Mikrotik. Два провайдера. Балансировка.
Итак, у нас есть роутер, который соединяет нашу локальную сеть и два канала в интернет (основной ISP1 и резервный ISP2).
Давайте рассмотрим что же мы можем сделать:
Сразу предупрежу: несмотря на то, что в этой статье буду все описывать для mikrotik, не буду касаться темы скриптов
Failover
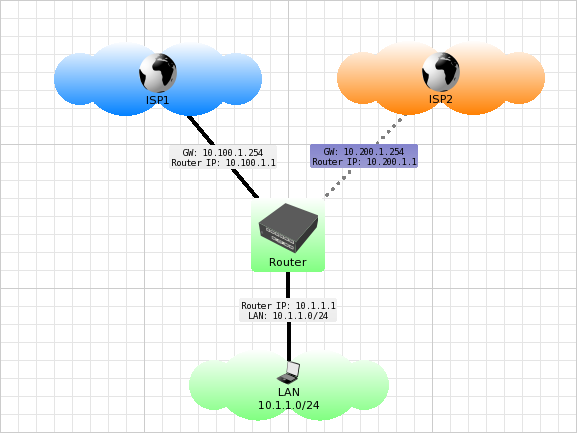
У нас появился резервный канал, в который можно направить трафик при отказе основного. Но как сделать, чтобы mikrotik понял, что канал упал?
Простейшее резервирование каналов
Простейший failover можно настроить, используя приоритет маршрута (distance у mikrotik/cisco, metric в linux/windows), а так же механизм проверки доступности шлюза — check-gateway.
В приведенной ниже конфигурации весь интернет трафик по умолчанию ходит через 10.100.1.254 (ISP1). Но как только адрес 10.100.1.254 станет недоступным (а маршрут через него неактивным) — трафик пойдет через 10.200.1.254 (ISP2).
конфигурация: простейший failover
# Настроим сети провайдеров: /ip address add address=10.100.1.1/24 interface=ISP1 /ip address add address=10.200.1.1/24 interface=ISP2 # Настроим локальный интерфейс /ip address add address=10.1.1.1/24 interface=LAN # скроем за NAT все что выходит из локальной сети /ip firewall nat add src-address=10.1.1.0/24 action=masquerade chain=srcnat ###Обеспечение резервирования каналов традиционным способом### # укажем 2 default gateway с разными приоритетами /ip route add dst-address=0.0.0.0/0 gateway=10.100.1.254 distance=1 check-gateway=ping /ip route add dst-address=0.0.0.0/0 gateway=10.200.1.254 distance=2 check-gateway=ping check-gateway=ping для mikrotik обрабатывается так:Периодически (каждые 10 секунд) шлюз проверяется отсылкой на него ICMP пакета (ping). Потерянным пакет считается, если он не вернулся в течении 10 секунд. После двух потерянных пакетов шлюз считается недоступным. После получения ответа от шлюза он становится доступным и счетчик потерянных пакетов сбрасывается.
Обеспечение failover с более глубоким анализом канала
В прошлом примере все замечательно, кроме ситуации, когда шлюз провайдера виден и пингуется, но интернета за ним нет. Нам бы это здорово помогло, если бы можно было принимать решение о жизнеспособности провайдера, пингуя не сам шлюз, а что-то за ним.
Я знаю два варианта решения этой инженерной задачи. Первый и самый распространенный — использовать скрипты, но так как в этой статье мы скрипты не трогаем, остановимся подробнее на втором. Он подразумевает не совсем корректное использование параметра scope, но поможет нам прощупать канал провайдера глубже, чем до шлюза.
Принцип прост:
Вместо традиционного указания default gateway=шлюз провайдера, мы скажем роутеру что default gateway это какой-то из всегда_доступных_узлов (например 8.8.8.8 или 8.8.4.4) и он в свою очередь доступен через шлюз провайдера.
конфигурация: failover с более глубоким анализом канала
# Настроим сети провайдеров: /ip address add address=10.100.1.1/24 interface=ISP1 /ip address add address=10.200.1.1/24 interface=ISP2 # Настроим локальный интерфейс /ip address add address=10.1.1.1/24 interface=LAN # скроем за NAT все что выходит из локальной сети /ip firewall nat add src-address=10.1.1.0/24 action=masquerade chain=srcnat ###Обеспечение failover c более глубоким анализом канала### #с помощью параметра scope укажем рекурсивные пути к узлам 8.8.8.8 и 8.8.4.4 /ip route add dst-address=8.8.8.8 gateway=10.100.1.254 scope=10 /ip route add dst-address=8.8.4.4 gateway=10.200.1.254 scope=10 # укажем 2 default gateway через узлы путь к которым указан рекурсивно /ip route add dst-address=0.0.0.0/0 gateway=8.8.8.8 distance=1 check-gateway=ping /ip route add dst-address=0.0.0.0/0 gateway=8.8.4.4 distance=2 check-gateway=ping Теперь разберем, что происходит чуть подробнее:
Хитрость в том, что шлюз провайдера не знает о том, что 8.8.8.8 или 8.8.4.4 — это роутер и направит трафик по обычному пути.
Наш mikrotik считает, что по умолчанию весь интернет трафик нужно отправлять на 8.8.8.8, который напрямую не виден, но через 10.100.1.254 доступен. А если пинг на 8.8.8.8 пропадает (напомню что путь к нему у нас жестко указан через шлюз от ISP1) то mikrotik начнет слать весь интернет трафик на 8.8.4.4, а точнее на рекурсивно определенный 10.200.1.254 (ISP2).
Но у меня пару раз возникала ситуация, когда интернет через шлюз провайдера работает, а вот конкретный узел или сеть нет. В таких случаях вышеописанный метод не очень-то помогает и для обеспечения бесперебойной работы мне приходилось проверять доступность узла уже с помощью скриптов. Кстати, если кто знает решение файловера на один внешний хост без применения скриптов и протоколов динамической маршрутизации — поделитесь рецептом.
Load Balancing
Теперь давайте рассмотрим другую схему:
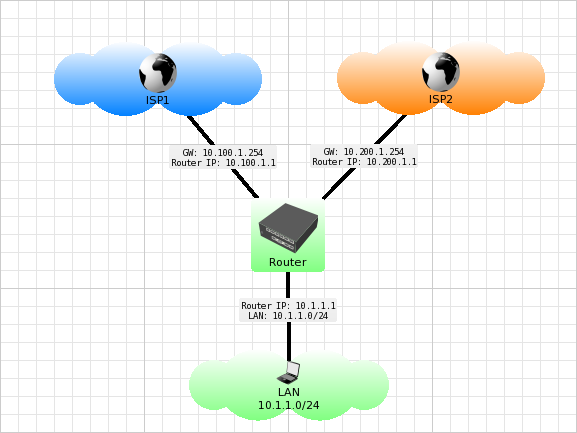
В ней второй второй канал уже не резервный, а равноценный. Почему бы не использовать оба канала одновременно, повысив таким образом пропускную способность?
Начинаем настраивать Load Balancing
Первое правило Load Balancing — следить за соединениями: на пришедшее извне соединение отвечать с того же адреса, на который оно пришло. Для исходящих соединений — отправлять пакеты только через тот адрес, с которым установилось соединение.
Второе, что тоже важно понимать — нужно разделять понятия входящего и исходящего трафика. Дело в том, что для исходящего трафика роутер может решать, по какому пути он пойдет, а входящий трафик для него как «трафик Шредингера». Пока его нет, наш mikrotik не знает, через какой интерфейс он придет, а когда пришел — менять интерфейс уже поздно.
Третье — балансировка каналов не является резервированием. Это две отдельные функции.
Кстати почему при разделе трафика мы оперируем соединениями, а не пакетами?Почитайте, как работает TCP протокол. Если коротко — задача TCP протокола не только швырнуть пакетом в получателя, но и проконтролировать, как тот его принял. Делается это с помощью установки соединения, в рамках которого, собственно, и передаются пакеты данных — вместе со служебной информацией. Если оперировать пакетами и забыть про соединения, то возможны ситуации, когда удаленный хост, установив соединение с одним адресом, просто отбросит часть пакетов пришедшую со второго — «неправильного» адреса.
Готовимся принять «трафик Шредингера»
Итак, при любом варианте балансировки канала нам нужно сначала подготовиться к принятию входящего трафика и научить mikrotik отвечать на входящие соединения в тот же канал, из которого они пришли. С помощью маркировки соединений и последующей маркировки маршрутов для них мы, по сути, делаем несколько таблиц маршрутизации, отдельных для каждого внешнего адреса.
начальная конфигурация для load balancing с двумя внешними IP адресами
# Настроим сети провайдеров: /ip address add address=10.100.1.1/24 interface=ISP1 /ip address add address=10.200.1.1/24 interface=ISP2 # Настроим локальный интерфейс /ip address add address=10.1.1.1/24 interface=LAN # скроем за NAT все что выходит из локальной сети /ip firewall nat add src-address=10.1.1.0/24 action=masquerade chain=srcnat #Пометим каждое соединение пришедшее снаружи и адресованное нашему роутеру: /ip firewall mangle add action=mark-connection chain=input in-interface=ISP1 new-connection-mark=cin_ISP1 /ip firewall mangle add action=mark-connection chain=input in-interface=ISP2 new-connection-mark=cin_ISP2 #что бы отвечать через те же интерфейсы, откуда пришли запросы, поставим соответствующую роутинг-марку на каждое соединение. /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP1 new-routing-mark=rout_ISP1 passthrough=no /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP2 new-routing-mark=rout_ISP2 passthrough=no #добавим default gateway в каждую из промаркированных таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=rout_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=rout_ISP2 check-gateway=ping Таким образом mikrotik будет проводить каждый пакет помеченного соединения по соответствующей таблице маршрутизации и внешние адреса (10.100.1.1, 10.200.1.1) будут доступны извне без путаницы в каналах и маршрутах.
Делим исходящий трафик
Для распределения исходящего трафика по интерфейсам, нам всего-то нужно повесить соответствующую марку маршрута на соединение. Сложность в том, что нужно решить на какое соединение вешать метку ISP1, а на какое ISP2.
Существует несколько вариантов разделения соединений по группам:
1) Делим исходящий трафик, прикручивая марку намертво
Правила, балансирующие трафик мы можем прописать жестко:
Например мы хотим настроить важные для нас протоколы HTTP(80 port), HTTPS (443 port), POP (110 port), SMTP (25 port) через ISP1, а весь остальной трафик пустить через второго провайдера:
конфигурация с балансировкой канала по жестко прописанным правилам
# Настроим сети провайдеров: /ip address add address=10.100.1.1/24 interface=ISP1 /ip address add address=10.200.1.1/24 interface=ISP2 # Настроим локальный интерфейс /ip add address=10.1.1.1/24 interface=LAN # скроем за NAT все что выходит из локальной сети /ip firewall nat add src-address=10.1.1.0/24 action=masquerade chain=srcnat #Пометим каждое соединение пришедшее снаружи и адресованное нашему роутеру: /ip firewall mangle add action=mark-connection chain=input in-interface=ISP1 new-connection-mark=cin_ISP1 /ip firewall mangle add action=mark-connection chain=input in-interface=ISP2 new-connection-mark=cin_ISP2 #что бы отвечать через те же интерфейсы, откуда пришли запросы, поставим соответствующую роутинг-марку на каждое соединение. /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP1 new-routing-mark=rout_ISP1 passthrough=no /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP2 new-routing-mark=rout_ISP2 passthrough=no #добавим default gateway в каждую из промаркированных таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=rout_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=rout_ISP2 check-gateway=ping #failover через второго провайдера для каждого из шлюзов /ip route add distance=2 gateway=10.200.1.254 routing-mark=rout_ISP1 /ip route add distance=2 gateway=10.100.1.254 routing-mark=rout_ISP2 # отправим трафик идущий к портам 80,443,110,25 на ISP1 /ip firewall mangle add chain=prerouting action=mark-routing new-routing-mark="lan_out_ISP1" passthrough=no dst-port=80,443,110,25 protocol=tcp #а весь остальной трафик на ISP2: /ip firewall add chain=prerouting action=mark-routing new-routing-mark="lan_out_ISP2" passthrough=no #добавим default gateway в каждую из промаркированных для LAN трафика таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=lan_out_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=lan_out_ISP2 check-gateway=ping #failover через второго провайдера для каждого из шлюзов /ip route add distance=2 gateway=10.200.1.254 routing-mark=lan_out_ISP1 /ip route add distance=2 gateway=10.100.1.254 routing-mark=lan_out_ISP2 2) Делим исходящий трафик, выбирая каждое Н-ое соединение
Можем делить соединения по-порядку. Первые налево, вторые — направо. Все просто.
конфигурация с балансировкой канала по Н-ному соединению:
# Настроим сети провайдеров: /ip address add address=10.100.1.1/24 interface=ISP1 /ip address add address=10.200.1.1/24 interface=ISP2 # Настроим локальный интерфейс /ip address add address=10.1.1.1/24 interface=LAN # скроем за NAT все что выходит из локальной сети /ip firewall nat add src-address=10.1.1.0/24 action=masquerade chain=srcnat #Пометим каждое соединение пришедшее снаружи и адресованное нашему роутеру: /ip firewall mangle add action=mark-connection chain=input in-interface=ISP1 new-connection-mark=cin_ISP1 /ip firewall mangle add action=mark-connection chain=input in-interface=ISP2 new-connection-mark=cin_ISP2 #что бы отвечать через те же интерфейсы, откуда пришли запросы, поставим соответствующую роутинг-марку на каждое соединение. /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP1 new-routing-mark=rout_ISP1 passthrough=no /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP2 new-routing-mark=rout_ISP2 passthrough=no #добавим default gateway в каждую из промаркированных для внешних адресов таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=rout_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=rout_ISP2 check-gateway=ping #из каждых двух соединений первое пометим на отсылку через ISP1 /ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=lan_out_ISP1 nth=2,1 #а второе на отсылку через ISP2 /ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=lan_out_ISP2 nth=2,2 #добавим default gateway в каждую из промаркированных для LAN трафика таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=lan_out_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=lan_out_ISP2 check-gateway=ping #failover через второго провайдера для каждого из шлюзов /ip route add distance=2 gateway=10.200.1.254 routing-mark=lan_out_ISP1 /ip route add distance=2 gateway=10.100.1.254 routing-mark=lan_out_ISP2 3) Делим исходящий трафик, используя PCC (per connection classifier)
PCC подходит к дележу трафика чуть сложнее. Он разделяет трафик по группам, основываясь на данных TCP заголовка (src-address, dst-address, src-port, dst-port).
конфигурация с балансировкой канала по PPC:
# Настроим сети провайдеров: /ip address add address=10.100.1.1/24 interface=ISP1 /ip address add address=10.200.1.1/24 interface=ISP2 # Настроим локальный интерфейс /ip address add address=10.1.1.1/24 interface=LAN # скроем за NAT все что выходит из локальной сети /ip firewall nat add src-address=10.1.1.0/24 action=masquerade chain=srcnat #Пометим каждое соединение пришедшее снаружи и адресованное нашему роутеру: /ip firewall mangle add action=mark-connection chain=input in-interface=ISP1 new-connection-mark=cin_ISP1 /ip firewall mangle add action=mark-connection chain=input in-interface=ISP2 new-connection-mark=cin_ISP2 #что бы отвечать через те же интерфейсы, откуда пришли запросы, поставим соответствующую роутинг-марку на каждое соединение. /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP1 new-routing-mark=rout_ISP1 passthrough=no /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP2 new-routing-mark=rout_ISP2 passthrough=no #добавим default gateway в каждую из промаркированных таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=rout_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=rout_ISP2 check-gateway=ping #failover через второго провайдера для каждого из шлюзов /ip route add distance=2 gateway=10.200.1.254 routing-mark=rout_ISP1 /ip route add distance=2 gateway=10.100.1.254 routing-mark=rout_ISP2 #используя PPC разделим трафик на две группы по исх. адресу и порту /ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=lan_out_ISP1 per-connection-classifier=src-address-and-port:2/0 /ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=lan_out_ISP2 per-connection-classifier=src-address-and-port:2/1 #добавим default gateway в каждую из промаркированных для LAN трафика таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=lan_out_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=lan_out_ISP2 check-gateway=ping #failover через второго провайдера для каждого из шлюзов /ip route add distance=2 gateway=10.200.1.254 routing-mark=lan_out_ISP1 /ip route add distance=2 gateway=10.100.1.254 routing-mark=lan_out_ISP2 Делим исходящий трафик, используя ECMP (equal cost multipath routing)
На мой взгляд самый простой и вкусный вариант разделения траффика:
конфигурация с балансировкой канала по ECMP
# Настроим сети провайдеров: /ip address add address=10.100.1.1/24 interface=ISP1 /ip address add address=10.200.1.1/24 interface=ISP2 # Настроим локальный интерфейс /ip address add address=10.1.1.1/24 interface=LAN # скроем за NAT все что выходит из локальной сети /ip firewall nat add src-address=10.1.1.0/24 action=masquerade chain=srcnat #Пометим каждое соединение пришедшее снаружи и адресованное нашему роутеру: /ip firewall mangle add action=mark-connection chain=input in-interface=ISP1 new-connection-mark=cin_ISP1 /ip firewall mangle add action=mark-connection chain=input in-interface=ISP2 new-connection-mark=cin_ISP2 #что бы отвечать через те же интерфейсы, откуда пришли запросы, поставим соответствующую роутинг-марку на каждое соединение. /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP1 new-routing-mark=rout_ISP1 passthrough=no /ip firewall mangle add action=mark-routing chain=output connection-mark=cin_ISP2 new-routing-mark=rout_ISP2 passthrough=no #добавим default gateway в каждую из промаркированных таблиц маршрутизации: /ip route add distance=1 gateway=10.100.1.254 routing-mark=rout_ISP1 check-gateway=ping /ip route add distance=1 gateway=10.200.1.254 routing-mark=rout_ISP2 check-gateway=ping #промаркируем весь траффик из локальной сети /ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=mixed #используем ECMP для балансировки траффика из локальной сети /ip route add dst-address=0.0.0.0/0 gateway=10.100.1.254,10.200.1.254 routing-mark=mixed Mikrotik сам поделит трафик по шлюзам, используя round-robin алгоритм.
Кстати, в версии 6.Х RouterOS mikrotik поломал check-gateway в ECMP, так что использовать конструкцию
/ip route add gateway=10.100.1.254,10.200.1.254 check-gateway=ping можно и логично, но абсолютно бесполезно.
Для пометки неживых маршрутов в ECMP нужно создать дополнительные маршруты, которые используют каждый из gateway по-отдельности. С включенным check-gateway разумеется. Помечая маршрут неактивным, mikrotik делает это для всех.
И последнее немаловажное замечание про скорость каналов
Возьмем 2 неравнозначных канала, например, 100 мбит и 50 мбит. Сбалансируем их через Nth, PCC или ECMP. Какую суммарную пропускную способность получим?
На самом деле — где-то около 100 мбит (самый слабый канал Х раз).
Происходит это потому, что mikrotik понятия не имеет о пропускной способности каналов, он ее не измеряет. Он просто делит трафик на относительно равные группы.
Побороть этот нюанс можно правильно проектируя группы исходящего трафика, с учетом пропускной способности каналов.
Напримерв ECMP это можно сделать указав более скоростной шлюз несколько раз, тем самым повышая частоту его использования.
/ip route add dst-address=0.0.0.0/0 gateway=10.100.1.254,10.100.1.254,10.200.1.254 В PCC тоже можно сделать неравные группы:
/ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=lan_out_ISP1 per-connection-classifier=src-address-and-port:3/0 /ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=lan_out_ISP1 per-connection-classifier=src-address-and-port:3/1 /ip firewall mangle add src-address=10.1.1.0/24 action=mark-routing chain=prerouting new-routing-mark=lan_out_ISP2 per-connection-classifier=src-address-and-port:3/2 Спасибо за внимание.
Удачи в настройках безотказных систем маршрутизации.
Заказать услугу
Оформите заявку на сайте, мы свяжемся с вами в ближайшее время и ответим на все интересующие вопросы.
Правильный DST NAT при использовании 2-х и более провайдеров на Mikrotik
Приступая к выполнению задачи я рассчитывал на легкую прогулку в тени дубового парка, созерцая природу и предаваясь размышлениям… Однако позже стало понятно, что это будет тернистый и сложный поход сквозь горные реки с подводными камнями, обледеневшими скалами и глубокими пещерами. Через медитации, борьбу со стихиями и собственной тупостью преодоление себя я, все таки, достиг желанной нирваны.
В этой статье я не только предоставлю готовый набор правил, но и постараюсь максимально доступно объяснить почему и как именно они работают.
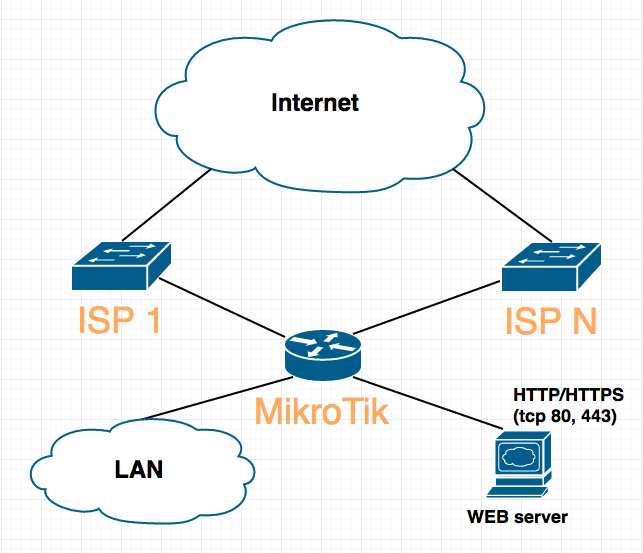
Конкретно в моем случае, нужно было настроить роутер так, чтобы web-сервер в локальной сети за ним был доступен по IP любого из 3-х провайдеров.
Часть 1.
Для начала пробежимся по всем настройкам, дабы самые нетерпеливые могли скопипастить не читая.
Версия RouterOS:
# oct/11/2016 22:02:32 by RouterOS 6.37.1 # software />
Интерфейсы:
/interface list add name=WAN /interface list member add interface=ISP1 list=WAN add interface=ISP2 list=WAN add interface=ISP3 list=WAN Не помню начиная с какой версии RouterOS появилась эта фишка. Она позволяет группировать интерфейсы, что весьма удобно (например, в правилах /ip firewall). У меня создана группа из 3-х WAN-интерфейсов.
IP-адреса (адреса, по понятным причинам, «левые»):
/ip address add address=192.168.0.1/24 comment=defconf interface=bridge network=192.168.0.0 add address=95.11.29.240/24 interface=ISP1 network=95.11.29.0 add address=5.35.59.162/27 interface=ISP2 network=5.35.59.160 add address=5.98.112.30/30 interface=ISP3 network=5.98.112.28 Роутинг:
/ip route add distance=1 gateway=95.11.29.254 routing-mark=ISP1-route add distance=1 gateway=5.35.59.161 routing-mark=ISP2-route add distance=1 gateway=5.98.112.29 routing-mark=ISP3-route add check-gateway=ping distance=1 gateway=8.8.8.8 add check-gateway=ping distance=2 gateway=8.8.4.4 add check-gateway=ping distance=3 gateway=1.1.36.3 add distance=1 dst-address=8.8.4.4/32 gateway=5.35.59.161 scope=10 add distance=1 dst-address=8.8.8.8/32 gateway=95.11.29.254 scope=10 add distance=1 dst-address=1.1.36.3/32 gateway=5.98.112.29 scope=10 Для организации Failover’а я настроил рекурсивную маршрутизацию, подробнее расскажу в 2-ой части.
Firewall (для данной публикации я сознательно привожу правила, разрешающие все. Не делайте так!):
/ip firewall filter add action=accept chain=forward add action=accept chain=input add action=accept chain=output dst и src nat:
/ip firewall nat add action=masquerade chain=srcnat out-interface-list=WAN add action=dst-nat chain=dstnat comment="HTTP" dst-port=80 \ in-interface-list=WAN protocol=tcp to-addresses=192.168.0.83 to-ports=80 add action=dst-nat chain=dstnat comment="HTTPs" dst-port=443 \ in-interface-list=WAN protocol=tcp to-addresses=192.168.0.83 to-ports=443 mangle
/ip firewall mangle add action=mark-connection chain=input in-interface=ISP1 \ new-connection-mark=ISP1-conn passthrough=yes add action=mark-routing chain=output connection-mark=ISP1-conn \ new-routing-mark=ISP1-route passthrough=no add action=mark-connection chain=input in-interface=ISP2 new-connection-mark=\ ISP2-conn passthrough=yes add action=mark-routing chain=output connection-mark=ISP2-conn \ new-routing-mark=ISP2-route passthrough=no add action=mark-connection chain=input in-interface=ISP3 \ new-connection-mark=ISP3-conn passthrough=yes add action=mark-routing chain=output connection-mark=ISP3-conn \ new-routing-mark=ISP3-route passthrough=no add action=mark-connection chain=forward in-interface=ISP1 \ new-connection-mark=ISP1-conn-f passthrough=no add action=mark-routing chain=prerouting connection-mark=ISP1-conn-f \ in-interface=bridge new-routing-mark=ISP1-route add action=mark-connection chain=forward in-interface=ISP2 \ new-connection-mark=ISP2-conn-f passthrough=no add action=mark-routing chain=prerouting connection-mark=ISP2-conn-f \ in-interface=bridge new-routing-mark=ISP2-route add action=mark-connection chain=forward in-interface=ISP3 \ new-connection-mark=ISP3-conn-f passthrough=no add action=mark-routing chain=prerouting connection-mark=ISP3-conn-f \ in-interface=bridge new-routing-mark=ISP3-route Часть 2.
Рассмотрим все подробнее.
Роутинг:
/ip route add distance=1 gateway=95.11.29.254 routing-mark=ISP1-route add distance=1 gateway=5.35.59.161 routing-mark=ISP2-route add distance=1 gateway=5.98.112.29 routing-mark=ISP3-route add check-gateway=ping distance=1 gateway=8.8.8.8 add check-gateway=ping distance=2 gateway=8.8.4.4 add check-gateway=ping distance=3 gateway=1.1.36.3 add distance=1 dst-address=8.8.4.4/32 gateway=5.35.59.161 scope=10 add distance=1 dst-address=8.8.8.8/32 gateway=95.11.29.254 scope=10 add distance=1 dst-address=1.1.36.3/32 gateway=5.98.112.29 scope=10 /ip route
В первых трех строчках мы указываем default gateway каждого из 3-х наших провайдеров. Маршруты имеют одинаковый вес (distance), но работают в разных таблицах маршрутизации.
Другими словами, эти маршруты работают для пакетов промаркированных соответствующим тегом (routing-mark). Теги пакетам мы будем навешивать в /ip firewall mangle (о чем я подобно расскажу ниже).
Следующие 3 строки — указание маршрутов по умолчанию в основной таблице маршрутизации.
Здесь стоит обратить внимание на:
-
Параметр distance. Для каждого маршрута разный и, соответственно, «вес» маршрутов тоже разный.
MikroTik. Nexthop_lookup
Английский статьи http://wiki.mikrotik.com/wiki/Manual:IP/Route, на мой взгляд, слегка упорот. Это не Cisco CCNA Exploration, который читается на одном дыхании, но я постараюсь перевести ее отрывок максимально понятно. Если где-то увидите такую же упоротость, поправьте меня, пожалуйста.
Во-первых, определимся с некоторыми терминами.
Nexthop — следующий прыжок, если дословно. Следующий шлюз/роутер/маршрутизатор на пути следования пакета из точки А(от моего роутера, например) в точку Б (допустим до гуглового DNS 8.8.8.8), т.е. следующий транзитный участок, на котором будет обрабатываться пакет. В переводе будет использоваться словосочетание “следующий хоп” (простите за англицизм).
Immediate nexthop — следующий шлюз/роутер/маршрутизатор на пути следования пакета из точки А в точку Б, доступный непосредственно. Для моего домашнего MikroTik, с маршрутом по-умолчанию:
dst-address=0.0.0.0/0 gateway=89.189.163.1 gateway-status=89.189.163.1 reachable via ether1-gateway89.189.163.1 — это и есть immediate nexthop, т.к. доступен он через ether1-gateway. В переводе будет использоваться словосочетание “непосредственно доступный следующий хоп”.
Connected route — связанный маршрут. Маршрут, шлюз которого доступен непосредственно.
Gateway — сетевой шлюз/роутер/маршрутизатор. Я буду пользоваться всеми тремя вариантами перевода.
scope — Используется в механизме поиска следующего хопа, т.е. решения какой же хоп станет следующим. Нужный маршрут может быть выбран только среди маршрутов, значения scope которых меньше либо равно значению target-scope. Значения по-умолчанию зависят от протокола:
- связанные маршруты: 10 (если интерфейс запущен(running))
- OSPF, RIP, MME маршруты: 20
- статические маршруты: 30
- BGP маршруты: 40
- связанные маршруты: 200 (если интерфейс не запущен)
target-scope — Используется в механизме поиска следующего хопа, т.е. решения какой же хоп станет следующим. Это максимальное значение параметра scope для маршрута, посредством которого может быть найден следующий хоп. Для iBGP значение установленно в 30 по-умолчанию.
Табличка значений обоих параметров.
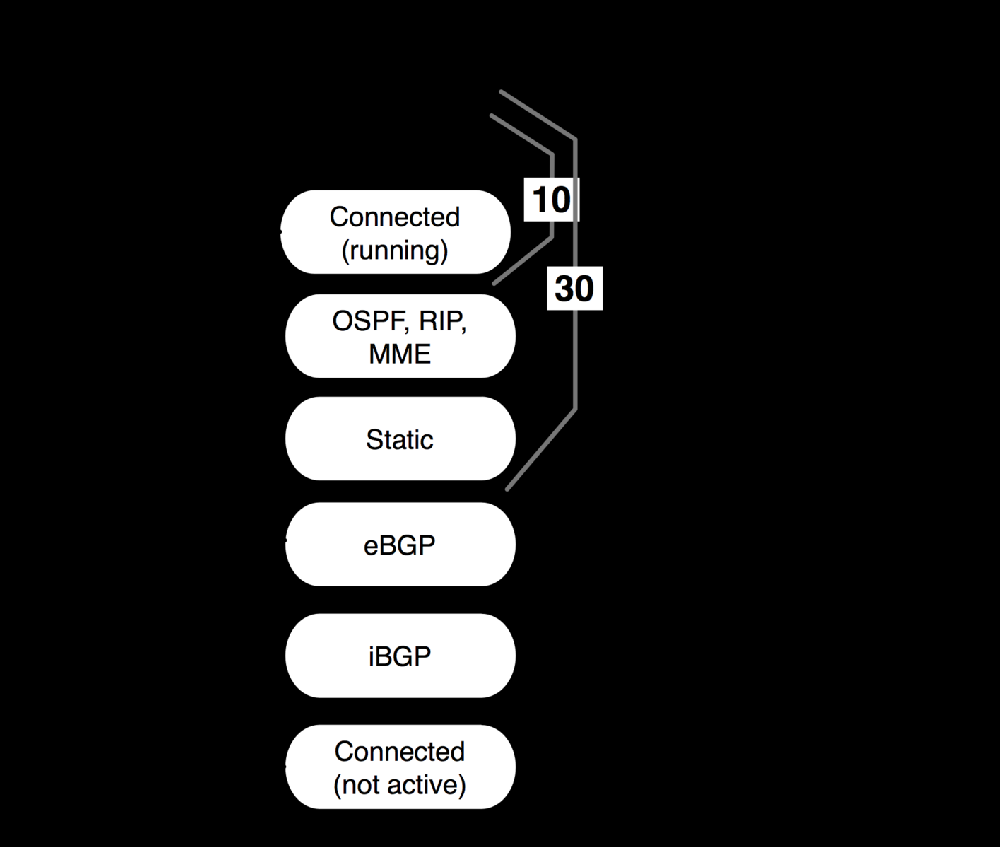
Поиск следующего хопа. Поиск следующего хопа является частью процесса выбора маршрута.
Маршрутам, находящимся в FIB, нужен интерфейс, соответствующий каждому из адресов шлюзов. Адрес следующего хопа-шлюза должен быть непосредственно доступен через этот интерфейс. Интерфейс, который следует использовать для посылки исходящего пакета каждому из шлюзов, находится с помощью поиска следующего хопа.
Некоторые маршруты (например, iBGP), в качестве адреса шлюза, могут иметь адрес принадлежащий маршрутизатору, находящемуся через несколько прыжков-шлюзов от нашего MikroTik. Для установки таких маршрутов в FIB необходимо найти адрес шлюза, доступного непосредственно (an immediate nexthop), т.е. напрямую от нас, который и будет использоваться для достижения адреса шлюза в этом маршруте. Непосредственный адрес следующего хопа также может быть найден при помощи механизма поиска следующего хопа.
Поиск следующего хопа выполняется только в основной таблице маршрутизации main, даже для маршрутов, имеющих отличное значение параметра routing-mark. Это необходимо для ограничения установки маршрутов, которые могут быть использованы для поиска непосредственно доступных хопов (immediate nexthops). В маршрутах для протоколов RIP или OSPF предполагается, что следующий маршрутизатор доступен непосредственно и должен быть найдены используя только связанные маршруты(connected routes).
Маршруты с именем интерфейса в качестве шлюза не используются в поиске следующего хопа. Если есть маршрут с именем интерфейса, а также маршрут с активным IP-адресом, то маршрут с интерфейсом игнорируется.
Маршруты, имеющие значение параметра scope больше максимально допустимого не используются в поиске следующего хопа. В каждом маршруте указывается максимально допустимое значение параметра scope, для его следующего хопа, в параметре target-scope. Значение по-умолчанию для этого параметра позволяет выполнить поиск следующего хопа только через связанные маршруты (connected routes), за исключением iBGP-маршрутов, которые имеют большее значение по-умолчанию и могут выполнить поиск следующего хопа также через IGP и статические маршруты.
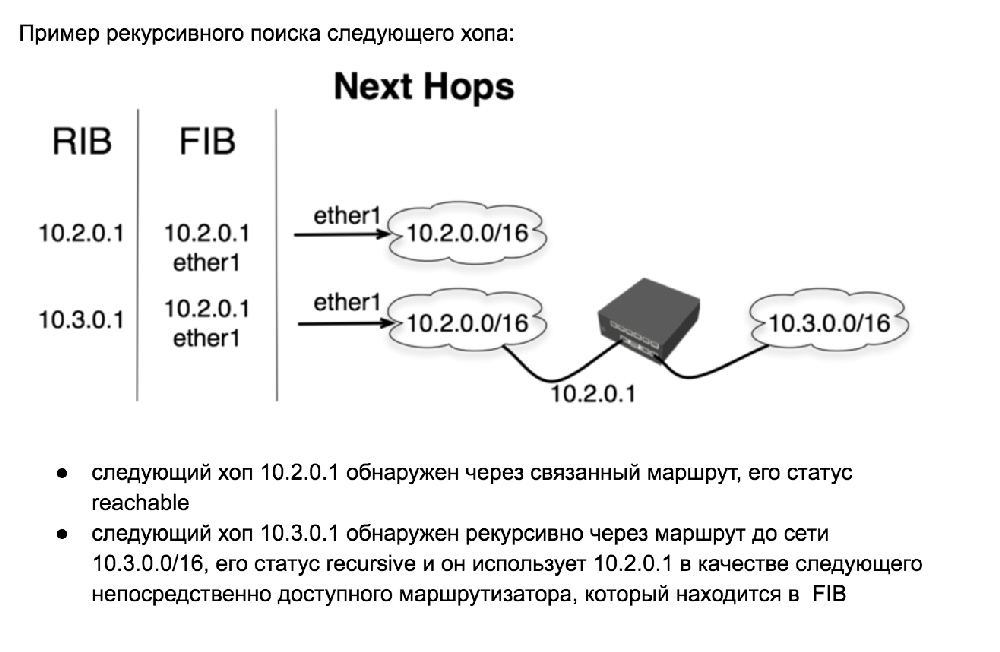
Интерфейс и адрес следующего непосредственно доступного маршрутизатора выбираются основываясь на результатах поиска следующего хопа:
- Если наиболее точный активный маршрут, который был обнаружен в ходе поиска адреса следующего хопа, является связанным маршрутом, то интерфейс этого связанного маршрута используется как интерфейс следующего хопа и шлюз помечается как reachable. После того как маршрутизатор становится непосредственно доступным через этот интерфейс (именно это и следует понимать как “связанный маршрут” или “connected route”) его адрес используется как адрес непосредственно доступного маршрутизатора (immediate nexthop address).
- Если наиболее точный активный маршрут, который был обнаружен в ходе поиска адреса следующего хопа, имеет адрес шлюза, который уже был обнаружен, непосредственно доступный хоп и интерфейс копируются с этого маршрута, а шлюз помечается как recursive.
- Если наиболее точный активный маршрут, который был обнаружен в ходе поиска адреса следующего хопа является ECMP маршрутом, то используется первый доступный маршрутизатор этого маршрута.
- Если механизм поиска адреса следующего хопа не нашел ни одного маршрута, то шлюз помечается как unreachable.
А теперь, как говорят в КВН, зачем же я показал этот номер. Обратите внимание, мы устанавливаем scope=10 для статических маршрутов в последних трех строках, тем самым «заставляем» MikroTik принимать во внимание эти маршруты при поиске следующего хопа.
Он и принимает, и таким образом маршруты по-умолчанию через:
Cтановятся recursive, т.е. непосредственно доступными хопами будут шлюзы провайдеров и трафик мы пошлем через них, но check-gateway=ping будет проверять доступность адресов ЗА провайдерскими сетями.
Надеюсь мой перевод и объяснение будут вам полезны.
Пока самые охочие до знаний читают под спойлером, расскажу немого короче и проще. Когда мы указываем scope=10 в последних трех строках, мы даем понять MikroTik’у, что:
ему доступны не напрямую, а рекурсивно через данные статические маршруты. По одному IP на брата-провайдера.
/ip firewall mangle
/ip firewall mangle add action=mark-connection chain=input in-interface=ISP1 \ new-connection-mark=ISP1-conn passthrough=yes add action=mark-routing chain=output connection-mark=ISP1-conn \ new-routing-mark=ISP1-route passthrough=no add action=mark-connection chain=input in-interface=ISP2 new-connection-mark=\ ISP2-conn passthrough=yes add action=mark-routing chain=output connection-mark=ISP2-conn \ new-routing-mark=ISP2-route passthrough=no add action=mark-connection chain=input in-interface=ISP3 \ new-connection-mark=ISP3-conn passthrough=yes add action=mark-routing chain=output connection-mark=ISP3-conn \ new-routing-mark=ISP3-route passthrough=no add action=mark-connection chain=forward in-interface=ISP1 \ new-connection-mark=ISP1-conn-f passthrough=no add action=mark-routing chain=prerouting connection-mark=ISP1-conn-f \ in-interface=bridge new-routing-mark=ISP1-route add action=mark-connection chain=forward in-interface=ISP2 \ new-connection-mark=ISP2-conn-f passthrough=no add action=mark-routing chain=prerouting connection-mark=ISP2-conn-f \ in-interface=bridge new-routing-mark=ISP2-route add action=mark-connection chain=forward in-interface=ISP3 \ new-connection-mark=ISP3-conn-f passthrough=no add action=mark-routing chain=prerouting connection-mark=ISP3-conn-f \ in-interface=bridge new-routing-mark=ISP3-route Для пояснения правил этого раздела пригласим несколько помощников.
1. MANGLE — данная таблица предназначена для операций по классификации и маркировке пакетов и соединений, а также модификации заголовков пакетов (поля TTL и TOS) (викиучебник).
Таблица mangle содержит следующие цепочки:
- PREROUTING — позволяет модифицировать пакет до принятия решения о маршрутизации.
- INPUT — позволяет модифицировать пакет, предназначенный самому хосту.
- FORWARD — цепочка, позволяющая модифицировать транзитные пакеты.
- OUTPUT — позволяет модифицировать пакеты, исходящие от самого хоста.
- POSTROUTING — дает возможность модифицировать все исходящие пакеты, как сгенерированные самим хостом, так и транзитные.
2. CONNECTION TRACKING — специальная подсистема, отслеживающая состояния соединений и позволяющая использовать эту информацию при принятии решений о судьбе отдельных пакетов.
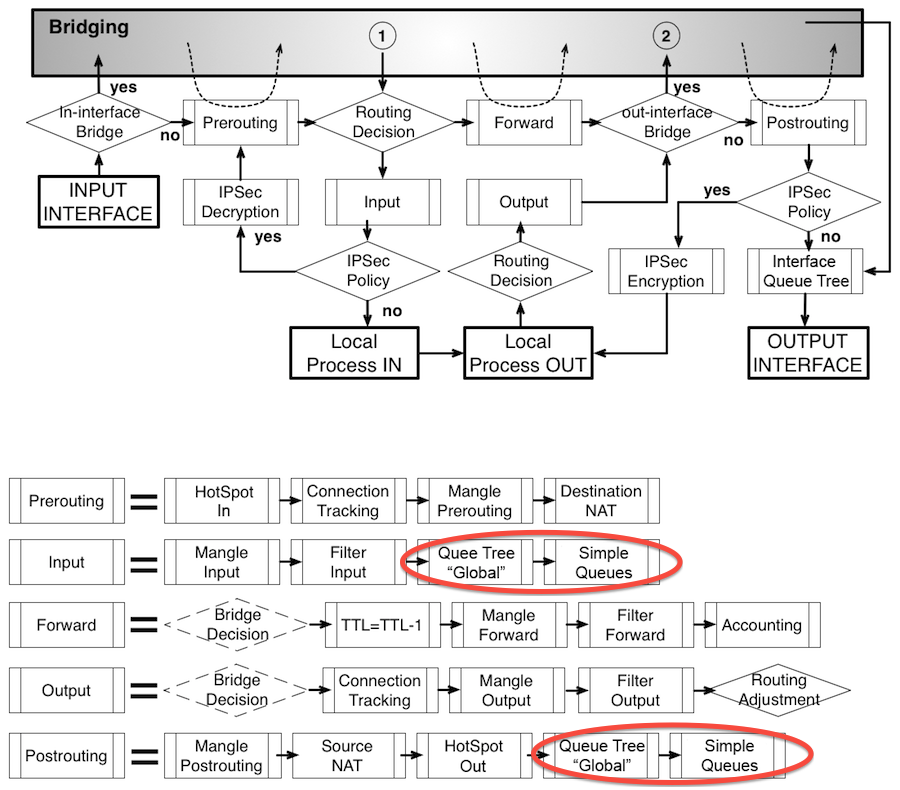
3. Packet flow MikroTik’а
4.
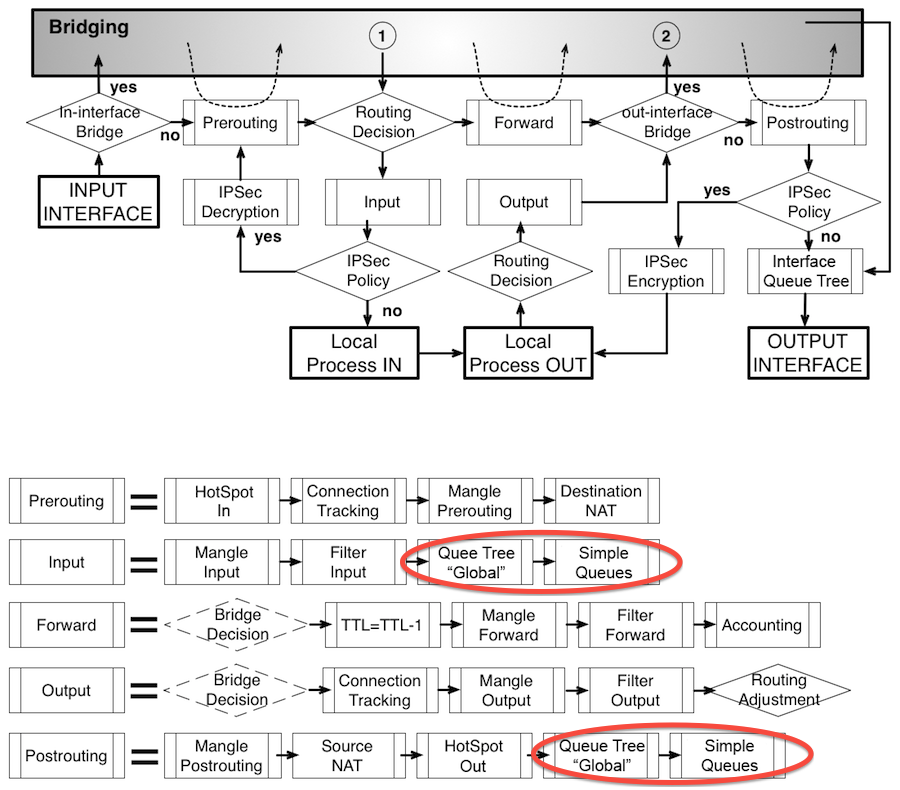
Я разбил правила на группы, для облегчения их понимания. В первой группе 6 правил, которые отвечают за трафик в/из самого роутера, и во второй группе 6, для транзитного трафика.
Начем с первых двух. В первом мы сообщаем роутеру, что все входящие chain=input соединения на интерфейс ISP1 нужно маркировать action=mark-connection new-connection-mark=ISP1-conn, а так же указаваем passthrough=yes, чтобы пакет, после прохождения этого правила, не покинул таблицу и продолжил следование по правилам.
Во втором говорим MikroTik’у, чтобы он отловил исходящие соединения chain=output помеченные как ISP1-conn и присвоил им метку роутинга(для помещения в соответствующую таблицу маршрутизации, вы ведь помните первые три маршрута?), а также сообщаем passthrough=no , как бы говоря — нечего делать здесь пакету после этого правила, т.е. пакет покинет таблицу.
Все описанное выше справедливо и для ISP2 и для ISP3. Таким образом мы добились того, что роутер ответит именно с того интерфейса, на который к нему прийдет запрос.
Переходим к завершающим шести правилам. Уже понятно, они также разбиты на подгруппы по 2, для каждого из наших ISP. Первое из них поручает роутеру следить за цепочкой FORWARD и если происходит соединение через интерфейс ISP1, то оно маркируется action=mark-connection новым тегом new-connection-mark=ISP1-conn-f (обратите внимание! отличным от тега трафика самого маршрутизатора, в данном случае мы маркируем транзитный трафик). passthrough=no, т.к. мы не хотим, чтобы пакет, после попадания в это правило, обрабатывался в таблице как-то еще.
Второе навешивает нужную метку роутинга new-routing-mark=ISP1-route в цепочке PREROUTING, т.е. ДО принятия решения о маршрутизации, и отслеживает трафик пришедший к нам из локальной сети in-interface=bridge.
Здесь нас выручает механизм CONNECTION TRACKING, позволяющий поймать промаркированные правилом выше соединения из локальной сети(от WEB-сервера) и навесить им необходимый тег роутинга.
Это позволяет транзитному трафику(здесь к/от web-сервера) идти именно тем путем, которым он и пришел, т.е. пришел через ISP1 — уходи через него же.
Manual:IP/Route
Router keeps routing information in several separate spaces:
- FIB (Forwarding Information Base), that is used to make packet forwarding decisions. It contains a copy of the necessary routing information.
- Each routing protocol (except BGP) has it’s own internal tables. This is where per-protocol routing decisions are made. BGP does not have internal routing tables and stores complete routing information from all peers in the RIB.
- RIB contains routes grouped in separate routing tables based on their value of routing-mark. All routes without routing-mark are kept in the main routing table. These tables are used for best route selection. The main table is also used for nexthop lookup.
Routing Information Base
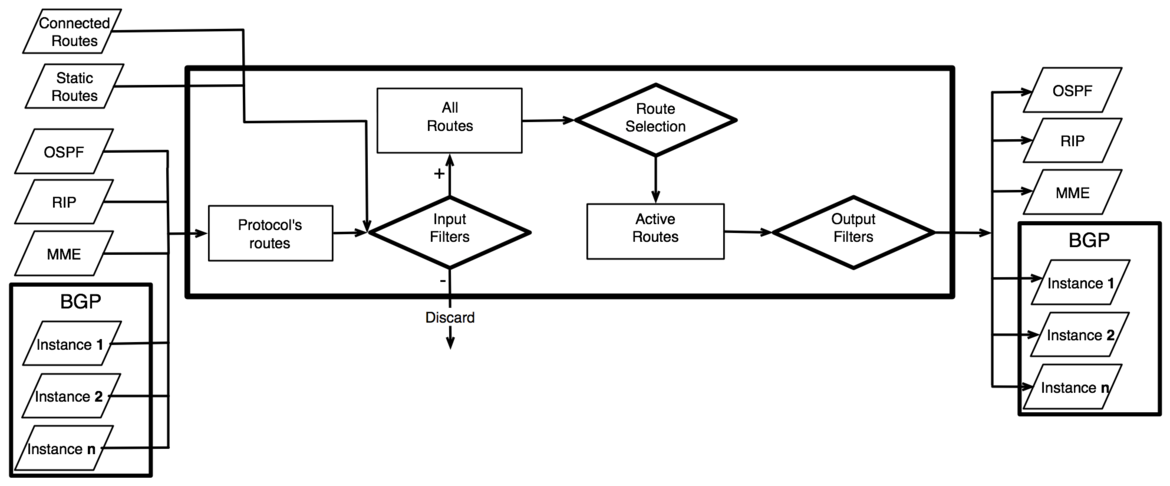
RIB (Routing Information Base) contains complete routing information, including static routes and policy routing rules configured by the user, routing information learned from routing protocols, information about connected networks. RIB is used to filter routing information, calculate best route for each destination prefix, build and update Forwarding Information Base and to distribute routes between different routing protocols.
By default forwarding decision is based only on the value of destination address. Each route has dst-address property, that specifies all destination addresses this route can be used for. If there are several routes that apply to a particular IP address, the most specific one (with largest netmask) is used. This operation (finding the most specific route that matches given address) is called routing table lookup.
If routing table contains several routes with the same dst-address, only one of them can be used to forward packets. This route is installed into FIB and marked as active.
When forwarding decision uses additional information, such as a source address of the packet, it is called policy routing. Policy routing is implemented as a list of policy routing rules, that select different routing table based on destination address, source address, source interface, and routing mark (can be changed by firewall mangle rules) of the packet.
All routes by default are kept in the main routing table. Routes can be assigned to specific routing table by setting their routing-mark property to the name of another routing table. Routing tables are referenced by their name, and are created automatically when they are referenced in the configuration.
Each routing table can have only one active route for each value of dst-address IP prefix.
There are different groups of routes, based on their origin and properties.
Default route
Route with dst-address 0.0.0.0/0 applies to every destination address. Such route is called the default route. If routing table contains an active default route, then routing table lookup in this table will never fail.
Connected routes

Connected routes are created automatically for each IP network that has at least one enabled interface attached to it (as specifie in the /ip address configuration). RIB tracks status of connected routes, but does not modify them. For each connected route there is one ip address item such that:
- address part of dst-address of connected route is equal to network of ip address item.
- netmask part of dst-address of connected route is equal to netmask part of address of ip address item.
- pref-src of connected route is equal to address part of address of ip address item.
- interface of connected route is equal to actual-interface of ip address item (same as interface, except for bridge interface ports).
Multipath (ECMP) routes
Because results of the forwarding decision are cached, packets with the same source address, destination address, source interface, routing mark and ToS are sent to the same gateway. This means that ECMP route does not perform pure per-connection balancing, but it can be used to load balance connections if at least one of previously mentioned parameters is different than previous connection. See interface bonding if you need to achieve per-packet load balancing.
To implement some setups, such as load balancing, it might be necessary to use more than one path to given destination. However, it is not possible to have more than one active route to destination in a single routing table.
ECMP (Equal cost multi-path) routes have multiple gateway nexthop values. All reachable nexthops are copied to FIB and used in forwarding packets.
OSPF protocol can create ECMP routes. Such routes can also be created manually.
Routes with interface as a gateway
Value of gateway can be specified as an interface name instead of the nexthop IP address. Such route has following special properties:
- Unlike connected routes, routes with interface nexthops are not used for nexthop lookup.
- It is possible to assign several interfaces as a value of gateway, and create ECMP route. It is not possible to have connected route with multiple gateway values.
Route selection
Each routing table can have one active route for each destination prefix. This route is installed into FIB. Active route is selected from all candidate routes with the same dst-address and routing-mark, that meet the criteria for becoming an active route. There can be multiple such routes from different routing protocols and from static configuration. Candidate route with the lowest distance becomes an active route. If there is more than one candidate route with the same distance, selection of active route is arbitrary (except for BGP routes).
BGP has the most complicated selection process (described in separate article). Notice that this protocol-internal selection is done only after BGP routes are installed in the main routing table; this means there can be one candidate route from each BGP peer. Also note that BGP routes from different BGP instances are compared by their distance, just like other routes.
Criteria for selecting candidate routes
To participate in route selection process, route has to meet following criteria:
- route is not disabled.
- distance is not 255. Routes that are rejected by route filter have distance value of 255.
- pref-src is either not set or is a valid local address of the router.
- routing-mark is either not set or is referred by firewall or policy routing rules.
- If type of route is unicast and it is not a connected route, it must have at least one reachable nexthop.
Nexthop lookup

Nexthop lookup is a part of the route selection process.
Routes that are installed in the FIB need to have interface associated with each gateway address. Gateway address (nexthop) has to be directly reachable via this interface. Interface that should be used to send out packets to each gateway address is found by doing nexthop lookup.
Some routes (e.g. iBGP) may have gateway address that is several hops away from this router. To install such routes in the FIB, it is necessary to find the address of the directly reachable gateway (an immediate nexthop), that should be used to reach the gateway address of this route. Immediate nextop addresses are also found by doing nexthop lookup.
Nexthop lookup is done only in the main routing table, even for routes with different value of routing-mark. It is necessary to restrict set of routes that can be used to look up immediate nexthops. Nexthop values of RIP or OSPF routes, for example, are supposed to be directly reachable and should be looked up only using connected routes. This is achieved using scope and target-scope properties.
- Routes with interface name as the value of gateway are not used for nexthop lookup. If route has both interface nexthops and active IP address nexthops, then interface nexthops are ignored.
- Routes with scope greater than the maximum accepted value are not used for nexthop lookup. Each route specifies maximum accepted scope value for it’s nexthops in the target-scope property. Default value of this property allows nexthop lookup only through connected routes, with the exception of iBGP routes that have larger default value and can lookup nexthop also through IGP and static routes.

Recursive nexthop lookup example
- nexthop 10.2.0.1 is resolved through a connected route, it’s status is reachable.
- nexthop 10.3.0.1 is resolved recursively through a 10.3.0.0/16 route, it’s status is recursive, and it uses 10.2.0.1 as the immediate nexthop value that is installed in the FIB.
Interface and immediate nexthop are selected based on the result of nexthop lookup:
- If most specific active route that nexthop lookup finds is connected route, then interface of this connected route is used as the nexthop interface, and this gateway is marked as reachable. Since gateway is directly reachable through this interface (that’s exactly what connected route means), the gateway address is used as the immediate nexthop address.
- If most specific active route that nexthop lookup finds has nexthop that is already resolved, immediate nexthop address and interface is copied from that nexthop and this gateway is marked as recursive.
- If most specific active route that nexthop lookup finds is ECMP route, then it uses first gateway of that route that is not unreachable.
- If nexthop lookup does not find any route, then this gateway is marked as unreachable.
Forwarding Information Base

FIB (Forwarding Information Base) contains copy of information that is necessary for packet forwarding:
- all active routes
- policy routing rules
By default (when no routing-mark values are used) all active routes are in the main table, and there is only one hidden implicit rule («catch all» rule) that uses the main table for all destination lookups.
Routing table lookup
FIB uses following information from packet to determine it’s destination:
- source address
- destination address
- source interface
- routing mark
- ToS (not used by RouterOS in policy routing rules, but it is a part of routing cache lookup key)
Possible routing decisions are:
- receive packet locally
- discard packet (either silently or by sending ICMP message to the sender of the packet)
- send packet to specific IP address on specific interface
Results of routing decision are remembered in the routing cache. This is done to improve forwarding performance. When another packet with the same source address, destination address, source interface, routing mark and ToS is routed, cached results are used. This also allows to implement load balancing using ECMP routes, because values used to lookup entry in the routing cache are the same for all packets that belong to the same connection and go in the same direction.
If there is no routing cache entry for this packet, it is created by running routing decision:
- check that packet has to be locally delivered (destination address is address of the router)
- process implicit policy routing rules
- process policy routing rules added by user
- process implicit catch-all rule that looks up destination in the main routing table
- return result is «network unreachable»
Result of routing decision can be:
- IP address of nexthop + interface
- point-to-point interface
- local delivery
- discard
- ICMP prohibited
- ICMP host unreachable
- ICMP network unreachable
Rules that do not match current packet are ignored. If rule has action drop or unreachable, then it is returned as a result of the routing decision process. If action is lookup then destination address of the packet is looked up in routing table that is specified in the rule. If lookup fails (there is no route that matches destination address of packet), then FIB proceeds to the next rule. Otherwise:
- if type of the route is blackhole, prohibit or unreachable, then return this action as the routing decision result;
- if this is a connected route, or route with an interface as the gateway value, then return this interface and the destination address of the packet as the routing decision result;
- if this route has IP address as the value of gateway, then return this address and associated interface as the routing decision result;
- if this route has multiple values of nexthop, then pick one of them in round robin fashion.
Result of this routing decision is stored in new routing cache entry.
Properties
Route flags
| Property(Flag) | Description |
|---|---|
| disabled (X) | Configuration item is disabled. It does not have any effect on other routes and is not used by forwarding or routing protocols in any way. |
| active (A) | Route is used for packet forwarding. See route selection. |
| dynamic (D) | Configuration item created by software, not by management interface. It is not exported, and cannot be directly modified. |
| connect (C) | connected route. |
| static (S) | static route. |
| rip (r) | RIP route. |
| bgp (b) | BGP route. |
| ospf (o) | OSPF route. |
| mme (m) | MME route. |
| blackhole (B) | Silently discard packet forwarded by this route. |
| unreachable (U) | Discard packet forwarded by this route. Notify sender with ICMP host unreachable (type 3 code 1) message. |
| prohibit (P) | Discard packet forwarded by this route. Notify sender with ICMP communication administratively prohibited (type 3 code 13) message. |
General properties
- connected routes: 0
- static routes: 1
- eBGP: 20
- OSPF: 110
- RIP: 120
- MME: 130
- iBGP: 200
- connected routes: 10 (if interface is running)
- OSPF, RIP, MME routes: 20
- static routes: 30
- BGP routes: 40
- connected routes: 200 (if interface is not running)
Other Read-only properties
| Property | Description |
|---|---|
| gateway-status (array) | Array of gateways, gateway states and which interface is used for forwarding. Syntax «IP state interface», for example «10.5.101.1 reachable bypass-bridge». State can be unreachable, reachable or recursive. See nexthop lookup for details. |
| ospf-metric (integer) | Used OSPF metric for particular route |
| ospf-type (string) |
BGP Route Properties
These properties contain information that is used by BGP routing protocol. However, values of these properties can be set for any type of route, including static and connected. It can be done either manually (for static routes) or using route filters.
- internet — advertise this route to the Internet community (i.e. all routers)
- no-advertise — do not advertise this route to any peers
- no-export — do not advertise this route to EBGP peers
- local-as — same as no-export, except that route is also advertised to EBGP peers inside local confederation
| Property | Description |
|---|---|
| bgp-ext-communities (string) | Value of BGP extended communities attribute |
| bgp-weight (integer) | Additional value used by BGP best path selection algorithm. Routes with higher weight are preferred. It can be set by incoming routing filters and is useful only for BGP routes. If value is not set then it is interpreted as 0. |
| received-from (string) | Name of the BGP peer from which route is received. |
Записки IT специалиста
Резервирование каналов в Mikrotik при помощи рекурсивной маршрутизации
- Автор: Уваров А.С.
- 09.04.2020
Значение интернета в повседневной жизни и деятельности предприятий всех форм и размеров с каждым днем только растет, особенно сейчас, когда весь мир переходит на дистанционные методы работы в связи с пандемией короновируса. Но этот вопрос актуален также и для торговых предприятий, платежные карты используются практически каждым вторым покупателем и отсутствие интернета мгновенно скажется на выручке предприятия. В данной статье мы рассмотрим, каким образом можно организовать резервный канал и обеспечить быстрое переключение на него и обратно штатными средствами RouterOS.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Как показывает читательский отклик, маршрутизация для многих администраторов является достаточно сложной темой. Тем не менее если вы внимательно выполните все инструкции данной статьи, то всё будет работать. Однако слепое выполнение инструкций не добавляет понимания происходящих процессов и, если что-то пойдет не так вы окажетесь в весьма затруднительном положении, поэтому перед тем, как перейти к практике мы выполним небольшой теоретический ликбез.
Теория
Действительно, маршрутизация достаточно сложная тема, поэтому мы сознательно упростили многие моменты для того, чтобы обеспечить понимание процессов начинающими в объеме необходимом для решения поставленной задачи.
Что такое маршрутизация? Это процесс определения пути следования данных в сетях связи. Его можно сравнить с прокладкой маршрута с использованием навигатора, вы задаете начальную и конечную точку и получаете несколько вариантов проезда с указанием всех промежуточных точек. В некоторых точках маршрут может разделяться на несколько вариантов, из которых вы можете выбрать наиболее оптимальный, исходя из оценки текущей дорожной обстановки.
Для каждого узла маршрута, а наш роутер является одним из них, решение о маршрутизации принимается на основании таблицы маршрутизации. Рассмотрим ее простейший вариант, за основу мы взяли стандартный вывод в терминале Mikrotik и добавили дополнительные данные, сейчас они могут быть непонятны, но ниже мы будем к ним обращаться.
Flags: X - disabled, A - active, D - dynamic, C - connect, S - static
# DST-ADDRESS PREF-SRC GATEWAY DISTANCE SCOPE TARGET SCOPE
0 DAS 0.0.0.0/0 192.168.3.1 1 30 10
1 DAC 192.168.3.0/24 192.168.3.113 ether5 0 10 10
2 DAC 192.168.186.0/24 192.168.186.1 bridge1 0 10 10Прежде всего разберемся как заполняется таблица маршрутизации. Это может происходить несколькими способами:
- Непосредственно присоединенные сети — в данном случае они имеют флаг С — connect — это сети к которым физически подключен маршрутизатор, они добавляются при подключении интерфейса и удаляются при его отключении.
- Статические маршруты — добавляются системным администратором, либо динамически, при подключении коммутируемого соединения или получения сетевых параметров по DHCP. В этом случае к флагу S -static, добавляется флаг D — dynamic.
- Динамические маршруты — маршруты добавляемые при помощи протоколов динамической маршрутизации, таких как OSPF, RIP и т.д. Не следует путать их с динамически добавляемыми статическими маршрутами и маршрутами непосредственно присоединенных сетей. Флаг D — dynamic в Mikroitk обозначает только то, что маршрут добавлен автоматически, без участия пользователя. А динамические маршруты обозначаются флагами r — rip, b — bgp, o — ospf, m — mme, однако их рассмотрение выходит за рамки данной статьи.
К одной цели могут вести несколько маршрутов, приоритетом их выбора является значение административной дистанции, чем ниже это значение, тем выше приоритет у маршрута. Если вернуться к нашей аналогии с навигатором, то он может проложить нам несколько маршрутов, но приоритет получит самый короткий. Но если на этом маршруте возникнут серьезные затруднения, скажем, пробка или авария, то мы можем выбрать более длинный маршрут. Также и здесь, если маршрут с наименьшей административной дистанцией недоступен, то выбирается маршрут с более высокой дистанцией.
Теперь разберемся как все это работает. Допустим мы хотим обратиться к узлу 8.8.8.8, роутер берет таблицу маршрутизации и осуществляет в ней поиск наилучшего маршрута к запрашиваемому узлу. В нашем случае искать особо нечего и это будет «нулевой» маршрут со шлюзом 192.168.3.1. Но маршрутизаторы крупных сетевых узлов могут содержать тысячи и десятки тысяч маршрутов и поэтому поиск может оказаться совсем не простым и дешевым действием.
Коротко напомним о том, что такое «нулевой» маршрут или шлюз по умолчанию, он используется в том случае, если в таблице для узла назначения не было найдено ни одного подходящего маршрута. Проще говоря, если роутер не знает куда отправить данные, он отправляет их шлюзу по умолчанию. Особой записи для узла 8.8.8.8 в нашей таблице нет, поэтому будет использоваться «нулевой» маршрут.
Хорошо, адрес шлюза мы определили, но это не решило основной задачи — куда отправить данные. Почему? Вернемся к нашей аналогии, вы решили поехать из Белгорода в Москву, карта показывает, что сначала вам нужно приехать в Курск. Отлично, но как именно в него попасть? Навигатор услужливо подскажет нам, что требуется ехать на север по федеральной трассе М2 «Крым».
В нашем случае основной задачей маршрутизатора будет определить интерфейс выхода, т.е. куда именно физически нужно направить данные, чтобы они добрались до требуемого места назначения. Поэтому роутер снова начинает поиск в таблице маршрутизации чтобы определить каким образом следует добраться до искомого адреса шлюза 192.168.3.1, согласно таблице, будет найден маршрут к сети 192.168.3.0/24 через интерфейс ether5. Так как интерфейс выхода определен, то поиск прекращается и роутер формирует необходимый тип данных для передачи на канальном уровне.
Здесь тоже следует дать краткие пояснения, если интерфейс выхода является сетью Ethernet, то роутер выполнит ARP-запрос для адреса шлюза и сформирует Ethernet-кадр, а если это туннельный интерфейс точка-точка (VPN, PPPoE), то выполнит инкапсуляцию IP-пакета и отправит его на другую сторону туннеля.
И здесь мы приходим к следующим соображениям: таблица маршрутизации может быть большая и поиск по ней может быть затратным, в тоже время шлюз будет располагаться в одной из непосредственно присоединенных сетей, возможно следует ограничить поиск только по ним?
Для решения этой проблемы в Linux, а следовательно, и в RouterOS, введены понятия области маршрута — Scope, и области поиска — Target-scope. Теперь вернемся к нашей таблице маршрутизации, «нулевой» маршрут имеет область — 30 и область поиска — 10. Следовательно дальнейший поиск будет вестись только среди маршрутов с областью 10.
По умолчанию данные опции имеют следующее значение:
- Непосредственно присоединенные сети: Scope — 10, Target Scope не имеет смысла, так как данный маршрут указывает на интерфейс выхода
- Динамические маршруты — OSPF, RIP, MME: Scope — 20, Target Scope — 10
- Статические маршруты: Scope — 30, Target Scope — 10
Таким образом область поиска существенно снижается и маршрут к шлюзу ищется только среди непосредственно присоединенных сетей. Теперь самое время перейти к рекурсивной маршрутизации.
Mikrotik имеет возможность проверять доступность шлюза, используя для этого пинг, если шлюз оказывается недоступным, то маршрут становится неактивным. Это хорошо, но позволяет выявлять только проблемы в сети провайдера, и если шлюз остается доступным, то маршрут будет продолжать оставаться активным, несмотря на остуствие доступа в интернет. Но что, если указать в качестве шлюза удаленный высокодоступный узел?
Давайте рассмотрим следующую таблицу маршрутизации:
Flags: X - disabled, A - active, D - dynamic, C - connect, S - static
# DST-ADDRESS PREF-SRC GATEWAY DISTANCE SCOPE TARGET SCOPE
0 AS 0.0.0.0/0 1.1.1.1 1 30 10
1 AS 1.1.1.1/32 192.168.3.1 1 10 10
2 DAC 192.168.3.0/24 192.168.3.113 ether5 0 10 10
3 DAC 192.168.186.0/24 192.168.186.1 bridge1 0 10 10В качестве шлюза по умолчанию мы указали адрес одного из DNS-серверов Cloudflare, обратите внимание, что такой адрес не должен использоваться в вашей сети, потому что после отказа связанного с ним провайдера он окажется недоступен. Теперь мы можем проверять наличие интернета за пределами сети провайдера и своевременно переключать маршруты в случае его недоступности.
Теперь разберемся как это работает. Когда мы хотим связаться с каким-либо узлом в сети интернет маршрутизатор выполнит поиск по таблице маршрутизации и, если не указано иных маршрутов, выберет «нулевой» в котором указан шлюзом 1.1.1.1, так как найден адрес, то поиск будет продолжен, чтобы определить интерфейс выхода. Так как указанный нами шлюз не находится ни в одной из непосредственно присоединенных сетей, то сделать это не удастся и такой маршрут работать не будет.
Поэтому мы «подскажем» маршрутизатору как достичь указанного нами узла и добавим маршрут к 1.1.1.1 через сеть провайдера, а чтобы он участвовал в поиске его область должна быть меньше или равна области поиска «нулевого» маршрута, т.е. 10. Это очень важный момент, если вы неправильно укажете область второго маршрута — рекурсивная маршрутизация работать не будет.
Итак, роутер находит адрес первого шлюза — 1.1.1.1 и начинает искать маршрут к нему с среди маршрутов с областью 10, там он находит второй маршрут и получает из него новое значение шлюза — 192.168.3.1 — который является шлюзом нашего провайдера, затем еще раз выполняет поиск и находит связанный с ним интерфейс выхода — ether5. После чего пакет отправляется провайдеру, а удаленный узел 1.1.1.1 используется нами только как способ проверки наличия интернета через данный канал. Это и есть рекурсивная маршрутизация.
Практика
Будем считать что на вашем роутере уже настроен доступ к двум провайдерам и мы не будем останавливаться на этапе базовой настройки, если вы испытываете затруднения с этим, то обратитесь к нашей статье: Базовая настройка роутера MikroTik.
В нашем примере будут использоваться два условных провайдера, основной и резервный, подключенные к интерфейсам ether5 и ether4, тип интерфейса и подключения в данном случае никакой роли не играют. Откроем таблицу маршрутизации IP — Routes, в простейшем виде она будет выглядеть приблизительно так:
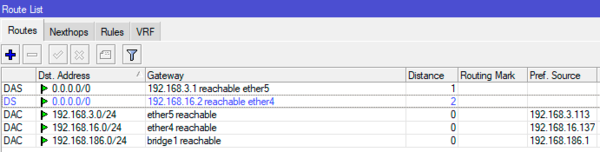
У нас есть два нулевых маршрута с разными административными дистанциями (1 для основного провайдера, 2 для резервного) и три маршрута для непосредственно присоединенных сетей, где 192.168.3.0/24 — сеть основного провайдера, а 192.168.16.0/24 — резервного.
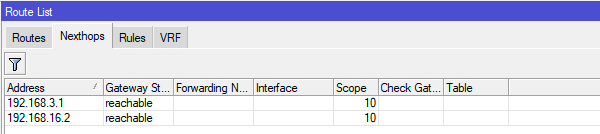
Перед тем, как переходить к дальнейшим настройкам нам нужно выяснить и запомнить адреса шлюзов провайдеров, для этого можно заглянуть на закладку Nexthops, для коммутируемых подключений (VPN, PPPoE) следует проверить свойства соответствующего соединения.
Внимание! Дальнейшие действия следует производить имея физический доступ к устройству!
Прежде всего отключим автоматическое создание нулевых маршрутов для сетей провайдеров, для этого следует снять флаг Add Default Route в свойствах подключения, либо установить одноименную опцию в значение — no.
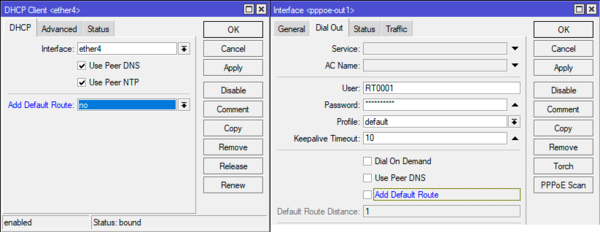
После этого доступ в интернет по обоим каналам пропадет. Имейте это ввиду при планировании работ.
Теперь начнем добавлять собственные маршруты, но сначала выберем два высокодоступных узла для первого и второго провайдера. Допустим это будут 1.1.1.1 (Cloudflare DNS) и 9.9.9.9 (Quad9 DNS). Каких-либо ограничений по их выбору нет, это могут быть как ваши собственные, так и публичные узлы, единственное условие — они не должны использоваться в вашей сети, потому как при отказе одного из провайдеров окажутся недоступными.
В первую очередь создадим маршруты к этим узлам. Для этого снова перейдем в IP — Routes и создадим новый маршрут:
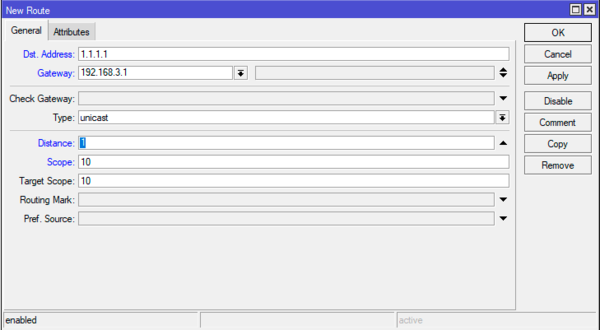
Где Dst. Address — 1.1.1.1 — узел для проверки первого провайдера, Gateway — 192.168.3.1 — шлюз первого провайдера, Distance — 1, Scope — 10. Обратите внимание на значение области (Scope), если вы оставите там значение по умолчанию — 30, то рекурсивная маршрутизация работать не будет! Затем добавим второй аналогичный маршрут, но уже к узлу 9.9.9.9 через шлюз второго провайдера.
Эти же действия через терминал:
/ip route
add distance=1 dst-address=1.1.1.1/32 gateway=192.168.3.1 scope=10
add distance=1 dst-address=9.9.9.9/32 gateway=192.168.16.2 scope=10Затем добавим два рекурсивных «нулевых» маршрута. Для первого провайдера:
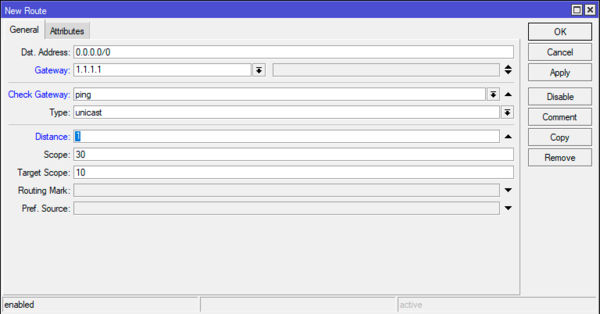
Dst. Address оставляем по умолчанию — 0.0.0.0/0, Gateway — 1.1.1.1 — высокодоступный узел для первого провайдера, Check Gateway — ping — указываем проверку доступности шлюза, Distance — 1.
Для второго провайдера:
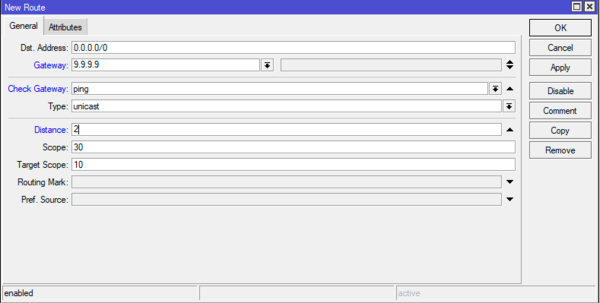
Dst. Address — 0.0.0.0/0, Gateway — 9.9.9.9, Check Gateway — ping , Distance — 2. Обратите внимание на значение административной дистанции второго маршрута, она должна быть больше, чем у основного провайдера, в нашем случае — 2.
То же самое быстро в терминале:
/ip route
add check-gateway=ping distance=1 gateway=1.1.1.1
add check-gateway=ping distance=2 gateway=9.9.9.9Теперь таблица маршрутизации будет выглядеть следующим образом:
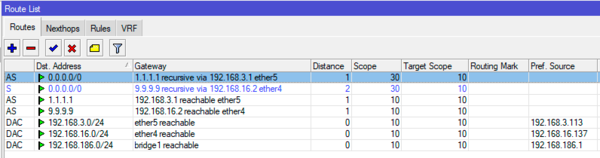
Наши маршруты добавились как рекурсивные и активным является маршрут через основного провайдера. Теперь имитируем аварию у первого провайдера, буквально через 10-20 секунд таблица маршрутизации изменится и рабочим станет маршрут через резервный канал:
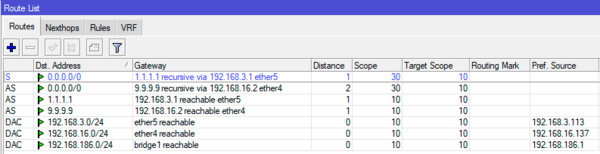
После того, как первый провайдер устранит неисправность снова произойдет изменение маршрутов и рабочим снова станет основной канал.
Как видим на практике все оказалось достаточно просто, но мы уверены, что слепое повторение инструкций без понимания сути производимых действий никого и никогда ни к чему хорошему не приводило, поэтому настоятельно советуем не пренебрегать теоретической частью материала.
Рекурсивная маршрутизация и PPPoE
При использовании PPPoE подключения вы рано или поздно столкнетесь с проблемой изменения адреса шлюза провайдера, это может произойти даже при наличии выделенного IP адреса. После чего маршрут к высокодоступному узлу перестает работать, что приводит к полной неработоспособности этого провайдера. Диагностика такой неисправности может оказаться весьма затруднительной если вы не сталкивались с данной проблемой ранее и недостаточно четко представляете себе принципы работы рекурсивных маршрутов.
Чтобы этого избежать используем одну небольшую хитрость. Вспомним, о чем мы говорили в теоретической части. При использовании PPPoE соединения адрес шлюза провайдера роутеру как таковой не нужен. Он используется только для определения интерфейса выхода. Для работы протокола PPP, который лежит в основе PPPoE, IP-адреса не требуются. Это дает возможность самостоятельно присвоить произвольный адрес для удаленного конца туннеля и использовать его в качестве шлюза.
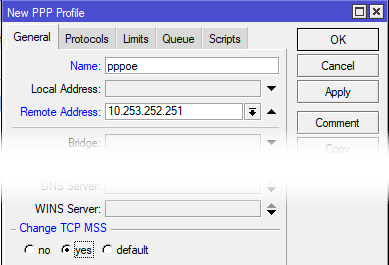
Для этого перейдем в PPP — Profiles и создадим новый профиль, укажем для него понятное имя и зададим параметр — Remote Address, адрес можно указать любой, единственное условие — он не должен пересекаться с вашими внутренними сетями, в нашем случае это 10.253.252.251. Также установите переключатель Change TCP MSS в положение yes.
В терминале это можно сделать так:
/ppp profile
add change-tcp-mss=yes name=pppoe-rt remote-address=10.253.252.251После чего назначим этот профиль вашему PPPoE соединению:

И после его перезапуска убедимся, что удаленный адрес соединения теперь соответствует назначенному нами:
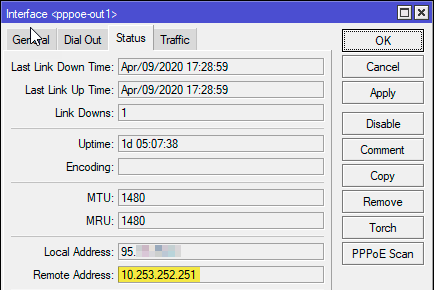
Теперь можно использовать данный адрес как шлюз для этого провайдера, не беспокоясь о возможных изменениях.
Рекурсивная маршрутизация и DHCP
Описанная выше проблема актуальна и для провайдеров, выдающих настройки по DHCР, в том случае если у клиента нет выделенного IP-адреса, текущий адрес может быть назначен из нескольких диапазонов, а следовательно, будет изменен и адрес шлюза. В отличие от PPPoE здесь мы не сможем задать произвольный адрес, поэтому нам на выручку придут скрипты.
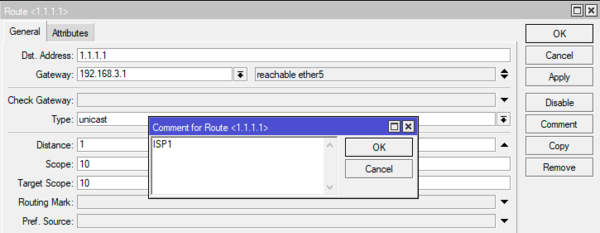
Прежде всего добавим к маршруту для высокодоступного узла через шлюз провайдера уникальный комментарий, например, ISP1.
Затем перейдем в настройки DHCP-клиента — IP — DHCP Client — и на закладке Advanced внесем в соответствующее поле короткий скрипт:
/ip route set [find comment="ISP1"] gateway=($"gateway-address") disabled=no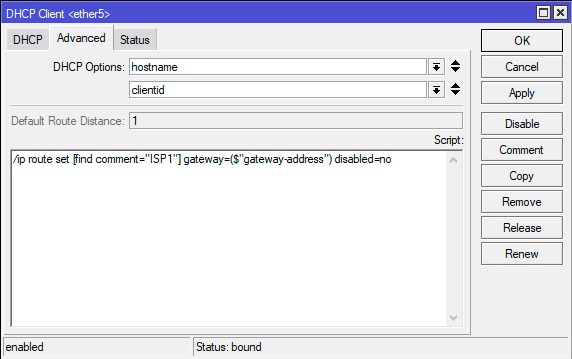
Теперь при каждом новом получении адреса по DHCP скрипт будет находить наш маршрут и изменять в нем значение шлюза на реально полученный адрес. Попробуем смоделировать данную ситуацию и выдадим нашему роутеру адрес первого провайдера из другого диапазона. Как видим, все автоматически изменилось согласно вновь полученных настроек:
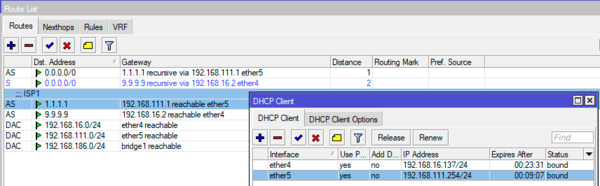
Таким образом мы снова успешно решили задачу поддержания маршрутной информации в актуальном состоянии несмотря на ее возможные изменения со стороны провайдера.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Дополнительные материалы:
Mikrotik
- Оборудование MikroTik класса SOHO. Общий обзор и сравнение возможностей
- Производительность младших моделей Mikrotik hEX и hAP. Экспресс-тестирование
- Базовая настройка роутера MikroTik
- Расширенная настройка DNS и DHCP в роутерах Mikrotik
- Автоматическое резервное копирование настроек Mikrotik на FTP
- Проброс портов и Hairpin NAT в роутерах Mikrotik
- Настройка IPTV в роутерах Mikrotik на примере Ростелеком
- Настройка VPN-подключения в роутерах Mikrotik
- Настройка черного и белого списков в роутерах Mikrotik
- Настройка выборочного доступа к сайтам через VPN на роутерах Mikrotik
- Настройка OpenVPN-сервера на роутерах Mikrotik
- Безопасный режим в Mikrotik или как всегда оставаться на связи
- Настройка Proxy ARP для VPN-подключений на роутерах Mikrotik
- Настраиваем Port Knocking в Mikrotik
- Резервирование каналов в Mikrotik при помощи рекурсивной маршрутизации
- Настраиваем родительский контроль на роутерах Mikrotik
- Настраиваем IKEv2 VPN-сервер на роутерах Mikrotik с аутентификацией по сертификатам
- Расширенная настройка Wi-Fi на роутерах Mikrotik. Режим точки доступа
- Mikrotik CHR — виртуальный облачный роутер
- Настройка контроллера CAPsMAN (бесшовный Wi-Fi роуминг) на Mikrotik
- Настройка VPN-подключения на роутерах Mikrotik если подсети клиента и офиса совпадают
- Настраиваем использование DNS over HTTPS (DoH) на роутерах Mikrotik
- Настройка PPTP или L2TP VPN-сервера на роутерах Mikrotik
- Установка Mikrotik CHR на виртуальную машину Proxmox
- Защита RDP от перебора паролей при помощи оборудования Mikrotik
- Настройка SSTP VPN-сервера на роутерах Mikrotik
- Настройка выборочного доступа к сайтам через VPN с автоматическим получением маршрутов по BGP на роутерах Mikrotik
- Особенности эксплуатации CA на роутерах Mikrotik: резервное копирование, экспорт и импорт сертификатов
- Настройка туннелей GRE и IPIP на роутерах Mikrotik
- Правильное использование Fast Path и FastTrack в Mikrotik
- DHCP Snooping — настройка защиты от неавторизованных DHCP-серверов на оборудовании Mikrotik
- Работа оборудования Mikrotik в режиме беспроводной станции (клиента)
- Используем режим ARP reply-only для повышения безопасности сети на оборудовании Mikrotik
The Dude
- The Dude. Установка и быстрое начало работы
- Централизованное управление обновлением RouterOS при помощи The Dude
- Централизованный сбор логов Mikrotik на сервер The Dude
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
![]()
Или подпишись на наш Телеграм-канал: