Извлечение всех ссылок web-сайта с помощью Python

Одна из задач, которая стояла в рамках проекта, нацеленного на исследование мер поисковой оптимизации (SEO, search engine optimization) информационных ресурсов дочерних структур организации, предполагала поиск всех ссылок и выявление среди них так называемых «мертвых (битых) ссылок», отсылающих на несуществующий сайт, страницу, файл, что в свою очередь понижает рейтинг информационного ресурса.
В этом посте я хочу поделиться одним из способов извлечения всех ссылок сайта (внутренних и внешних), который поможет при решении подобных задач.
Посмотрим, как можно создать инструмент извлечения ссылок в Python, используя пакет requests и библиотеку BeautifulSoup. Итак,
pip install requests bs4Импортируем необходимые модули:
import requests from urllib.parse import urlparse, urljoin from bs4 import BeautifulSoupЗатем определим две переменные: одну для всех внутренних ссылок (это URL, которые ссылаются на другие страницы того же сайта), другую для внешних ссылок вэб-сайта (это ссылки на другие сайты).
# Инициализировать набор ссылок (уникальные ссылки) int_url = set() ext_url = set()Далее создадим функцию для проверки URL – адресов. Это обеспечит правильную схему в ссылке — протокол, например, http или https и имя домена в URL.
# Проверяем URL def valid_url(url): parsed = urlparse(url) return bool(parsed.netloc) and bool(parsed.scheme)На следующем шаге создадим функцию, возвращающую все действительные URL-адреса одной конкретной веб-страницы:
# Возвращаем все URL-адреса def website_links(url): urls = set() # извлекаем доменное имя из URL domain_name = urlparse(url).netloc # скачиваем HTML-контент вэб-страницы soup = BeautifulSoup(requests.get(url).content, "html.parser")Теперь получим все HTML теги, содержащие все ссылки вэб-страницы.
for a_tag in soup.findAll("a"): href = a_tag.attrs.get("href") if href == "" or href is None: # href пустой тег continue
В итоге получаем атрибут href и проверяем его. Так как не все ссылки абсолютные, возникает необходимость выполнить соединение относительных URL-адресов и имени домена. К примеру, когда найден href — «/search» и URL — «google.com» , то в результате получим «google.com/search».
# присоединить URL, если он относительный (не абсолютная ссылка) href = urljoin(url, href)В следующем шаге удаляем параметры HTTP GET из URL-адресов:
parsed_href = urlparse(href) # удалить параметры URL GET, фрагменты URL и т. д. href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path Если URL-адрес недействителен/URL уже находится в int_url , следует перейти к следующей ссылке.
Если URL является внешней ссылкой, вывести его и добавить в глобальный набор ext_url и перейдти к следующей ссылке.
И наконец, после всех проверок получаем URL, являющийся внутренней ссылкой; выводим ее и добавляем в наборы urls и int_url
if not valid_url(href): # недействительный URL continue if href in int_url: # уже в наборе continue if domain_name not in href: # внешняя ссылка if href not in ext_url: print(f"[!] External link: ") ext_url.add(href) continue print(f"[*] Internal link: ") urls.add(href) int_url.add(href) return urls
Напоминаю, что эта функция захватывает ссылки одной вэб-страницы.
Теперь создадим функцию, которая сканирует весь веб-сайт. Данная функция получает все ссылки на первой странице сайта, затем рекурсивно вызывается для перехода по всем извлеченным ссылкам. Параметр max_urls позволяет избежать зависания программы на больших сайтах при достижении определенного количества проверенных URL-адресов.
# Количество посещенных URL-адресов visited_urls = 0 # Просматриваем веб-страницу и извлекаем все ссылки. def crawl(url, max_urls=50): # max_urls (int): количество макс. URL для сканирования global visited_urls visited_urls += 1 links = website_links(url) for link in links: if visited_urls > max_urls: break crawl(link, max_urls=max_urls) Итак, проверим на сайте, к которому имеется разрешение, как все это работает:
if __name__ == "__main__": crawl("https://newtechaudit.ru") print("[+] Total External links:", len(ext_url)) print("[+] Total Internal links:", len(int_url)) print("[+] Total:", len(ext_url) + len(int_url))Вот фрагмент результата работы программы:
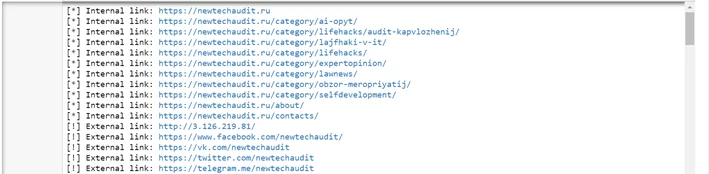
Обратите внимание, что многократный запрос к одному и тому же сайту за короткий промежуток времени может привести к тому, что ваш IP-адрес будет заблокирован. Ссылка на оригинал поста.
Модуль BeautifulSoup4 в Python, разбор HTML
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер html.parser . BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml , html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль beautifulsoup4 (VirtualEnv):~$ python3 -m pip install -U beautifulsoup4
Содержание:
- Выбор парсера для использования в BeautifulSoup4.
- Парсер lxml .
- Парсер html5lib .
- Встроенный в Python парсер html.parser .
- Навигация по структуре HTML-документа.
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу.
- Поиск тегов при помощи CSS селекторов.
- Дочерние элементы.
- Родительские элементы.
- Изменение имен тегов HTML-документа.
- Добавление новых тегов в HTML-документ.
- Удаление и замена тегов в HTML-документе.
- Изменение атрибутов тегов HTML-документа.
Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке: .
Парсер lxml .
- Для запуска примера, необходимо установить модуль lxml .
- Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
>>> from bs4 import BeautifulSoup >>> BeautifulSoup(" ", "lxml") #
Обратите внимание, что тег заключен в теги и , а висячий тег
просто игнорируется.
Парсер html5lib .
- Для запуска примера, необходимо установить модуль html5lib .
- Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
>>> from bs4 import BeautifulSoup >>> BeautifulSoup(" ", "html5lib") #
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег
, и к тому же добавляет открывающий тег
. Также html5lib добавляет пустой тег ( lxml этого не сделал).
Встроенный в Python парсер html.parser .
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как lxml .
- Более строгий, чем html5lib .
>>> from bs4 import BeautifulSoup >>> BeautifulSoup(" ", 'html.parser') #
Как и lxml , встроенный в Python парсер игнорирует закрывающий тег
. В отличие от html5lib , этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги или .
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup() . Можно передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup # передаем объект открытого файла with open("index.html") as fp: soup = BeautifulSoup(fp, 'html.parser') # передаем строку soup = BeautifulSoup("a web page", 'html.parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
>>> from bs4 import BeautifulSoup >>> html = " Sacré bleu!" >>> parse = BeautifulSoup(html, 'html.parser') >>> print(parse) # Sacré bleu!
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
html_doc = """html>head>title>The Dormouse's storytitle>head> body> p class="title">b>The Dormouse's storyb>p> p class="story">Once upon a time there were three little sisters; and their names were a href="http://example.com/elsie" class="sister" id="link1">Elsiea>, a href="http://example.com/lacie" class="sister" id="link2">Laciea> and a href="http://example.com/tillie" class="sister" id="link3">Tilliea>; and they lived at the bottom of a well.p> p class="story">. p>"""Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html_doc, 'html.parser') >>> print(soup.prettify()) # # # # The Dormouse's story # # # #
# # The Dormouse's story # #
## Once upon a time there were three little sisters; and their names were
# # Elsie # # , # # Lacie # # and # # Tillie # # ; and they lived at the bottom of a well. # ## .
# #