Алгоритмы. Обход дерева
Давно я не писал, как то все времени не находилось. Мы говорили про деревья, давайте теперь поговорим про обход деревьев. Обходы деревьев нужны собственно для того чтоб оптимально быстрой найти необходимый элемент в дереве.
Собственно обход дерева, как и все обходы графов ( а дерево это обычный неориентированный граф ) делается двумя методами: в глубину (Depth-first) и в ширину (Breadth-first).
Какой из методов использовать?
На самом деле споров достаточно много, и если зайти на различные форумы — то вы получите огромное количество ответов, каждый из которых не факт что будет полезен для вас. Потому, для себя я решил таким образом( взято кстати с треда на stackoverflow):
- если вы знаете что решение где-то не далеко от вашей ноды — то лучше использовать обход в ширь, чтоб не закапываться глубоко в дерево
- если дерево очень глубокое, а решение редки — то лучше все таки попробовать поиск в ширь
- если дерево очень широкое, то можно попробовать поиск в глубь, потому как поиск в ширь может забрать слишком много времени.
Собственно, как я уже и писал, правильного ответа нет — потому надо пробовать разные варианты:) Эксперементировать всегда весело!
Так как мы будем пробовать на созданном бинарном дереве все алгоритмы, они редко бывают широкими, потому обсудим в начале поиск в глубь.
DFS. Алгоритмы в глубь имеют три типа обходов:
Pre-order стоит использовать именно тогда, когда вы знаете что вам нужно проверить руты перед тем как проверять их листья.
В результате Pre-order обхода мы получим такой порядок :
function preOrder(node) if (node == null) return;
console.log(node.value);
preOrder(node.left);
preOrder(node.right);
>
In-order обход используется как раз когда нам надо проверять в начале детей и только потом подыматься к родительским узлам.
В таком случае мы получаем просто: A,B,C,D,E,F,G,H,I
function inOrder(node) if (node == null) return;
inOrder(node.left);
console.log(node.value);
inOrder(node.right);
>
Post-order самый забавный случай — это случай когда нам нужно начать-так сказать с листов и завершить главным узлом — тоесть разложить дерево на то, как оно строилось.
В таком случае мы полчаем: A, C, E, D, B, H, I, G,F
function postOrder(node) if (node == null) return;
postOrder(node.left);
postOrder(node.right);
console.log(node.value);
>
Как видим — код очень похож:) просто разный порядок вызовов.
BFS точно такой же как и в графах. Все достаточно просто — мы бегаем в начале по рут ноде, потом по всем ее детям, потом по всем детям детей, и так далее.
function bfs(node) var queue = [];
var values = [];
queue.push(node); while(queue.length > 0) var tempNode = queue.shift();
values.push(tempNode.value);
if (tempNode.left) queue.push(tempNode.left);
> if (tempNode.right) queue.push(tempNode.right);
>
> return values;
>
Собственно на этом пока все:)
Как обычно: исходники примеров вы можете найти тут.
Обход графа: поиск в глубину и поиск в ширину простыми словами на примере JavaScript
Простыми словами, обход графа — это переход от одной его вершины к другой в поисках свойств связей этих вершин. Связи (линии, соединяющие вершины) называются направлениями, путями, гранями или ребрами графа. Вершины графа также именуются узлами.
Двумя основными алгоритмами обхода графа являются поиск в глубину (Depth-First Search, DFS) и поиск в ширину (Breadth-First Search, BFS).
Несмотря на то, что оба алгоритма используются для обхода графа, они имеют некоторые отличия. Начнем с DFS.
Поиск в глубину
DFS следует концепции «погружайся глубже, головой вперед» («go deep, head first»). Идея заключается в том, что мы двигаемся от начальной вершины (точки, места) в определенном направлении (по определенному пути) до тех пор, пока не достигнем конца пути или пункта назначения (искомой вершины). Если мы достигли конца пути, но он не является пунктом назначения, то мы возвращаемся назад (к точке разветвления или расхождения путей) и идем по другому маршруту.
Давайте рассмотрим пример. Предположим, что у нас есть ориентированный граф, который выглядит так:

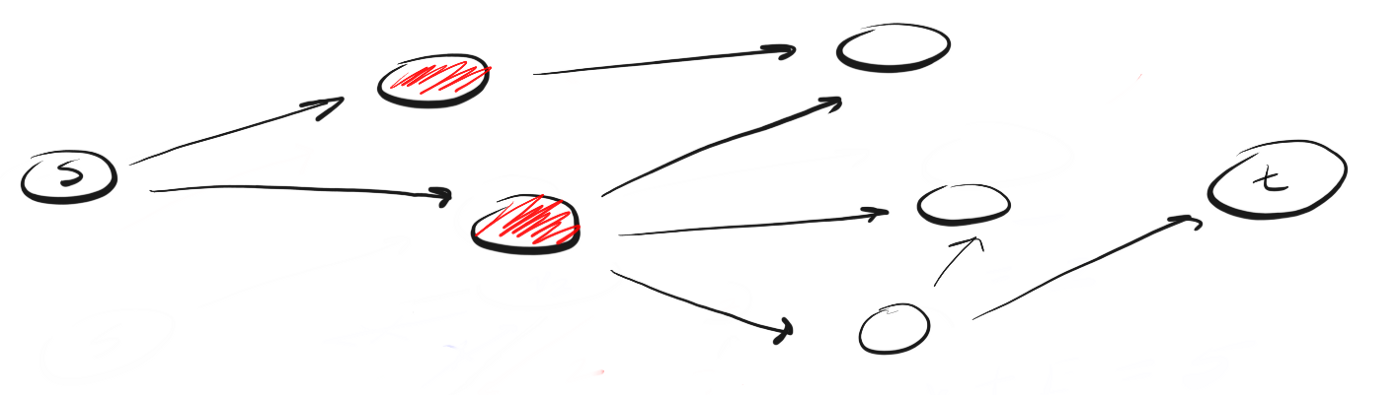
Мы находимся в точке «s» и нам нужно найти вершину «t». Применяя DFS, мы исследуем один из возможных путей, двигаемся по нему до конца и, если не обнаружили t, возвращаемся и исследуем другой путь. Вот как выглядит процесс:

Здесь мы двигаемся по пути (p1) к ближайшей вершине и видим, что это не конец пути. Поэтому мы переходим к следующей вершине.

Мы достигли конца p1, но не нашли t, поэтому возвращаемся в s и двигаемся по второму пути.

Достигнув ближайшей к точке «s» вершины пути «p2» мы видим три возможных направления для дальнейшего движения. Поскольку вершину, венчающую первое направление, мы уже посещали, то двигаемся по второму.

Мы вновь достигли конца пути, но не нашли t, поэтому возвращаемся назад. Следуем по третьему пути и, наконец, достигаем искомой вершины «t».

Так работает DFS. Двигаемся по определенному пути до конца. Если конец пути — это искомая вершина, мы закончили. Если нет, возвращаемся назад и двигаемся по другому пути до тех пор, пока не исследуем все варианты.
Мы следуем этому алгоритму применительно к каждой посещенной вершине.
Необходимость многократного повторения процедуры указывает на необходимость использования рекурсии для реализации алгоритма.
// при условии, что мы имеем дело со смежным списком // например, таким: adj = function dfs(adj, v, t) < // adj - смежный список // v - посещенный узел (вершина) // t - пункт назначения // это общие случаи // либо достигли пункта назначения, либо уже посещали узел if(v === t) return true if(v.visited) return false // помечаем узел как посещенный v.visited = true // исследуем всех соседей (ближайшие соседние вершины) v for(let neighbor of adj[v]) < // если сосед не посещался if(!neighbor.visited) < // двигаемся по пути и проверяем, не достигли ли мы пункта назначения let reached = dfs(adj, neighbor, t) // возвращаем true, если достигли if(reached) return true >> // если от v до t добраться невозможно return false > Заметка: этот специальный DFS-алгоритм позволяет проверить, возможно ли добраться из одного места в другое. DFS может использоваться в разных целях. От этих целей зависит то, как будет выглядеть сам алгоритм. Тем не менее, общая концепция выглядит именно так.
Анализ DFS
Давайте проанализируем этот алгоритм. Поскольку мы обходим каждого «соседа» каждого узла, игнорируя тех, которых посещали ранее, мы имеем время выполнения, равное O(V + E).
Краткое объяснение того, что означает V+E:
V — общее количество вершин. E — общее количество граней (ребер).
Может показаться, что правильнее использовать V*E, однако давайте подумаем, что означает V*E.
V*E означает, что применительно к каждой вершине, мы должны исследовать все грани графа безотносительно принадлежности этих граней конкретной вершине.
С другой стороны, V+E означает, что для каждой вершины мы оцениваем лишь примыкающие к ней грани. Возвращаясь к примеру, каждая вершина имеет определенное количество граней и, в худшем случае, мы обойдем все вершины (O(V)) и исследуем все грани (O(E)). Мы имеем V вершин и E граней, поэтому получаем V+E.
Далее, поскольку мы используем рекурсию для обхода каждой вершины, это означает, что используется стек (бесконечная рекурсия приводит к ошибке переполнения стека). Поэтому пространственная сложность составляет O(V).
Теперь рассмотрим BFS.
Поиск в ширину
BFS следует концепции «расширяйся, поднимаясь на высоту птичьего полета» («go wide, bird’s eye-view»). Вместо того, чтобы двигаться по определенному пути до конца, BFS предполагает движение вперед по одному соседу за раз. Это означает следующее:
Вместо следования по пути, BFS подразумевает посещение ближайших к s соседей за одно действие (шаг), затем посещение соседей соседей и так до тех пор, пока не будет обнаружено t.

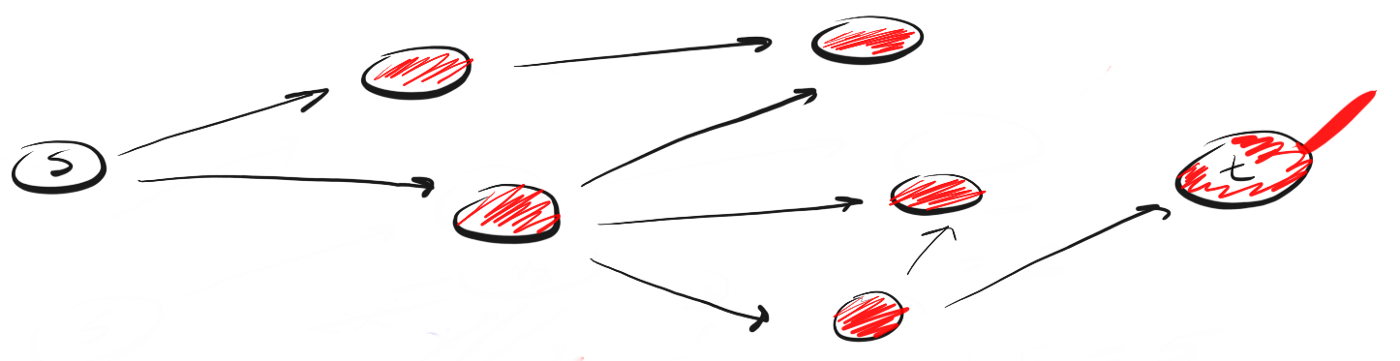
Чем DFS отличается от BFS? Мне нравится думать, что DFS идет напролом, а BFS не торопится, а изучает все в пределах одного шага.
Далее возникает вопрос: как узнать, каких соседей следует посетить первыми?
Для этого мы можем воспользоваться концепцией «первым вошел, первым вышел» (first-in-first-out, FIFO) из очереди (queue). Мы помещаем в очередь сначала ближайшую к нам вершину, затем ее непосещенных соседей, и продолжаем этот процесс, пока очередь не опустеет или пока мы не найдем искомую вершину.
// при условии, что мы имеем дело со смежным списком // например, таким: adj = function bfs(adj, s, t) < // adj - смежный список // s - начальная вершина // t - пункт назначения // инициализируем очередь let queue = [] // добавляем s в очередь queue.push(s) // помечаем s как посещенную вершину во избежание повторного добавления в очередь s.visited = true while(queue.length >0) < // удаляем первый (верхний) элемент из очереди let v = queue.shift() // abj[v] - соседи v for(let neighbor of adj[v]) < // если сосед не посещался if(!neighbor.visited) < // добавляем его в очередь queue.push(neighbor) // помечаем вершину как посещенную neighbor.visited = true // если сосед является пунктом назначения, мы победили if(neighbor === t) return true >> > // если t не обнаружено, значит пункта назначения достичь невозможно return false > Анализ BFS
Может показаться, что BFS работает медленнее. Однако если внимательно присмотреться к визуализациям, можно увидеть, что они имеют одинаковое время выполнения.
Очередь предполагает обработку каждой вершины перед достижением пункта назначения. Это означает, что, в худшем случае, BFS исследует все вершины и грани.
Несмотря на то, что BFS может казаться медленнее, на самом деле он быстрее, поскольку при работе с большими графами обнаруживается, что DFS тратит много времени на следование по путям, которые в конечном счете оказываются ложными. BFS часто используется для нахождения кратчайшего пути между двумя вершинами.
Таким образом, время выполнения BFS также составляет O(V + E), а поскольку мы используем очередь, вмещающую все вершины, его пространственная сложность составляет O(V).
Аналогии из реальной жизни
Если приводить аналогии из реальной жизни, то вот как я представляю себе работу DFS и BFS.
Когда я думаю о DFS, то представляю себе мышь в лабиринте в поисках еды. Для того, чтобы попасть к цели мышь вынуждена много раз упираться в тупик, возвращаться и двигаться по другому пути, и так до тех пор, пока она не найдет выход из лабиринта или еду.
Упрощенная версия выглядит так:

В свою очередь, когда я думаю о BFS, то представляю себе круги на воде. Падение камня в воду приводит к распространению возмущения (кругов) во всех направлениях от центра.

Упрощенная версия выглядит так:

Выводы
- Поиск в глубину и поиск в ширину используются для обхода графа.
- DFS двигается по граням туда и обратно, а BFS распространяется по соседям в поисках цели.
- DFS использует стек, а BFS — очередь.
- Время выполнения обоих составляет O(V + E), а пространственная сложность — O(V).
- Данные алгоритмы имеют разную философию, но одинаково важны для работы с графами.
Учебники. Программирование для начинающих.
Проектирование, изготовление и монтаж крафтовых заборов из камня в Московской области.. Соблюдение Вашей конфиденциальности важно для нас. По этой причине, мы разработали Политику Конфиденциальности, которая описывает, как мы используем и храним Вашу информацию. Пожалуйста, ознакомьтесь с нашими правилами соблюдения конфиденциальности и сообщите нам, если у вас возникнут какие-либо вопросы.
Programm.ws — это сайт, на котором вы можете почитать литературу по языкам программирования , а так-же посмотреть примеры работающих программ на С++, ассемблере, паскале и много другого..
Программирование — в обычном понимании, это процесс создания компьютерных программ.
В узком смысле (так называемое кодирование) под программированием понимается написание инструкций — программ — на конкретном языке программирования (часто по уже имеющемуся алгоритму — плану, методу решения поставленной задачи). Соответственно, люди, которые этим занимаются, называются программистами (на профессиональном жаргоне — кодерами), а те, кто разрабатывает алгоритмы — алгоритмистами, специалистами предметной области, математиками.
В более широком смысле под программированием понимают весь спектр деятельности, связанный с созданием и поддержанием в рабочем состоянии программ — программного обеспечения ЭВМ. Более точен современный термин — «программная инженерия» (также иначе «инженерия ПО»). Сюда входят анализ и постановка задачи, проектирование программы, построение алгоритмов, разработка структур данных, написание текстов программ, отладка и тестирование программы (испытания программы), документирование, настройка (конфигурирование), доработка и сопровождение.
Ассемблер — примеры и задачи
Глава 2. Сложные структуры данных
Обход узлов дерева
Возможны три варианта обхода дерева:
- сверху вниз — корень, левое поддерево, правое поддерево;
- слева направо — левое поддерево, корень, правое поддерево;
- снизу вверх — левое поддерево, правое поддерево, корень.
Понятно, что процедура обхода рекурсивна. Под термином «обход дерева» понимается то, что в соответствии с одним из определенных выше вариантов посещается каждый узел дерева и с его содержательной частью выполняются некоторые действия. Для нашей задачи подходит только второй вариант, так как только в этом случае порядок посещения узлов будет соответствовать упорядоченному массиву. В качестве полезной работы будем извлекать значение из узла двоичного дерева и выводить его в массив в памяти. Отметим особенности функции LRBeat, производящей обход дерева. Во-первых, она рекурсивная, во-вторых, в ней для хранения адресов узлов используется свой собственный стек. Стек, поддерживаемый на уровне архитектуры микропроцессора, используется для работы процедурного механизма, и мы со своими проблемами только «путаемся у него под ногами».
:prg02_13.asm — программа обхода двоичного дерева поиска (слева направо). ;Вход: произвольный масиив чисел в памяти. :Выход: двоичное дерево в памяти.
объявления структур: nodejxee struc :узел дерева
ends
: для программного стека
desc_stk struc :дескриптор стека
ends
•.описание макрокоманд работы со стеком:
create_stk macro HandHead:REQ.descr:REQ.Si zeStk:=
¦.создание стека
endm
push_stk macro descr:REQ.rg_item:REQ
добавление элемента в стек
endm
pop_stkmacro descr:REQ. rg_item:REQ
извлечение элемента из стека
endm
.data
исходный массив:
masdb 37h.l2h,8h.65h.4h.54h.llh.02h.32h,5h,4h,87h.7h.21h.65h.45h.22h,llh.77h.
51h.26h.73h.35h.12h.49h.37h.52h l_mas=$-mas
упорядоченный массив (результат см. в отладчике): ordered array db 1 mas dup (0)
doubleWord_stkdesc_stk <> -.дескриптор стека
count call dd 0 :счетчик количества рекурсивного вызова процедуры
.code
BuildBinTree proc ;см. prg02_12.asm
:двоичное дерево поиска построено
ret
BuildBinTree endp LRBeat proc
:рекурсивная процедура обхода дерева — слева направо :(левое поддерево, корень, правое поддерево)
inc count_call ;подсчет количества вызовов процедуры
:(для согласования количества записей и извлечений из стека)
cmp ebx.O
je @@exit_p
mov ebx.[ebx].l_son
cmp ebx, 0
je @@ml
push_stk doubleWord_stk.ebx mini: call LRBeat
pop stkdoubleWord stk.ebx
r r_ —
jnc @@m2
:подчистим за собой стек и на выход raovecx.count_call
dec ecx
pop NewNode:pop «в никуда»
loop $-6
jmp @@exi t_p @@m2: moval,[ebx].simbol
stosb
mov ebx, [ebx]. r_son cmp ebx.O je @@ml push stk doubleWord stk.ebx
c’all LRBeat » @@exit_p: deccount_call
ret
LRBeat endp start proc near ;точка входа в программу:
call BuildBinTree :формируем двоичное дерево поиска ;обходим узлы двоичного дерева слева направо и извлекаем значения ;из содержательной части, нам понадобится свой стек (размер (256 байт) нас устроит. :но макроопределение мы подкорректировали)
create_stk Hand_Head.doubieWord_stk
push ds
pop es
lea edi.ordered_array
mov ebx.HeadTree push_stk doubleWord_stk.ebx указатель на корень в наш стек
call LRBeat
Еще одно замечание о рекурсивной процедуре. Реализация рекурсивное™ в программах ассемблера лишена той комфортности, которая характерна для языков высокого уровня. При реализации рекурсивной процедуры LRBeat возникает несбалансированность стека, в результате после последнего ее выполнения на вершине стека лежит не тот адрес и команда RET отрабатывает неверно. Для устранения подобного эффекта нужно вводить корректировочный код, суть которого заключается в следующем. Процедура LRBeat подсчитывает количество обращений к ней и легальных, то есть через команду RET, выходов из нее. При последнем выполнении анализируется счетчик обращений countcal 1 и производится корректировка стека.
Для полноты изложения осталось только показать, как изменится процедур;!. LRBeat для других вариантов обхода дерева.
Построенное выше бинарное дерево теперь можно использовать для дальнейших операций, в частности поиска. Для достижения максимальной эффективности поиска необходимо, чтобы дерево было сбалансированным. Так, дерево считается идеально сбалансированным, если число вершин в его левых и правых поддеревьях отличается не более чем на 1. Более подробные сведения о сбалансированных деревьях вы можете получить, изучая соответствующую литературу. Здесь же будем считать, что сбалансированное дерево уже построено. Разберемся с тем, как производить включение и исключение узлов в подобном, заранее построенном упорядоченном дереве.
Включение узла в упорядоченное бинарное дерево
Задача включения узла в дерево уже была решена нами при построении дерева. Осталось оформить соответствующий фрагмент программы в виде отдельной процедуры addNodeTree. Чтобы не дублировать код, разработаем рекурсивный вариант процедуры включения — addNodeTree. Он хоть и не так нагляден, как нерекурсивный вариант кода в программе prg_03.asm, но выглядит достаточно профессионально. Текст процедуры addNodeTree вынесен на дискету.
Работу процедуры addNodeTree можно проверить с помощью программы prgO2_ 13.asm (в ПРИМЕРе ей соответствует программа prgO2_14.asm).
В результате проведенных работ мы получили дублирование кода, строящего и дополняющего дерево. В принципе для строительства и включения в дерево достаточно одной процедуры addNodeTree. Но в учебных целях мы ничего изменять не будем, чтобы иметь два варианта строительства дерева — рекурсивный и не рекурсивный. При необходимости читатель сам определит, какой из вариантов более всего отвечает его задаче и в соответствии с этим доработает этот код.
Исключение узла из упорядоченного бинарного дерева
Эта процедура более сложная. Причиной тому то обстоятельство, что существует несколько вариантов расположения исключаемого узла в дереве: узел является листом, узел имеет одного потомка и узел имеет двух потомков. Самый непростой случай — последний. Процедура удаления элемента del NodeTree является рекурсивной и, более того, содержит вложенную процедуру del, которая также является рекурсивной. Текст процедуры del NodeTree вынесен на дискету.
Работу этой процедуры можно проверить с помощью программы prg02_13.asm (в ПРИМЕРе ей соответствует программа prg02_15.asm).
Графически процесс исключения из дерева выглядит так, как показано на рис. 2.20. Исключаемый узел помечен стрелкой.
Рис. 2.20. Исключение из дерева
Для многих прикладных задач, занимающихся обработкой символьной информации, важное значение могут иметь так называемые лексикографические деревья. Для нашего изложения они важны тем, что эффективно могут быть применены при разработке трансляторов, чему мы также уделим внимание в этой книге.
Обход дерева — JS: Деревья
Пошаговый перебор элементов дерева по связям между узлами-предками и узлами-потомками называется обходом дерева. Подразумевается, что в процессе обхода каждый узел будет затронут только один раз. По большому счёту, всё так же, как и в обходе любой коллекции, используя цикл или рекурсию. Только в случае деревьев способов обхода больше, чем просто слева направо и справа налево.
В данном курсе используется один порядок обхода — обход в глубину, так как он естественным образом получается при рекурсивном обходе. Об остальных способах можно прочитать в Википедии либо в рекомендуемых Хекслетом книгах.
Обход в глубину (Depth-first search)
Один из методов обхода дерева (графа в общем случае). Стратегия этого поиска состоит в том, чтобы идти вглубь одного поддерева настолько, насколько это возможно. Этот алгоритм естественным образом ложится на рекурсивное решение и получается сам собой.
Рассмотрим данный алгоритм на примере следующего дерева:
// * A // / | \ // B * C * D // /| |\ // E F G J Каждая нелистовая вершина обозначена звёздочкой. Обход начинается с корневого узла.
- Проверяем, есть ли у вершины A дети. Если есть, то запускаем обход рекурсивно для каждого ребёнка независимо;
- Внутри первого рекурсивного вызова оказывается следующее поддерево:
// B * // /| // E F Повторяем логику первого шага. Проваливаемся на уровень ниже.
- Внутри оказывается листовой элемент E . Функция убеждается, что у узла нет дочерних элементов, выполняет необходимую работу и возвращает результат наверх.
- Снова оказываемся в ситуации:
// B * // /| // E F В этом месте, как мы помним, рекурсивный вызов запускался на каждом из детей. Так как первый ребёнок уже был посещен, второй рекурсивный вызов заходит в узел F и выполняет там свою работу. После этого происходит возврат выше, и всё повторяется до тех пор, пока не дойдёт до корня.
const tree = mkdir('/', [ mkdir('etc', [ mkfile('bashrc'), mkfile('consul.cfg'), ]), mkfile('hexletrc'), mkdir('bin', [ mkfile('ls'), mkfile('cat'), ]), ]); const dfs = (tree) => // Распечатываем содержимое узла console.log(getName(tree)); // Если это файл, то возвращаем управление if (isFile(tree)) return; > // Получаем детей const children = getChildren(tree); // Применяем функцию dfs ко всем дочерним элементам // Множество рекурсивных вызовов в рамках одного вызова функции // называется древовидной рекурсией children.forEach(dfs); >; dfs(tree); // => / // => etc // => bashrc // => consul.cfg // => hexletrc // => bin // => ls // => cat Печать на экран в примере выше это лишь демонстрация. В реальности же нас интересует либо изменение дерева, либо агрегация данных по нему. Агрегацию данных рассмотрим позже, а сейчас разберём изменение.
Допустим, мы хотим реализовать функцию, которая меняет владельца для всего дерева, то есть всех директорий и файлов. Для этого нам придётся соединить две вещи: рекурсию, разобранную выше, и код обновления узлов, который изучался в прошлом уроке.
const changeOwner = (tree, owner) => const name = getName(tree); const newMeta = _.cloneDeep(getMeta(tree)); newMeta.owner = owner; if (isFile(tree)) // Возвращаем обновлённый файл return mkfile(name, newMeta); > // Дальше идет работа, если директория const children = getChildren(tree); // Ключевая строчка // Вызываем рекурсивное обновление каждого ребёнка const newChildren = children.map((child) => changeOwner(child, owner)); const newTree = mkdir(name, newChildren, newMeta); // Возвращаем обновлённую директорию return newTree; >; // Эту функцию можно обобщить до map (отображения), работающего с деревьями Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях: