Как проводится компиляция в IntelliJ IDEA
От автора: если бы не было таких мощных и качественных инструментов, как IntelliJ IDEA, компиляция занимала бы слишком много времени у разработчика — ведь это нужно собрать все файлы в единую программу, а после корректно запустить ее. К счастью, благодаря высокоразвитым IDE вся сложность заключается в настройке компилятора, а не каждого отдельного файла, поэтому в процессе работы с IntelliJ IDEA компиляция делается очень просто. Сегодня мы расскажем, как конфигурировать эту IDE для успешной сборки.

Знакомство с компилятором
Компиляция — это своеобразный процесс сборки, который заключается в трансляции всех модулей, которыми оснащена программа. В зависимости от ситуации, исходный код может быть написан на одном языке или на нескольких. Суть в том, чтобы преобразовать человекопонятный код в машинопонятный.
До того, как появились компиляторы, все, с чем вы сталкиваетесь сегодня, делалось вручную. Но по мере развития продуктов данный софт стал необходим. Это программы, которые могут переводить код, написанный на высокоуровневом языке программирования, в низкоуровневый код, то есть в нули и единицы. Таким образом, процессор может понять то, что сказал человек.
Компиляторы бывают нескольких видов. Точно так же и процесс компиляции бывает разным. Все зависит от того, какой язык используется (компилируемый/интерпретируемый) и какое применяется программное обеспечение для взаимодействия. Кстати, раньше этот вид ПО называли «программирующими программами». Этимологическая логика здесь проста: это был инструмент, который заставлял компьютер выполнять код — то есть, программировал его.
Исполнительные файлы
Вы привыкли к тому, что готовая программа должна запуститься на вашем компьютере. И потому хотите, чтобы это происходило на каждом удобном вам ПК. И они так могут. Главное, чтобы на ПК или любом другом устройстве была установлена исполнительная среда Java. Она встречается не только на компьютерах, но и на всех остальных системах, вроде бытовой техники.
Как правило, новички сразу ищут в IntelliJ IDEA возможность провести эту процедуру и превратить написанный ими код в .exe файл. Вынуждены вас огорчить, но это невозможно. Суть в том, что это противоречит самой концепции языка, не говоря уже о физической возможности. «Написано единожды — работает везде».
Тем не менее, неужели невозможно делать программы для Windows на языке Java? Конечно, можно, и готовые файлы будут иметь расширение .exe. Вот только дело тут не в компиляции. Программист должен сделать обертку для программы, чтобы она запустила Java Runtime Machine и Java-код вне глаз пользователя. И это действительно работающее решение.
Настройка проще, чем кажется
Вы можете изменить список распознанных ресурсов, исключить определенные пути из компиляции, выбрать нужный компилятор, настроить обработку аннотаций и т. д.
В диалоговом окне «Settings/Preferences» выберите Build, Execution, Deployment.
На странице компилятора вы можете, например, изменить регулярное выражение, описывающее расширения файлов, которые будут распознаваться как ресурсы. Используйте точки с запятой (;) для разделения отдельных шаблонов.
На странице «Исключения» укажите файлы и папки, которые не следует включать в компиляцию. Используйте «+» для добавления элементов в список.
Замечания:
На странице Java Compiler проверьте, является ли используемый компилятор тем, который вам нужен. При необходимости выберите другой компилятор.
На странице Annotation Processors настройте параметры обработки аннотаций.
Примените изменения и закройте диалог.
На этом заканчиваем рассказ о компиляции. Вам нужно запомнить два основных тезиса: компилятор IDEA нуждается в настройке, компиляции jar в exe не существует. Это совершенно другой, абсурдный процесс. И это не просто балластное знание. Оно убережет вас от скачивания утилит, которые обещают подобное чудо.
IntelliJ Idea : Декомпиляция, Компиляция, Субституция (или как править чужие ошибки)

«Да не изобрети ты велосипед» — одно из главных правил успешной и эффективной работы. Но что делать, когда свой велосипед изобретать не хочется, а у чужого руль оказался кривой, а колёса квадратными? Данный обзор предназначен для по возможности краткого ознакомления с приёмом исправления в чужих библиотеках «на крайний случай» и о том, как это дело распространить дальше своего компьютера.

Введение
- Подготовить испытуемое приложение для примера (на примере Hibernate проекта)
- Поиск изменяемого места
- Выполнение изменения
- Разворачивание репозитория
Подготовка испытуемого
Итак, нам нужен подопытный проект. Нам идеально подойдёт Hibernate, т.к. это «стильно, модно, современно». Не буду особо вдаваться в детали, т.к. статья не про Hibernate. Будем делать всё быстро и по делу. И будем, как правильные разработчики , использовать систему сборки. Например, нам так же подойдёт Gradle, который для данной статьи должен быть установлен (https://gradle.org/install/). Сначала, нам нужно создать проект. У Maven’а для этого есть архетипы, а у Gradle для этого есть особенный плагин: Gradle Init. Итак, открываем командную строку любым известным вам способом. Создаём каталог для проекта, переходим в него и выполняем комманду:
mkdir javarush cd javarush gradle init --type java-application

Прежде чем выполнять импорт проекта внесём некоторые изменения в файл, описывающий, каким образом нужно выполнять сборку. Этот файл называется build script’ом и имеет имя build.gradle. Находится он в том каталоге, в котором мы выполнили gradle init. Поэтому, просто открываем его (например, в windows командой start build.gradle). Находим там блок «dependencies», т.е. зависимости. Тут описываются все сторонние jar, которые мы будем использовать. Теперь надо понять, что тут описывать. Перейдём на сайт Hibernate (http://hibernate.org/). Нас интересует Hibernate ORM. Нам нужен последний релиз. В меню слева есть подраздел «Releases». Выбираем «latest stable». Проматываем вниз и находим «Core implementation (includes JPA)». Раньше нужно было поддержку JPA подключать отдельно, но теперь всё стало проще и достаточно только одной зависимости. Также нам понадобится при помощи Hibernate работать с базой данных. Для этого возьмём самый простой вариант – H2 Database. Выбор сделан, вот наши зависимости:
dependencies < // Базовая зависимость для Hibernate (новые версии включают и JPA) compile 'org.hibernate:hibernate-core:5.2.17.Final' // База данных, к которой мы будем подключаться compile 'com.h2database:h2:1.4.197' // Use JUnit test framework testCompile 'junit:junit:4.12' >
Отлично, что дальше? Надо настроить Hibernate. У Hibernate есть «Getting Started Guide», но он дурацкий и больше мешает, чем помогает. Поэтому пойдём как правильные люди сразу в «User Guide». В оглавлении видим раздел «Bootstrap», что переводится как «Начальная загрузка». То что надо. Там написано много умных слов, но смысл в том, что на classpath должен быть каталог META-INF, а там файл persistence.xml. На classpath по стандарту попадает каталог «resources». Поэтому создаём указанный каталог: mkdir src\main\resources\META-INF Создаём там файл persistence.xml и открываем его. Там же в документации есть пример «Example 268. META-INF/persistence.xml configuration file» из которого мы возьмём содержимое и вставим в файл persistence.xml. Далее запускаем IDE и импортируем в неё наш созданный проект. Теперь нам нужно что-то сохранять в базу. Это что-то называется сущности. Сущности представляют что-то из так называемой доменной модели. И в оглавлении, о чудо, видим «2. Domain Model». Спускаемся ниже по тексту и видим в главе «2.1. Mapping types» простой пример сущности. Забираем его к себе, чуть сократив:
package entity; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.Id; @Entity(name = "Contact") public class Contact < @Id @GeneratedValue private Integer id; private String name; public Contact(String name) < this.name = name; >>
Теперь у нас появился класс, представляющий сущность. Вернёмся в persistence.xml и поправим там одно место: Там где указан class укажем свой класс entity.Contact . Отлично, осталось запуститься. Возвращаемся в главу «Bootstrap». Так как у нас нет сервера приложений, который нам предоставит особое EE окружение (т.е. окружение, которое реализует для нас определённое поведение системы), то мы работаем в SE окружении. Для него нам подойдёт только пример «Example 269. Application bootstrapped EntityManagerFactory». Например, сделаем так:
public class App < public static void main(String[] args) < EntityManagerFactory emf = Persistence.createEntityManagerFactory("CRM"); EntityManager em = emf.createEntityManager(); em.getTransaction().begin(); Contact contact = new Contact("Vasya"); em.persist(contact); em.getTransaction().commit(); Query sqlQuery = em.createNativeQuery("select count(*) from contact"); BigInteger count = (BigInteger) sqlQuery.getSingleResult(); emf.close(); System.out.println("Entiries count: " + count); >>
Ура, наш испытуемый готов. Эту часть я не хотел опускать, т.к. для следующих глав желательно понимать то, как появился наш испытуемый.
Поиск изменяемого поведения
Давайте встанем на место инициализации поля count типа BigInteger и поставим там точки останова (BreakPoint). Встав на нужной строке это можно сделать при помощи Ctrl+F8 или через меню Run -> Toggle Line Breakpoint. После чего запускаем наш main метод в дебаге (Run -> Debug):

Немного неуклижий пример, но, допустим, мы хотим изменить количество query spaces при старте. Как мы видим, наш sqlQuery это NativeQueryImpl. Нажимаем Ctrl+N , пишем название класса, переходим в него. Чтоб при переход в класс нас перебрасывало на то место, где лежит этот класс включил автоскрол:

Сразу заметим, что Idea не знает сейчас, где можно найти исходный код программы (исходники, то есть). Поэтому она милостиво декомпилировала для нас из class файла содержимое:

Заметим так же, что в заголовке окна IntelliJ Idea пишется, где Gradle сохраняет для нас артефакт. Теперь, получим в Idea путь, где лежит наш артефакт:

Перейдём в этот каталог в командной строке при помощи команды cd путь к каталогу . Сразу сделаю замечание: если есть возможность собрать проект из исходников, лучше собирать из исходников. Например, исходный код Hibernate доступен на официальном сайте. Лучше забрать его для нужной версии и сделать все изменения там и собраться при помощи скриптов сборки, которые указаны в проекте. Я же привожу в статье самый ужасный вариант – есть jar, а исходного кода нет. И замечание номер 2: Gradle может получить исходный код при помощи плагинов. Подробнее см. «How to download javadocs and sources for jar using Gradle.
Выполнение изменения
Нам нужно воссоздать структуру каталогов в соответствии с тем, в каком пакете лежит изменяемый нами класс. В данном случае: mkdir org\hibernate\query\internal , после чего создаём в этом каталоге файл NativeQueryImpl.java . Теперь открываем данный файл и копируем туда всё содержимое класса из IDE (то самое, которое для нас декомпилировала Idea). Изменяем нужные строки. Например:

- [1] — hibernate-core-5.2.17.Final.jar
- [2] — hibernate-jpa-2.1-api-1.0.0.Final.jar

Ура, теперь можно выполнить jar update. Можем руководствоваться официальными материалами: jar uf hibernate-core-5.2.17.Final.jar org\hibernate\query\internal\*.class Открытая IntelliJ Idea, скорей всего, не даст изменять файлы. Поэтому до выполнения jar update, скорей всего, придётся закрыть Idea, а после обновления — открыть. После этого можно заново открываем IDE, опять выполняем dubug. Break Points не сбрасываются между перезапусками IDE. Поэтому, выполнение программы остановится там, где и раньше. Вуаля, мы видим как работают наши изменения:

Отлично. Но тут возникает вопрос – благодаря чему? Просто благодаря тому, что когда gradle собирает проект, он анализирует блок dependencies и repositories. У грэдла есть некий build cache, который лежит в определённом месте (см. «How to set gradle cache location?». Если в кэше нет зависимости, то Gradle её скачает из репозитория. Т.к. мы меняли jar в самом кэше, то Gradle думает, что в кэше библиотека есть и ничего не выкачивает. Но любая очистка кэша приведёт к тому, что наши изменения пропадут. Плюс, никто кроме нас не может просто взять и получить их. Сколько неудобств, не правда ли? Что же делать. Хм, скачивает из репозитория? Значит, нам нужен наш репозиторий, с преферансом и поэтессами. Об этом следующий этап.
Разворачивание репозитория
Для разворачивания своего репозитория существуют разные бесплатные решения: одно из них Artifactory, а другое — Apache Archive. Артифактори выглядит модно, стильно, современно, но с ним у меня возникли трудности, никаких не хотел правильно размещать артефакты и генерировал ошибочные мавен метаданные. Поэтому, неожиданно для себя, у меня заработал апачевский вариант. Он оказался не такой красивый, зато работает надёжно. На странице загрузки ищем Standalone версию, распаковываем. У них есть свой «Quick Start». После запуска надо дождаться, когда по адресу http://127.0.0.1:8080/#repositorylist . После этого выбираем «Upload Artifact»:

Нажимаем «Start Upload», а после «Save Files». После этого появится зелёное сообщение об успешности и артефакт станет доступен в разделе «Browse». Так надо сделать для jar и для pom файлов:

Это связано с тем, что в pom файле прописаны дополнительные зависимости хибернейта. А нам осталось только 1 шаг — указать репозиторий в нашем билд скрипте:
repositories < jcenter() maven < url "http://127.0.0.1:8080/repository/internal/" >>
И, соответственно, версия нашего хибернейта станет: compile ‘org.hibernate:hibernate-core:5.2.17.Final-JAVARUSH’ . Вот и всё, теперь наш проект использует исправленный нами вариант, а не изначальный.
Заключение
- Есть такой веб-сервер Undertow. До некоторого времени был баг, который при использовании прокси не давал узнать IP конечного пользователя.
- До поры до времени WildFly JPA определённым образом обрабатывал один не учтённый спефицикацией момент, из-за этого сыпались Exception. И это не настраивалось.
Дебаг приложения на этапе компиляции IntelliJ IDEA
Рассказываю, как дебажить приложение на этапе компиляции с помощью intellij idea.
18 апр. 2021 · 2 минуты на чтение
Я столкнулся с необходимостью дебага annotation processor, когда писал библиотеку со своими аннотациями и обработчиками к ним. Проблема заключается в том, что обработка аннотаций происходит на этапе компиляции.
Спонсор поста
1. Создание Remote JVM Debug Configuration
Создаем новую конфигурацию. Вам нужно найти: “Remote JVM Debug”.
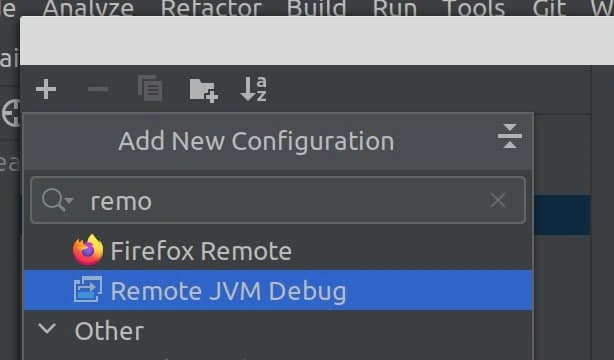
Выберите режим “Attach to remote JVM” и любой доступный порт, например 8000.
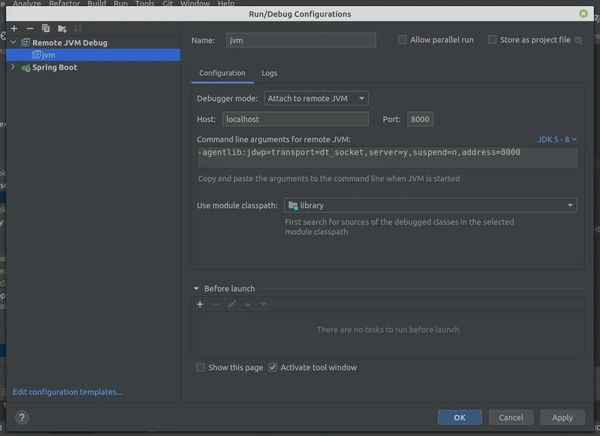
2. Убедитесь, что процесс сборки использует ваш порт
Нажмите Ctrl+Shift+A и найдите пункт “Edit Custom VM Options…”
Добавьте новую строку -Dcompiler.process.debug.port=8000 и перезапустите IDEA.
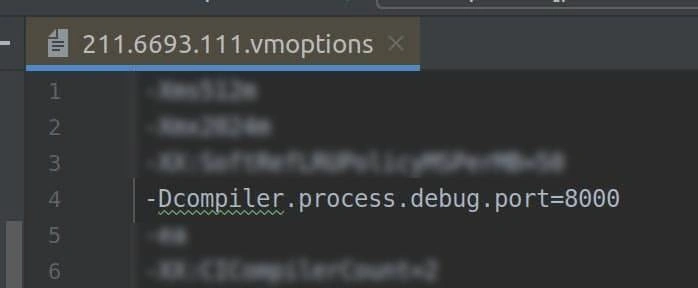
3. Включите “Debug build process”
Нажмите Ctrl+Shift+A и пункт “Debug build process”.
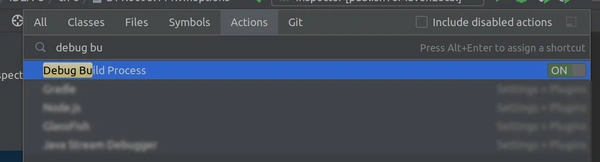
Вам нужно будет повторять этот шаг каждый раз при перезапуске IDEA.
4. Дебажим
Сначала установите точку останова в коде обработчика аннотаций.
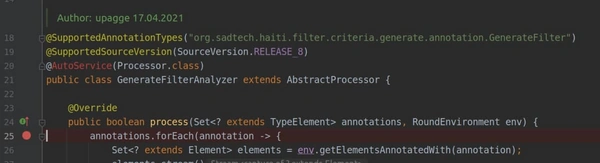
Для запуска вашего обработчика аннотаций пересоберите проект: Build -> Rebuild Project. При выборе пункта Build Project обработчик аннотации может не запуститься.
Процесс сборки приостановится, и вы сможете подключить отладчик:

Теперь запустите добавленную вами конфигурацию в режиме Debug (Shift+F9). Javac возобновит компиляцию. IDEA теперь должна остановиться на установленной вами точке останова.
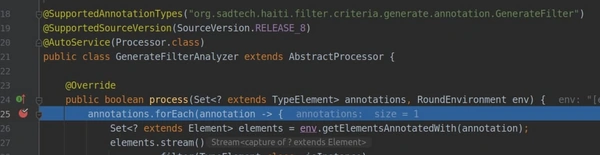
На этом все, теперь вы можете отлаживать ваши обработчики аннотаций.
Прямая компиляция и запуск игры из IntelliJ Idea. Гайд по моддингу AOH2

Теперь переходим в IntelliJ Idea в настройки проекта. Там надо перейти в меню «Artifacts» и создать пустой jar.
В появившемся меню ставим галочку на «Include in Project Build». Затем нам необходимо поменять место компиляции файла, чтобы он компилировался сразу в папку игры (Output Directory)
После этого нужно задать, что будет компилироватся. Для этого нажмите на файл jar, и в открывшемся снизу меню нажмите use existing manifest. Откроется окно выбора директории, там вам надо найти папку с вашими исходниками, а там папку «META-INF» с файлом manifest.mf
После этого вам необходимо указать, что необходимо прокомпилировать. Для этого перенесите все элементы из «Avalibale Elements» прямо в ваш jar файл.
Не забудьте нажать apply иначе все отменится
Теперь при запуске проекта будет открыватся игра, а консоль будет выводить ошибки.