Scrape
Scrape — дополнительный протокол запроса клиента к трекеру, при котором трекер сообщает клиенту общее количество сидов и пиров на раздаче.
В отличие от announce, запрос scrape:
- не имеет прямого отношения к скачиванию раздачи
- является необязательным
- может запрашиваться и для остановленных в клиенте заданий
- отнимает меньше ресурсов у клиента и трекера
- может одним запросом получить информацию сразу по нескольким торрентам (multi-scrape)
Клиент с помощью scrape может показать пользователю точные количества сидов и пиров на каждом задании, включая остановленные.
Некоторые клиенты, например Azureus, также могут с помощью scrape:
- раньше узнать о том, что на раздаче появились дополнительные участники, и сделать внеочередной announce для получения их адресов
- автоматически останавливать и запускать сидирование заданий в зависимости от числа сидов и пиров, в результате сидируя там, где это нужнее
Ссылки
- Scrape на AzureusWiki (англ.)
Персоны: Брэм Коэн • Ashwin Navin • Компании: BitTorrent, Inc. • Vuze, Inc.
Суперсид • Обмен пирами (Peer exchange, PEX) • Распределённая хеш-таблица (DHT) • Broadcatching • Protocol encryption • DNA • Мультитрекер • Ретрекер • announce • scrape
IPB (IPBTT) • phpBB2 (TorrentPier • TorrentPier II) • phpBB3 (ppkBB3cker • xbtBB3cker) • SMF (SMF Torrent • Simple Tracker) • TBDev (CyBERhype Tracker • KinoKPK • LiteTracker • Tesla Torrent-Tracker) • Прочие (Xbtit • BTITeam Tracker • TorrentTrader • Torrent Hoster • vBulletin Torrent Tracker)
- BitTorrent
Wikimedia Foundation . 2010 .
Полезное
Смотреть что такое «Scrape» в других словарях:
- Scrape — may refer to:Medicine* Abrasion, a type of injuryTools* Bottle scraper, for removing content from bottles * Scraper (kitchen), a kitchen utensil * Card scraper, for smoothing wood or removing old finish * Hand scraper, for finishing a metal… … Wikipedia
- Scrape — (skr[=a]p), v. t. [imp. & p. p. ; p. pr. & vb. n. .] [Icel. skrapa; akin to Sw. skrapa, Dan. skrabe, D. schrapen, schrabben, G. schrappen, and prob. to E. sharp.] 1. To rub over the surface of (something) with a sharp or rough… … The Collaborative International Dictionary of English
- scrape — vb Scrape, scratch, grate, rasp, grind are comparable when they mean to apply friction to something by rubbing it with or against a thing that is harsh, rough, or sharp. Scrape usually implies the removal of something from a surface with an edged … New Dictionary of Synonyms
- scrape — ► VERB 1) drag or pull a hard or sharp implement across (a surface or object) to remove dirt or waste matter. 2) use a sharp or hard implement to remove (dirt or unwanted matter). 3) rub against a rough or hard surface. 4) just manage to achieve … English terms dictionary
- scrape in — ˌscrape ˈin [intransitive] [present tense I/you/we/they scrape in he/she/it scrapes in present participle scraping in past tense … Useful english dictionary
- Scrape — Scrape, n. 1. The act of scraping; also, the effect of scraping, as a scratch, or a harsh sound; as, a noisy scrape on the floor; a scrape of a pen. [1913 Webster] 2. A drawing back of the right foot when bowing; also, a bow made with that… … The Collaborative International Dictionary of English
- scrape — [skrāp] vt. scraped, scraping [ME scrapen < ON skrapa, akin to Du schrapen, OE screpan, to scratch < IE base * (s)ker , to cut > SCURF, SHARP] 1. to rub over the surface of with something rough or sharp 2. to make smooth or clean by… … English World dictionary
- scrape — [n] bad or embarrassing situation awkward situation, corner*, difficulty, dilemma, discomfiture, distress, embarrassment, fix*, hole*, jam*, mess*, pickle*, plight, predicament, tight spot*, trouble; concept 674 Ant. resolution, solution scrape… … New thesaurus
- Scrape — Scrape, v. i. 1. To rub over the surface of anything with something which roughens or removes it, or which smooths or cleans it; to rub harshly and noisily along. [1913 Webster] 2. To occupy one s self with getting laboriously; as, he scraped and … The Collaborative International Dictionary of English
- scrape — scrape; sky·scrape; … English syllables
- Обратная связь: Техподдержка, Реклама на сайте
- �� Путешествия
Экспорт словарей на сайты, сделанные на PHP,
WordPress, MODx.
- Пометить текст и поделитьсяИскать в этом же словареИскать синонимы
- Искать во всех словарях
- Искать в переводах
- Искать в ИнтернетеИскать в этой же категории
Что такое веб-скрейпинг и как он работает
Что такое web-scraping и зачем он нужен. Как он работает и чем отличается от парсинга. Насколько законно извлекать данные с сайта и как их применять. Какие сервисы лучше использовать для безопасного веб-скрейпинга: список проверенных инструментов.
Веб‑скрейпинг — технология, которая может быть полезной для SEO‑продвижения сайта.
Рассказываем, каким бывает веб‑скрейпинг, как он работает и как с его помощью получить полезные данные, а также какие инструменты использовать для скрейпинга и как защититься от его незаконной и вредной формы.
Что такое веб‑скрейпинг
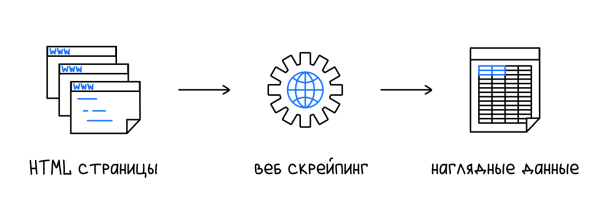
Веб‑скрейпинг (web scraping, буквально «выскребание, соскабливание веба») — автоматизированный процесс извлечения данных с сайта.
Когда мы находим на сайте какую‑то информацию и копируем её к себе в документ, то, по сути, занимаемся скрейпингом, но в очень маленьком объёме.
В рамках веб‑скрейпинга данные собираются автоматически в больших объёмах — с помощью ботов. Под ботом имеется в виду любая программа, собирающая данные с веб‑сайтов. Это может быть готовая программа, которую надо установить на компьютер, веб‑приложение или самописный сервис.
Боты‑скрейперы получают HTML‑код интересующих страниц сайта, разбирают его по определенным правилам, заданным для скрейпинга, и таким образом превращают любую нужную информацию с сайта в читаемый формат.
Чем скрейпинг отличается от парсинга данных
Скрейпинг и парсинг легко спутать, потому что эти понятия часто используют как взаимозаменяемые. Разобраться можно, если узнать дословный перевод слов to scrape и to parse.
Скрейпинг (от глагола to scrape — «соскребать, собирать») — автоматизированный сбор данных, как мы уже писали.
Парсинг (от глагола to parse — «разбирать») — процесс, на котором из скачанных данных извлекается нужная информация и превращается в нужный нам читаемый формат. Проще говоря, второй этап веб‑скрейпинга.
В статье мы не будем углубляться в термины, а расскажем о процессе полностью, называя его «веб‑скрейпинг».
Зачем нужен веб‑скрейпинг
У скрейпинга много сфер применения:
- Отслеживание цен на товары в интернет‑магазинах
Собирая информацию о ценах на разных платформах (сайтах, маркетплейсах), можно вовремя корректировать цены и обходить конкурентов.
- Извлечение описаний товаров и услуг
Это поможет улучшить свои описания товаров и услуг с опорой на тексты конкурентов.
- Мониторинг новостей и объявлений
Инструмент для отслеживания интересных тем и создания актуального контента.
- Сбор данных для аналитики
С помощью скрейпинга можно собрать лайки, репосты, комментарии в одну таблицу и оценить эффективность своего контента или даже провести маркетинговое исследование.
Вы наверняка видели подобные исследования в интернете:


Для них нужно довольно много данных — вручную такое не собрать. И здесь снова понадобится веб‑скрейпинг.
- Извлечение контактной информации
С помощью скрейпинга можно получить адреса электронной почты, телефоны, прочие контактные данные и свести в одну таблицу — она пригодится для ретаргетинга.
- Мониторинг репутации бренда
Скрейпинг также используется для отслеживания упоминаний о бренде/продукте, чтобы компания могла вовремя реагировать на изменение тональности упоминаний.
Какой бывает веб‑скрейпинг
Законность или незаконность той или иной формы сбора данных зависит от юрисдикции: то, что разрешено в одной стране, может быть запрещено в другой. Мы рассказываем о скрейпинге с точки зрения того, что мы и наши читатели — в России.
Условно скрейпинг делится на хороший и плохой.
Законный (хороший)
- Работа ботов поисковых систем. Они просматривают сайт, анализируют его контент и индексируют.
Этот вид скрейпинга нужен, чтобы сайт попал в результаты выдачи. Без этого пользователи не увидят наш сайт.
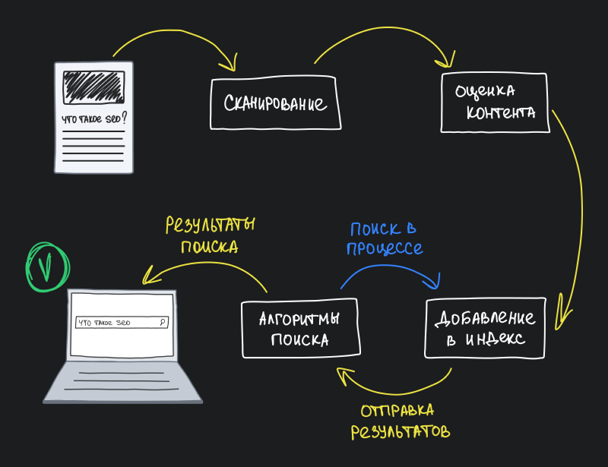
Подробно о ботах поисковых систем, процессах сканирования, фильтрации и индексации мы рассказываем во втором модуле нашего бесплатного курса по SEO.
- Сбор данных агрегаторов / сайтов сравнения цен. Они используют ботов для извлечения цен и описаний продуктов, создавая сравнения сайтов похожих продавцов.
В результате мы можем видеть информацию с разных сайтов в одном каталоге:

- Маркетинговые (и не только) исследования. При создании таких исследований компании задействуют ботов, которые извлекают сообщения из соцсетей и форумов и затем сводят их в один документ.
Пример такого исследования мы привели выше, в разделе «Зачем нужен веб‑скрейпинг».
Незаконный (плохой)
Формально парсинг и скрейпинг в России не запрещены. Но некоторые виды скрейпинга условно считаются плохими, и сайты стараются их пресекать:
Сайты активно защищаются от сбора данных о ценах: конкуренты часто скрейпят друг друга, снижая свои цены и вызывая таким образом ценовой демпинг.
Чаще всего такое происходит в отраслях, где товары можно легко и быстро сопоставить, а цена играет решающую роль при покупке. То есть это не дешёвые товары повседневного спроса, а то, что человек считает крупной покупкой: авиа‑ и ж/д‑билеты, туристические путёвки, электроника и бытовая техника.
От этой формы скрейпинга нужно активно защищаться, поскольку огромное количество созданного вручную контента можно легко вытащить с вашего сайта и скопировать на другой ресурс.
❗️Получается, что и боты, которые собирают данные с сайтов, условно делятся на «плохих» и «хороших». Есть пара признаков, по которым их можно узнать:
- «Хорошие» боты действуют согласно директивам из файла robots.txt. В этом файле веб‑мастер прописывает, как обходить конкретные страницы сайта — например, какие индексировать, какие нет. «Плохие» боты игнорируют robots.txt и ходят по всем страницам сайта.
- «Хороший» бот обычно ссылается на организацию, которая «послала» его исследовать страницы. Запись (referer), показывающая, к какой организации бот относится, обычно прописана в HTTP‑заголовке бота. «Плохие» боты имитируют естественный трафик, ничего не указывая, будто на сайт зашёл человек.
От «плохих» ботов сайты защищаются с помощью различных технологий: распознавание репутации IP, введение прогрессивных задач, проверка HTTP‑заголовка, анализ поведения посетителей. Подробнее об этом в следующем разделе.
Нам важно про это знать не только ради защиты своего сайта, но и чтобы самим не оказаться «плохим» ботом. О том, как безопасно извлекать данные и не попадать под блокировки, в разделе «Как безопасно извлекать данные с сайта».
Как защититься от веб‑скрейпинга
Есть несколько способов. Чаще всего их используют вместе:
- Анализировать поведение посетителей сайта
Обычно ботов от реальных посетителей отличает то, что они делают много запросов за короткий период времени, а ещё просматривают страницы в нелогичном порядке — не как человек.
Когда попытки доступа к сайту определены как принадлежащие боту, они блокируются.
IP‑адрес — уникальный адрес конкретного компьютера (как номер телефона). Сайты хранят информацию об IP‑адресах, с которых к ним обращались.
IP‑адреса, которые в прошлом использовались для подозрительной активности, рассматриваются очень внимательно, и их доступ к сайту может быть заблокирован.
- Проверять HTTP‑заголовки
Поможет база HTTP‑заголовков браузеров, которые обращались к сайту и были опознаны как вредоносные: все следующие запросы проверяются через эту базу данных.
- Давать на выполнение прогрессивные задачи
Такие задачи предлагают выполнить пользователям, которые заходят с подозрительного IP‑адреса.
Самый простой пример — CAPTCHA (капча — «найдите все светофоры на картинке» и прочие). Боты не умеют её проходить, потому что для выполнения такой задачи нужно подключить логику или совершить осмысленные действия, что подвластно только человеку.
Благодаря прогрессивным задачам реальные посетители могут пользоваться сайтом неограниченно, а боты — нет. Правда, скрейпинг становится всё совершеннее и всё легче обходит простые прогрессивные задачи, которые, в свою очередь, тоже постоянно усложняются.
Как безопасно извлекать данные с сайта
Получается, когда мы скрейпим данные чужого сайта, нам нужно обойти защиты, о которых мы написали выше.
Вот как это сделать (можно использовать один способ, комбинировать несколько или задействовать все сразу):
- Установить корректный User‑Agent
При посещении сайта клиентское приложение — браузер — посылает серверу информацию о себе, которая начинается со строки User‑agent:’. Там содержится информация о приложении, его версии, ОС компьютера и языке.
В этой строке нужно корректно указать всю требуемую информацию, потому что запросы от неизвестных браузеров часто блокируют.
О нём мы писали выше. Укажите в HTTP‑заголовке запроса, с какого сайта вы пришли, чтобы вас пропустили. Вот как это выглядит:
- Подключить программу для решения прогрессивных задач (CAPTCHA)
Например, 2Captcha. Сервис платный — от 44 рублей за 1 000 решённых задач, подключается через API.
- Задать случайные интервалы между запросами к сайту
Пользователи не заходят на сайт тысячу раз в минуту и не сидят на сайте 24 часа в сутки. Если вы самостоятельно написали бот для веб‑скрейпинга, нужно указать, как часто ему заходить на сайт — в идеале так, как это делает обычный человек. Приложения для скрейпинга, о которых мы рассказываем ниже, делают это по умолчанию.
Прокси‑серверы помогают имитировать, будто запросы к сайту приходят с разных IP‑адресов, а не с одного и того же. Специальные сервисы для скрейпинга автоматически предусматривают ротацию IP.
Инструменты для веб‑скрейпинга
Часто программисты пишут конкретных ботов с конкретными функциями под конкретную задачу, но есть и более простые, специализированные инструменты для веб‑скрейпинга. Мы расскажем именно о них.
Большинство сервисов работают по одной и той же схеме: нужно зарегистрироваться и подтвердить адрес электронной почты, а затем можно начинать скрейпить.
Сам скрейпинг прост в управлении: нужно ввести адрес сайта и выбрать элементы, которые необходимо собрать. Приложение сделает всё за вас и даст возможность посмотреть результаты в читаемом формате. Весь процесс проходит онлайн.
Некоторые сервисы предлагают скачать их API (программу) для скрейпинга. Как правило, на сайте приложения всегда есть инструкция по установке и использованию.
Некоторые сервисы предлагают персональные решения — они сделают всю работу за вас. Для этого надо связаться с менеджментом конкретной компании.
Бесплатное расширение для Chrome. Можно собирать разные типы данных и экспортировать их в CSV, XLS или JSON.
Сервис с бесплатным тарифом для небольших проектов; для более сложных — от 75 долларов в месяц. Позволяет скачивать данные и хранить их в облаке, работает на Mac и Windows.
Обеспечивает ротацию IP и проходит CAPTCHA. Есть демоверсия — её нужно запросить на сайте.
Десктопная программа. Выберите данные, которые нужно собирать, и ждите. Данные можно выгрузить в формате JSON, Excel и API.
Бесплатно можно получить 200 страниц с данными. Платные тарифы начинаются от 189 долларов в месяц.
Сервис позволяет скрейпить одновременно несколько типов данных, формируя их в задачи и выполняя поочерёдно. Можно сделать шаблон для быстрого сбора однотипных данных. Есть 30‑дневный бесплатный пробный период.
Сервис скрейпинга сайтов и соцсетей. Для каждого типа данных — например, сырого HTML, информации с сайтов недвижимости или торговли — предоставляются разные API, они специализированы для определенного сектора.
Например, API для скрейпинга сырого HTML извлекает HTML‑код страниц. API для ритейла позволяет просматривать страницы товаров и извлекать цены, описания и прочее. API для недвижимости даёт возможность просматривать площадь, местоположения, цены.
Задачи в приложении оплачиваются кредитами — в бесплатной версии у вас будет 100 кредитов. Когда они закончатся, придётся заплатить от 39 евро в месяц за 100 000 кредитов.
Как и предыдущий, этот сервис предоставляет для скачивания API для скрейпинга. 1 000 запросов — бесплатно, платные тарифы — от 20 долларов в месяц.
Здесь решения создаются под каждый конкретный бизнес. Стоимость — от 40 долларов в месяц за один сайт.
Как в Datahut, здесь вам подберут персональное решение. Datamam, например, обойдется в 5 000+ долларов за полноценный сбор данных.
Выводы
- Веб‑скрейпинг — это автоматизированный сбор данных сайтов. Парсинг — это часть веб‑скрейпинга, процесс приведения собранных данных в читаемый вид.
- Скрейпинг нужен, чтобы анализировать цены конкурентов и эффективность своего контента, мониторить репутацию в соцсетях, корректировать описания товаров и услуг, искать идеи для эффективного контента.
- Скрейпинг бывает хорошим — например, работа поисковых роботов — и плохим, когда сбор данных используется для кражи контента или ценового демпинга.
- Чтобы защититься от скрейпинга данных, требуется анализировать поведение пользователей, проверять IP, HTTP‑заголовки запросов, ставить CAPTCHA.
- Чтобы пройти через защиты сайтов, нужно установить корректный User Agent, добавить в заголовок запроса referer, установить интервалы между запросами к сайту, использовать прокси для изменения IP‑адреса и подключить программу прохождения CAPTCHA.
- Для обхода защиты используют специальные сервисы. Это может быть веб‑приложение или десктопная программа, а ещё есть компании, которые занимаются скрейпингом на заказ.
В чем разница между парсингом и скрейпингом?
У вебмастера, маркетолога, SEO-специалиста, специалиста по ценообразованию регулярно возникает потребность в извлечении данных со страниц сайтов в удобном для дальнейшей обработки виде. В этой статье мы разберемся, какая технология применяется для сбора данных, что это за процесс, и почему у него несколько названий.
Чаще всего в русскоязычном пространстве сбор данных со страниц веб-ресурсов принято называть парсингом (parsing). В англоязычном пространстве этот процесс принято называть скрейпингом (scraping).
Давайте разбираться, что это за процессы, и есть ли разница между ними.
Изначально приложение, выполняющее две операции: выкачивания нужной информации с сайта и анализа контента сайта, называлось парсингом.
В переводе с английского «parsing» — это проведение грамматического разбора слова или текста. Это производное слово от латинского «pars orationis» — часть речи.
Парсинг — это метод, при котором информация анализируется и разбивается на компоненты. Затем полученные данные преобразуются в пригодный формат для дальнейшей обработки, в процессе чего один формат данных превращается в другой, более читаемый.
Допустим, данные извлекаются в необработанном коде HTML, а парсер принимает его и преобразует в формат, который можно легко проанализировать и понять.
Парсинг использует инструментарий, который извлекает нужные значения из любых форматов данных. Извлеченные данные сохраняются в отдельном файле на компьютере/в облаке или напрямую в базе данных. Это процесс, который запускается автоматически.
Дальнейший анализ собранной информации осуществляет специальное программное обеспечение.
Что значит парсить?
Парсер — программное решение, а парсинг — процесс. Типичный процесс парсинга сайтов состоит из следующих последовательных шагов:
‣ Идентификация целевых URL-адресов.
‣ Если веб-сайт, сканируемый для сбора данных, использует инструменты противодействия парсингу, то парсер, подбирает подходящий прокси-сервер, чтобы получить новый IP-адрес, через который отправляет свой запрос. Если необходимо, задействуется сервис разгадывания капчи.
‣ Отправка GET/POST запросов на эти URL-адреса.
‣ Поиск и обнаружение местонахождения необходимых данных в HTML-коде.
‣ Преобразование этих данных в нужный формат.
‣ Передача собранной информации в выбранное хранилище данных.
‣ Экспорт данных в нужном формате для дальнейшей работы с ними.

Со временем процесс выкачивания нужной информации с сайта и анализа контента сайта стали разделять на две самостоятельные операции. Был придуман термин краулер. Краулер занимается обходом сайта и сбором данных, а парсер анализом содержимого.
Позднее придумали термин скрейпинг. Веб-скрейпинг объединяет в себе функции краулера и парсера.
Вот какое определение веб-скрейпинга дает Википедия:
Веб-скрейпинг (или скрепинг, или скрапинг← англ. web scraping) — это технология получения веб-данных путем извлечения их со страниц веб-ресурсов. Веб-скрейпинг может быть сделан вручную пользователем компьютера, однако термин обычно относится к автоматизированным процессам, реализованным с помощью кода, который выполняет GET-запросы на целевой сайт.
Веб-скрейпинг используется для синтаксического преобразования веб-страниц в более удобные для работы формы. Веб-страницы создаются с использованием текстовых языков разметки (HTML и XHTML) и содержат множество полезных данных в коде. Однако большинство веб-ресурсов предназначено для конечных пользователей, а не для удобства автоматического использования, поэтому была разработана технология, которая «очищает» веб-контент.
Загрузка и просмотр страницы — важнейшие составляющие технологии, они являются неотъемлемой частью выборки данных.
Но у русскоязычной аудитории термин скрейпинг/скрапинг не прижился. У нас гораздо чаще для обозначения всего процесса сбора и анализа информации используют слово парсер.
И это наглядно доказывает Яндекс Wordstat. Так по слову “парсинг” ежемесячно создается в среднем 62 тысячи запросов.


В то время как слово “скрапинг” ищут около 1300 раз в месяц, а “скрейпинг” менее 500 раз.


Задачи веб-скрейпинга/парсинга
Основная задача скрейпинга, это быстрое получение нужных данных из интернета с помощью специальных программ/ботов.
Большинство веб-ресурсов предназначено для конечных пользователей, а не для удобства автоматического использования, поэтому была разработана технология, которая «очищает» веб-контент и производит синтаксическое преобразование веб-страниц для последующего извлечения и анализа.
В основном веб-скрейперы решают следующие задачи:
• поиск необходимой информации;
• копирование данных из интернета;
• мониторинг обновлений на сайтах.
К категории данных, которые можно парсить, относятся:
То есть любые открытые данные — каталоги товаров, адреса электронной почты, телефоны и другая информация.
Веб-скрейпинг может быть как самостоятельным инструментом и служить для целевого поиска информации, так и может стать компонентом веб-разработки для веб-индексации, веб-майнинга и интеллектуального анализа данных, онлайн-мониторинга изменения цен и их сравнения, для наблюдения за конкуренцией, и другого сбора данных.
Как используют полученные данные
У веб-скрейпинга/парсинга очень широкий спектр применений. Например:
1. Отслеживание цен и наличия товаров
Многие ритейлеры используют в своей работе сбор информации о товарах, их ценах и наличии на сайтах конкурентов и маркетплейсах. Сервисы мониторинга цен позволяют не только парсить данные о товарах конкурентов с сайтов и маркетплейсов, но и производят первоначальную аналитику, представляя данные в виде наглядных таблиц и графиков.

2. Рыночная и конкурентная разведка
Если вы хотите зайти на новый рынок, то сначала нужно оценить свои шансы и принять взвешенное решение.
Сбор и анализ данных может быть значительным преимуществом и для тех, кто сталкивается с жесткой конкуренцией в своей нише. Скрейпинг сайтов конкурентов позволяет узнать ассортиментную матрицу, структуру цен, объемы продаж, методы маркетинга и т.д. Автоматизация сбора данных позволяет высвободить время сотрудников для более качественного анализа и решения стратегических задач.

3. Модернизация сайтов
При переносе данных с устаревших сайтов на современные платформы используют скрейпинг для быстрой и легкой перезаливки данных.
4. Мониторинг новостей
Скрейпинг новостных сайтов и блогов позволяет всегда быть в курсе новостей на интересующие темы и экономить время на поиск. Этим занимаются такие платформы, как Brand Analytics, Интегрум, Медиалогия.
5. Анализ эффективности контента
Блогеры, SMM-специалисты и контентмейкеры используют скрейпинг для сбора статистики своих публикаций, а модераторы и редакторы групп — для отслеживания динамики развития своих сообществ.
YouScan, Brand Analytics и другие платформы для мониторинга соцсетей активно используют скрейпинг.
6. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет бизнесу составлять списки контактов потенциальных клиентов, поставщиков, производителей и другой сопутствующей информации.
Как собирается информация
Сейчас не нужно знать программирование, чтобы осуществлять скрейпинг/парсинг. Достаточно подобрать отвечающий вашим целям готовый парсер или сервис, заточенный на парсинг информации под конкретную бизнес-задачу.
За счет использования парсеров, можно получать и одновременно обрабатывать крупные массивы данных, что является огромным преимуществом подобных программ. Алгоритмы работы парсеров на данный момент адаптированы для того, чтобы специалист без IT- образования мог справиться с подобной задачей.
Сбор требуемых данных осуществляется за счет шаблонов, которые под свои нужды настраивает сам клиент. Это могут быть различные фильтры по типу ключевых слов, желаемых данных и других настроек.
Как правило, данные, собранные парсером, отдаются заказчику в необходимом формате, который:
‣ легко сортируется и редактируется;
‣ просто добавляется в БД;
‣ доступен для повторного использования;
‣ легко преобразуется в графический формат.
Основные преимущества использования веб-скрапинга
1. Эффективное управление данными
Использование автоматизированного программного обеспечения и платформ для извлечения и сохранения данных позволяет работать с большим и даже гигантским объемом данных, а их наличие позволяет проводить качественный анализ и строить высокоточные прогнозы.
2. Точность данных
Сервисы парсинга не только быстрые, но и точные. Человеческая ошибка часто является проблемой при выполнении работы вручную, что в дальнейшем может привести к серьезным ошибкам и неверным решениям. Автоматизация извлечения данных имеет решающее значение для точности и актуальности сбора любого вида информации.
3. Скорость
Кроме того, важно отметить скорость, с которой системы парсинга выполняют задачи. Рутинные процессы, которые человек делал бы недели, у него занимают считанные часы или даже минуты. Скорость сбора данных парсером подбирается под сложность реализуемых проектов, наличие ресурсов и возможности технологий.
4. Оптимальная стоимость
Когда дело доходит до технического обслуживания, при внедрении новых услуг часто упускают из виду стоимость. К счастью, в наше время нет смысла разрабатывать и внедрять собственную систему парсинга, на рынке широко представлены сервисы скрейпинга данных, закрывающие все направления и потребности, как компаний, так и конечных пользователей. Абонентская плата у специализированных сервисов на данный момент довольно демократична, а сами парсеры не требуют затрат на обслуживание, так как эта опция входит в стоимость оплаты услуг.
5. Простота реализации
Продуманные алгоритмы настройки компаний, специализирующихся на скрейпинге, позволяют в короткие сроки оптимизиовать алгоритмы сбора данных под задачи клиента и оперативно приступить к их сбору.
6. Рентабельность
Извлечение данных вручную — дорогостоящая работа, требующая большой команды и значительного бюджета. Онлайн-скрейпинг решил эту проблему. Данные, получаемые посредством автоматизированного парсинга, рентабельны. А их окупаемость полностью зависит от объема требуемых данных и целей заказчика.
7. Автоматизация
Основное преимущество онлайн-скрейпинга — это разработка технологий, которые позволили сократить извлечение данных со многих веб-сайтов до нескольких щелчков мышью.
Вывод
Значение скрейпинга или парсинга, называйте этот процесс, как вам привычней, в наше время невозможно переоценить. Его используют даже для поиска лучшего рецепта приготовление борща, не говоря уже про поиск необходимых данных для бизнеса.
Без этого инструмента невозможно представить работу ни одной серьезной компании. А с ростом цифровизации всех процессов в экономике и обществе все чаще применяют data-driven подход. В этом подходе оптимизация бизнес-процессов и стратегические решения принимаются на основании сбора данных и их последующей обработки с помощью аналитических инструментов.
Расхожее выражение утверждает, что данные — новая нефть, в таком случае скрейпинг, это нефтедобывающий комплекс. Кто им владеет, тот управляет ситуацией и извлекает максимум пользы.
- Журнал обновлений (33)
- Кейсы (33)
- Новости (40)
- Статьи (167)
- KVI-товары (3)
- Ассортиментный анализ (3)
- Бизнес-стратегии и фреймворки (10)
- Знакомство с Priceva (8)
- Интернет-магазин (13)
- Маркетплейсы (6)
- Матчинг (1)
- Методы и приемы работы с ценой (37)
- Методы стимулирования сбыта (24)
- Мониторинг цен (8)
- Покупатели: методы изучения и воздействия (21)
- Репрайсинг (2)
- РРЦ (2)
- Тренды (18)
- Ценовые стратегии (27)
О нас
- Кто мы? Платформа мониторинга цен для интернет-магазинов и брендов
- Что мы делаем? Автоматизируем ценообразование и мониторинг за ценами.
- Что получается? За 6 лет мы создали платформу, которой пользуются 400 интернет-магазинов и 5 0 брендов . Наши клиенты ежедневно следят за ценами 35 000 сайтов .
Настройка трекеров
Для того, чтобы активировать использование какого-либо трекера в emupdate, вам нужно включить его плагин в конфиге и, если потребуется, указать свой логин и пароль для сайта. Кроме того, плагины имеют ряд параметров, таких как прокси и таймауты, которые вы можете настроить индивидуально для каждого трекера. Включение плагина осуществляется добавлением его в секцию trackers , как было указано ранее. Параметры передаются внутри секции с именем плагина, например trackers/rutracker.org/timeout=5.0 .
Представленные ниже параметры доступны для всех трекерных плагинов; рутрекер используется лишь в качестве примера.
- trackers/rutracker.org/check_fingerprint=true
- Перед логином на трекер, emupdate идет на гитхаб и проверяет информацию о плагине. В ней содержится кодировка целевого сайта, кусочек текста с его главной страницы (fingerprint) и версия плагина в апстриме. Плагин трекера скачивает главную страницу сайта, а затем ищет в ней подстроку фингерпринта. Если таковой не находится, он делает вывод, что сайт заблокирован провайдером и отказывается работать дальше. Более надежным был бы метод проверки сертификатов, но на данный момент ни один из популярных трекеров не имеет нормально настроенного HTTPS.
- Этот параметр почти аналогичен предыдущей, но сравнивает локальную версию плагина с апстримовой. Если в апстриме версия выше, то плагин отказывается работать. Апстримовые версии повышаются только в том случае, если трекер меняет разметку страниц таким образом, что плагины перестают работать, а в апстриме уже есть исправление. Использование этого параметра подсказывает вам, что пора обновить Emonoda, чтобы плагин заработал вновь.
- Позволяет указать прокси для сайта. Поддерживаются HTTP-прокси и SOCKS4/5. Этот параметр можно использовать так: trackers/rutracker.org/proxy_url=socks5://localhost:5000 (вместе с SOCKS-проксированием по SSH). Формат — scheme://username:passwd@host:port . Вместо scheme нужно указать socks4 , socks5 или http .
- Количество повторов при обращении к трекеру при возникновении таймаутов, пятисоток или специфичных для сайта ошибок (например, 404 у рутрекера при скачке торрент-файла не является критической ошибкой, т.к. иногда сайт отдает неправильный бекенд за балансером, и программе нужно просто несколько раз повторить свой запрос).
- Пауза между повторами при использовании предыдущего параметра.
- Таймаут на сетевые операции с трекером.
- Плагины прикидываются браузером при работе с трекерами. Для некоторых плагинов значение по умолчанию для этого параметра отличается (например, Googlebot/2.1 для http://rutor.org позволяет обходить DDoS-фильтр CloudFlare).
Некоторые параметры применяются только для неанонимных трекеров, а так же для трекеров, к которым требуется выполнять SCRAPE-запрос. Например, trackers/nnmclub.to/client_agent . Здесь приведен полных их список с назначением, а так же таблица, где перечислены использующие их трекеры.
Плагин nnmclub.to с последних версий теперь тоже использует парсинг времени, а не SCRAPE-запросы. На данный момент ни один плагин не использует SCRAPE, а пример в этой документации оставлен для истории и понимания, что такое вообще бывает.
- trackers/rutracker.org/user=»»
- Имя пользователя на сайте, обязательно для неанонимных трекеров.
- Имя пользователя на сайте, обязательно для неанонимных трекеров.
- На некоторых трекерах отсутствует хеш раздачи на странице, но при этом можно выполнить SCRAPE-запрос, чтобы проверить, зарегистрирована ли раздача. Если не зарегистрирована, то это значит, что пора ее обновить. Этот параметр определяет юзерагент для SCRAPE-запросов, чтобы плагин трекера мог прикинуться торрент-клиентом.
- Если не доступны ни хеш раздачи, ни SCRAPE, то последнее, что остается делать — парсить страницу на предмет времени обновления раздачи. Этот параметр задает таймзону сайта. Обычно плагины определяют ее самостоятельно, заходя под вашим логином на личную страницу с настройками сайта. Такие плагины сравнивают последнее время обновления торрент-файла с новой датой и на основе этого выносят решение о необходимости нового обновления.
В таблице ниже дан список всех доступных плагинов и специфичных для них опций:
Плагин user, passwd client_agent timezone rutracker.org Обязательно nnm-club.me Обязательно Опционально ipv6.nnm-club.name Обязательно Опционально rutor.org pravtor.ru Обязательно tr.anidub.com Обязательно Опционально pornolab.net Обязательно Опционально booktracker.org Обязательно Опционально trec.to Обязательно Опционально kinozal.tv Обязательно Опционально