agent: Yandex
Clean-param: utmstat
Таким образом будут закрыты все страницы, которые содержат параметр utmstat, например:
seobut.com/?utmstat=.
seobut.com/publications/?utmstat=.
seobut.com/publications/fail-robots/?utmstat=.
Рассмотрим пример закрытия поисковых страниц сайта через Clean-param. Имеется страница поиска с запросом seo:
Как можно увидеть, запрос состоит из двух параметров. Именно эти 2 параметра станут маркерами закрытия индексации, которую можно реализовать так:
User-Agent: Yandex
Clean-param: search_string&search_types /search/search_do/
Важно понимать, что амперсант (&), в контексте данной инструкции, означает «и». То есть, чтобы поисковая система исключила подобные страницы из индекса, робот должен встретить оба параметра в строке URL.
Правильный robots.txt в 2022
Правильный файл robots.txt определяется архитектурой адресации на сайте, а также наличием или отсутствием различных параметров: get, utm. Самый правильный файл должен содержать минимум директив. Например, в нашем случае, правильный файл robots выглядит так:
User-Agent: *
Allow: /
Disallow: /?
Disallow: /*?
Disallow: /policy
Sitemap: seobut.com/sitemap.xml
Здесь для всех поисковых роботов сайт полностью открывается для индексации, указывается карта сайта, при этом закрываются страницы с параметрами и политика.
В зависимости от организации архитектуры веб-сайта, robots.txt могут отличаться. Сайты могут работать на готовой cms, либо на фреймворке, следовательно способы регулирования выдачи могут отличаться.
Правильный robots.txt wordpress
В базовом представлении плагин yoast генерирует такой файл:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Но вебмастера обычно используют расширенный вариант:
User-agent: * # для всех поисковиков
Disallow: /wp-admin # админка
Disallow: /wp-includes # базовая папка wp
Disallow: /wp-content/plugins # плагины wp
Disallow: /wp-content/cache # кеш wp
Disallow: /wp-json/ # файлы конфигурации
Disallow: /xmlrpc.php # XML-RPC старьё
Disallow: /readme.html # можно удалить
Disallow: /*? # GET-параметры
Disallow: /?s= # поиск
Allow: /wp-includes/*.css # открыть скрипты и стили
Allow: /wp-includes/*.js
Allow: /wp-content/plugins/*.css
Allow: /wp-content/plugins/*.js
Allow: /*.css
Allow: /*.js
Sitemap: https://seobut.com/sitemap.xml
Открытие файлов стилей и скриптов необходимо например для google. Гугл утверждает что умеет индексировать скрипты и стили, чем улучшает выдачу для пользователей.
Правильный robots.txt 1С битрикс
Внимательно отнеситесь к данным директивам, несмотря на то, что большее количество директив описано, если на 1С битриксе вносились правки в логику модулей, то некоторых директив может не хватать.
User-agent: * # правила для всех роботов
Disallow: /cgi-bin # папка на хостинге
Disallow: /bitrix/ # системные файлы битрикса
Disallow: *bitrix_*= # GET-запросы битрикса
Disallow: /local/ # папка с системными файлами битрикса
Disallow: /*index.php$ # дубли всех index.php
Disallow: /auth/ # авторизация
Disallow: *auth= # авторизация с любого раздела
Disallow: /personal/ # личный кабинет
Disallow: *register= # регистрация
Disallow: *forgot_password= # забыли пароль
Disallow: *change_password= # изменить пароль
Disallow: *login= # логин
Disallow: *logout= # выход
Disallow: */search/ # базовая страница поиска
Disallow: *action= # действия
Disallow: *print= # печать
Disallow: *?new=Y # новая страница
Disallow: *?edit= # редактирование страницы
Disallow: *?preview= # предпросмотр страницы
Disallow: *backurl= # страницы при переходе из админки
Disallow: *back_url= # страницы при переходе из админки
Disallow: *back_url_admin= # страницы при переходе из админки
Disallow: *captcha # все каптчи
Disallow: */feed # все фиды
Disallow: */rss # конкретный rss фид
Disallow: *?FILTER*= # здесь и ниже различные популярные параметры фильтров
Disallow: *?ei=
Disallow: *?p= #базовые страницы пагинации
Disallow: *?q= #базовые страницы поиска
Disallow: *?tags= #базовые страницы с тегами
Disallow: *B_ORDER=
Disallow: *BRAND= #опции фильтрации здесь и ниже
Disallow: *CLEAR_CACHE=
Disallow: *ELEMENT_ID=
Disallow: *price_from=
Disallow: *price_to=
Disallow: *PROPERTY_TYPE=
Disallow: *PROPERTY_WIDTH=
Disallow: *PROPERTY_HEIGHT=
Disallow: *PROPERTY_DIA=
Disallow: *PROPERTY_OPENING_COUNT=
Disallow: *PROPERTY_SELL_TYPE=
Disallow: *PROPERTY_MAIN_TYPE=
Disallow: *PROPERTY_PRICE[*]=
Disallow: *S_LAST=
Disallow: *SECTION_ID=
Disallow: *SECTION[*]=
Disallow: *SHOWALL=
Disallow: *SHOW_ALL=
Disallow: *SHOWBY=
Disallow: *SORT=
Disallow: *SPHRASE_ID=
Disallow: *TYPE=
Disallow: *utm*= # ссылки с utm-метками
Disallow: *openstat= # ссылки с метками openstat
Disallow: *from= # ссылки с метками from
Allow: */upload/ # открываем папку с файлами
Allow: /bitrix/*.js # открываем скрипты и изображения
Allow: /bitrix/*.css
Allow: /local/*.js
Allow: /local/*.css
Allow: /local/*.jpg
Allow: /local/*.jpeg
Allow: /local/*.png
Allow: /local/*.gif
Sitemap: https://seobut.com/sitemap.xml
Последняя директива Sitemap, содержит адрес нашей карты, не забудьте заменить путь.
Генераторы robots.txt
Генераторы файла robots.txt — инструменты, которые позволяют ввести вводные данные и получить готовый список директив, например:
- Генератор от pr-cy.ru
- Генератор от случайного агенства
- Генератор от случайного агенства-2
Однако, стоит понимать, что и каким образом закрывается на сайте. Без базового понимания директив, редактирование файла robots может быть чревато. Например, логичное с одной стороны закрытие GET-параметров, может привести к потери качественных страниц, которые уже занимают хорошие позиции в индексе. Другой пример — закрытие страниц пагинации, которые тоже хорошо могут отдаваться в поиске. Поэтому, до внесения изменений в robots с помощью генераторов, следует детально изучить выдачу, а также способы формирования контента на рабочем проекте.
В итоге
Файл robots.txt это текстовый файл, который содержит инструкции для поисковых роботов. Инструкции позволяют избежать склеек, уменьшить количество мусорных страниц в индексе, снизить нагрузку на сервер, ускорить индексацию страниц и решать различные логические и технические бизнес-задачи. Содержимое файла robots.txt определяет архитектурой роутов на сайте.
- Как создать robots.txt
- Зачем нужен robots.txt
- Где лежит robots.txt
- robots.txt в панелях CMS
- Где robots.txt в wordpress
- Редактирование robots.txt в wordpress
- Где robots.txt в tilda
- Где robots.txt в 1С-битрикс
- Проверка robots.txt
- Синтаксис robots.txt
- Правила robots.txt
- Директивы robots.txt
- Директива User-Agent
- Директива открытия Allow
- Директива закрытия Disallow
- Зачем закрывать определенного бота
- Директива Sitemap
- Директива закрытия Clean-param
- Правильный robots.txt в 2022
- Генераторы robots.txt
- Sitemap.xml — создается автоматически. Пользователь его не может добавлять или редактировать. Он не только содержит ссылки, но и транслирует поисковикам дополнительную информацию: дату последнего обновления, периодичность изменения страницы, приоритетность ссылок относительно других URL. Файл поддерживает размещение до 50 тыс. ссылок.
- Sitemap.html — простая страница формата html, которую можно создать самостоятельно. В ней размещаются ссылки на все страницы сайта. Она необходима для передачи ссылочного веса от одной веб-страницы другой. Ссылка на Sitemap.html указывается в футоре ресурса. По рекомендациям поисковика «Яндекс» лучше размещать в sitemap.html не более 3 тыс. ссылок.
- Зайти в «Настройки» и перейти в раздел «SEO».
- Выбрать вкладку «Отображение в поисковой выдаче», кликнуть по пункту «Задать специальные значения».
- Найти и отметить чекбокс «Запретить поисковикам индексировать страницу».
- Сгенерировать новую пустую страницу.
- Через панель управления выбрать «Заголовок», ввести «Карта сайта».
- В меню «Настройки» установить тег заголовка H1.
- Во вкладке «Все блоки» выбрать «Список страниц».
- Найти блок с наименованием «Оглавление IX06».
- Нажать кнопку «Контент» и отметить чекбоксы с доступными ссылками.
- Сохранить изменения.
- Открыть меню «Настройки», расположенное вверху редактора.
- В пунктах «Заголовок» и «Описание» прописать «Карта сайта html».
- В пункте «Адрес» указать sitemaphtml (без точек, пробелов и других знаков).
- Сохранить изменения, опубликовать карту.
- Открыть вкладку «Мои сайты».
- В правом углу карточки ресурса нажать на три вертикальные точки.
- Выбрать в контекстном меню раздел SEO.
- В меню кликнуть по вкладке «SEO-рекомендации».
- Добавить ресурс в поисковик через сервисы «Вебмастер» и Google Search Console.
- Подключить аналитические системы для мониторинга поведенческого фактора «Яндекс Метрика» и Google Analytics.
- Подключить SSL-сертификат для безопасного соединения.
- Создать страницу с кодом 404 при переходе на несуществующую страницу (один из поведенческих факторов, который позволяет задержать пользователя на ресурсе). На ней рекомендуется размещать кнопку «На главную».
- Зайти в созданные сайты.
- Нажать на три вертикальные точки в карточке.
- В главном меню выбрать вкладку SEO.
- Прокрутить перечень вниз до пункта «Запрет индексации».
- Отметить чекбокс «Запретить индексировать этот сайт».
- В меню «Настройки сайта» выбрать раздел «Еще».
- Найти в доступном перечне параметр «HTML-код для вставки внутрь Head».
- Щелкнуть по ссылке «Редактировать код».
- В поле редактирования вставить код .
- Нажать «Сохранить».
- Перейти в «Настройки» и выбрать раздел SEO.
- В перечне найти параметр «Запрет индексации».
- Снять отметку в чекбоксе «Запретить поисковикам индексировать этот сайт».
- Вверху нажать «Сохранить изменения».
- В «Яндекс.Вебмастер» выбираем необходимый ресурс на «Тильде».
- Открываем в боковом меню вкладку «Индексирование».
- В подменю нужно перейти в раздел «Переобход страниц».
- Внизу кликаем по кнопке «Добавить сайт».
- В пустое поле вставить ссылку на карту сайта.
- Щелкаем по кнопке «Добавить».
Файл sitemap и robots на Тильде
Конструктор сайтов Тильда генерирует sitemap xml и robots txt автоматически. Они помогают роботу поисковой системы обойти и проиндексировать сайт. В итоге страницы ресурса быстрее появятся в выдаче. Поэтому необходимо разобраться с принципами создания, оптимизации и настройки этих файлов.
О том, что такое Sitemap Tilda

Sitemap представляет собой ничто иное, как карту сайта. В файле размещаются ссылки на страницы интернет-проекта. Его цель — своевременно передавать поисковым системам структуру ресурса. Tilda поддерживает два типа сайтмап — в форматах xml и html:
Бывает, что «Яндекс» выдает пользователю предупреждение о том, что сейчас нет используемых роботом файлов sitemap. Если появляется подобная ошибка, скорее всего вы не добавили новые страницы, и поисковик не может их проиндексировать.
Что такое robots.txt в Tilda и его особенности
Robots.txt представляет собой текстовый файл, в котором прописаны параметры индексирования сайта поисковыми системами. Он обеспечивает видимость ресурса и его выдачу при создании поискового запроса. С его помощью пользователь может выполнить настройку, например, запретить индексацию определенных страниц. Для этого используется директива Disallow. Параметр Allow, наоборот, разрешает индексирование отдельных страниц.
Файл размещается в корневом каталоге и создается автоматически. CMS Tilda не позволяет вносить какие-либо изменения в robots.txt. Нельзя настроить директивы user-agent, Disallow, Sitemap, Clean param, Allow, Crawl-Delay. Если нужно скрыть страницу из поиска, необходимо редактировать именно настройки веб-страницы, и Tilda автоматически внесет все нужные изменения в robots.txt.
Пользователю остается отправить файл в поисковые системы с помощью Yandex Webmaster и Google Search Console. Для этого нужно зарегистрироваться в данных сервисах и подтвердить права на домен. Консоль «Тильды» допускает сделать привязку этих сервисов.
Для справки! «Яндекс» строго придерживается директив robots.txt, а вот поисковик Google может его игнорировать.
Как просматривать robots.txt
Чтобы посмотреть файл, необходимо к основному URL ресурса добавить robots.txt. В адресной строке браузера URL должен иметь следующий вид: https://www.site.my/robots.txt. Откроется страница, где будут указаны параметры индексации для сайта. Файл robots.txt является публичным и открыт для просмотра на любом ресурсе.

Чтобы задать ограничения на индексацию страницы нужно:
Чтобы изменения вступили в силу, нужно закрыть страницу редактирования настроек. Новые данные будут автоматически внесены в файл robots.txt. Дополнительных манипуляций проводить не надо.
«Тильда» по умолчанию убирает из индексации неканонические страницы (дубли). При создании проекта, ему присваивается собственный URL xxxxx90.tilda.ws. Если пользователь привяжет к ресурсу собственное доменное имя, проект будет доступен сразу по обоим адресам, что негативно влияет на индексирование. В этой ситуации «Тильда» генерирует тег rel=»canonical» со ссылкой на каноническую страницу, которая является основной и подлежит индексации.
Как создать сайтмап на «Тильде»
Чтобы создать Sitemap на Tilda, необходимо придерживаться следующего алгоритма действий:
Он удобен тем, что можно добавлять ссылки в один клик и редактировать по своему усмотрению. Рекомендуем размещать карту сайта в сквозном блоке (имеющие одинаковый вид и структуру сразу на нескольких страницах). Хорошо для этого подходит хедер (шапка или верхняя область сайта) и футер (подвал или нижняя часть ресурса). Фактор правильности размещения сайтмап влияет на индексацию в поисковой выдаче — у робота будут в доступе абсолютно все страницы.
Главные особенности SEO-оптимизации сайта, созданного в «Тильде»

Чтобы вывести сайт в ТОП поисковой выдачи необходимо провести SEO-оптимизацию ресурса. «Тильда» предлагает пользователям быстрый аудит с помощью встроенного функционала — «SEO-рекомендации». Данный элемент представляет собой чек-лист, по которому можно посмотреть, какие ссылки индексируются или, наоборот, закрыты для поискового робота. Дополнительно через него можно посмотреть наличие или отсутствие тегов, тайтла, дискрипшена и другие ошибки. Чтобы использовать этот инструмент, необходимо:
Отобразится таблица, где появятся рекомендации, требующие участия пользователя.
Что еще нужно сделать для оптимизации ресурса на «Тильде»:
Интерфейс Тильды подходит для пользователей, которые не имеют больших навыков в создании интернет-проектов и SEO, поэтому необходимый функционал для этого доступен по умолчанию.
Как установить запрет на индексацию сайта

Запрет рекомендуется устанавливать перед тем, как создавать ресурс. Порядок действий:
Ограничение можно установить через вставку HTML-кода:
Как только ресурс будет готов к публикации, необходимо снять запрет на индексирование в настройках или вновь отредактировать HTML-код.
Рекомендация по запрету на индексацию применима на этапе разработки, так как позволяет исключить из поисковой выдачи технически неготовый ресурс, где еще отсутствуют мета-данные, аналитика, не подключены сертификаты безопасного соединения и не настроено отображение страниц для разных устройств.
Что делать, если в robots.txt в «Тильде» сайт закрыт для индексирования

Подобная ошибка появляется, если установлены ограничения на индексирование ресурса в настройках. Тильда robots txt корректирует самостоятельно, как только пользователь применит новые параметры. Чтобы устранить сбой, нужно:
Иногда ошибка появляется, если были отредактированы параметры в меню «Ограничить доступ». Например, установлен логин и пароль для доступа к опубликованным страницам. Также ресурс может быть закрыт от индексирования, если просмотр разрешен только с определенных IP-адресов. Нужно зайти в «Настройки сайта» и выбрать вкладку «Ограничить доступ». Необходимо убрать логин и пароль, а также удалить IP-адреса. После этого ошибка должна исчезнуть.
Если создавался личный кабинет, страницы, размещенные в профиле, автоматически исключаются из индексации и к ним нельзя привязать аналитические инструменты. Это связано с правилами безопасности. Пользовательские данные должны быть защищены.
Избавляемся от ошибок sitemap-feeds.xml и sitemap-store.xml на «Тильде»
Ошибки появляются, если подключены «Потоки» и «Товары». Первая функция появилась недавно. Это панель управления, где можно создавать и редактировать посты для блога. Как раз все дело в модуле «Потоки». Из-за него появляется ошибка sitemap-feeds.xml, так как конструктор автоматически создает сайтмап и вносит изменения в robots.txt. Если посмотреть «роботс», то там обнаружится нерабочий sitemap-feeds.xml. Если заглянем в «Потоки» и кликнем по названию поста, откроется таблица с рандомными файлами. Они и являются причиной сбоя. Чтобы решить проблему — удаляем их.
Эти рандомные файлы, которые создает конструктор, появятся только один раз при первом использовании плагина «Потоки». Когда будете делать добавление новых постов, подобного уже происходить не будет. Также допускается полностью взять и деактивировать модуль, если он не нужен: «Настройки» → «Еще» → «Подключаемые модули» → «Удалить потоки и отключить модуль».
Ошибка sitemap-store.xml появляется при первом использовании плагина «Товары». Если зайти в него впервые, там будут находится рандомные файлы, созданные конструктором. Для устранения проблемы нужно удалить элементы. При добавлении новых товаров ошибка уже не появится.
Как правильно добавить новый sitemap из «Тильда» в «Вебмастер»

После создания файла sitemap.html, его нужно внести в Yandex Webmaster. Это поможет поисковому роботу своевременно узнавать о новых страницах и индексировать их. Ссылка быстрее появится в поиске. Добавление файла производится согласно следующему алгоритму:
Вам удалось зарегистрировать сайтмап. Поисковой робот обойдет страницу и после этого появится статус задачи. Полный обход будет зависеть от размера сайтмапа. В среднем срок индексирования составляет 3 дня. В разделе «Отправленные страницы» можно кликнуть по кнопке «Отслеживать». Откроется панель мониторинга, где отображаются проиндексированные и рекомендованные к выдаче страницы, последние изменения, проверенные мета-данные, дата переобхода, статус ссылки. В «Яндекс.Вебмастере» установлен лимит — можно добавить только 20 страниц в сутки.
Почему сайт на «Тильде не виден» для поисковиков
Если вы зарегистрировали сайт в поисковых системах «Яндекс» и «Гугл», провели SEO-оптимизацию, но ресурс не отображается при поиске, это не означает, что вы где-то или что-то сделали не так. Продвижение — сложная вещь. Без базовых знаний добиться результата практически невозможно или он будет минимальным. «Тильда», хоть и имеет функционал, который поможет пользователю оптимизировать сайт, не представляет собой мифическое средство, способное решить все проблемы. Это добротный инструмент, но не более. При нужных знаниях (не только в CEO) можно создавать хорошие сайты на «Тильде» с неплохой посещаемостью.
Не малозначимым будет поведенческий фактор, который позволит определить полезность, качество самого ресурса, отдельных страниц. Требуется работать с семантикой, так как это фундамент, позволяющий узнать тематику и охарактеризовать деятельность. Семантика строится на ключевых запросах, которые помогут пользователю попасть на нужный ресурс и искать ответы на вопросы.
Нужно работать над уникальностью контента, поисковые роботы могут проигнорировать и не проиндексировать страницы, так как посчитают их незначимыми, если там будут размещаться взятые с других сайтов материалы.