Как применить функцию ко всем строкам?
Есть класс, в нем первый метод получает на вход два вектора (в виде пандас фреймов или нумпай матриц), хитрым способом обрабатывает их и на выходе выдает кортеж из 2 элементов. Этот метод уже написан. Второй метод класса получает на вход вектор Y и массив X (не вектор, в нем неизвестное количество столбцов). Этот метод должен вызывать первый метод, давать ему на вход вектор Y и поочередно каждый столбец матрицы X , получать на выходе кортежи из двух элементов и заполнять ими нумпаевскую матрицу (количество строк этой матрицы равно количеству столбцов матрицы X , количество столбцов этой матрицы равно 2, при инициализации я предполагаю заполнить ее np.nan , а затем перезаполнить). Безусловно реализовать функционал второго метода можно просто через цикл по каждому столбцу массива X . Однако не хотелось бы использовать цикл. Я подумал, может как то это сделать через pandas.apply (предварительно переведя все получаемые на вход объекты в пандас фреймы) или numpy.apply_along_axis , или может другие варианты есть. То есть использовать функционал, который в каждую строку нумпаевской матрицы вписывает нужные значения используя нужный столбец массива Х .
Отслеживать
2,326 2 2 золотых знака 11 11 серебряных знаков 38 38 бронзовых знаков
задан 2 мар 2023 в 8:26
IvanZharov IvanZharov
117 6 6 бронзовых знаков
вам в вопросе нужно было указать исходные данные, желаемый результат и краткие тезисы, а не соревноваться с Маркесом в эпистолярном жанре. tldr, короче
4 приема Python NumPy, которые должен знать каждый новичок
NumPy является одной из самых популярных библиотек в Python, и, учитывая ее преимущества, почти каждый программист Python использовал данную библиотеку для арифметических вычислений. Массивы Numpy более компактны, чем списки Python. Эта библиотека также очень удобна, так как многие обычные матричные операции выполнены очень эффективным вычислительным способом.
Помогая коллегам и друзьям с трудностями в NumPy, мы пришли к 4 приемам, которые должен знать каждый новичок Python. Эти фишки помогут вам написать более аккуратные и читаемые коды.
1. Arg-функции — позиции
Для массива функции arr , np.argmax(arr) , np.argmin(arr) и np.argwhere(condition(arr)) возвращают показатели максимальных значений, минимальных значений и значений, которые удовлетворяют определенным условиям пользователя соответственно. Хотя эти функции arg широко используются, мы часто игнорируем функцию np.argsort() , возвращающую показатели, которые сортируют массив.
Мы можем использовать np.argsort для сортировки значений массивов по другому массиву. Ниже представлен пример сортировки имен студентов с использованием их результатов экзамена. Отсортированный массив имен также можно преобразовать обратно в исходный порядок, используя np.argsort(np.argsort(score)).
1. score = np.array([70, 60, 50, 10, 90, 40, 80])
2. name = np.array(['Ada', 'Ben', 'Charlie', 'Danny', 'Eden', 'Fanny', 'George'])
3. sorted_name = name[np.argsort(score)] # an array of names in ascending order of their scores
4. print(sorted_name) # ['Danny' 'Fanny' 'Charlie' 'Ben' 'Ada' 'George' 'Eden']
5.
6. original_name = sorted_name[np.argsort(np.argsort(score))]
7. print(original_name) # ['Ada' 'Ben' 'Charlie' 'Danny' 'Eden' 'Fanny' 'George']
8.
9.
10. %timeit name[np.argsort(score)]
11. # 1.83 µs ± 182 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
12. %timeit sorted(zip(score, name))
13. # 3.2 µs ± 76.7 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
Эффективность данной функции выше, нежели результат использования встроенной функции Python sorted(zip()) . Кроме того, она, пожалуй, более читабельна.

2. Бродкастинг — формы
Бродкастинг — это то, что новичок numpy мог уже невольно попробовать сделать. Многие арифметические операции numpy применяются к парам массивов одинаковой формы для каждого элемента. Бродкастинг векторизует операции с массивами без создания ненужных копий данных. Это приводит к эффективной реализации алгоритма и более высокой читаемости кода.
Например, вы можете использовать приращение всех значений в массиве на 1, используя arr + 1 независимо от измерения arr . Вы также можете проверить, все ли значения в массиве больше, чем 2, с помощью arr > 2 .
Но как мы узнаем, совместимы ли два массива с бродкастинг?
Argument 1 (4D array): 7 × 5 × 3 × 1
Argument 2 (3D array): 1 × 3 × 9
Output (4D array): 7 × 5 × 3 × 9
Измерение одного массива должно быть либо равно измерению другого массива, либо одно из них равно 1. Массивы необязательно должны иметь одинаковое количество измерений, что продемонстрировано в примере выше.
3. Параметры Ellipsis и NewAxis
Синтаксис для нарезки массива numpy — это i:j где i, j — начальный индекс и индекс остановки соответственно. Например, для массива numpy arr = np.array(range(10)) команда arr[:3] дает [0, 1, 2] .

При работе с массивами с более высокими размерностями мы используем : для выбора индекса по каждой оси. Мы также можем использовать . для выбора индексов по нескольким осям. Точное количество осей выводится.
1. arr = np.array(range(1000)).reshape(2,5,2,10,-1)
2. print(arr[. 3,2] == arr[. 3,2])
3. # [[[ True, True],
4. # [ True, True],
5. # [ True, True],
6. # [ True, True],
7. # [ True, True]],
8. # [[ True, True],
9. # [ True, True],
10. # [ True, True],
11. # [ True, True],
12. # [ True, True]]])
13.
14. print(arr.shape) # (2, 5, 2, 10, 5)
15. print(arr[. np.newaxis. ].shape) # (2, 5, 1, 2, 10, 5)
С другой стороны, использование, np.newaxis , как показано выше, вставляет новую ось в заданное пользователем положение оси. Эта операция расширяет форму массива на одну единицу измерения. Хотя это также можно сделать с помощью np.expand_dims() , использование np.newaxis гораздо более читабельно и, пожалуй, изящно.
4. Замаскированный массив — селекция
Наборы данных несовершенны. Они всегда содержат массивы с отсутствующими или неверными записями, и мы часто хотим игнорировать эти элементы. Например, измерения на метеостанции могут содержать пропущенные значения из-за сбоя датчика.
У Numpy есть подмодуль numpy.ma , который поддерживает массивы данных с масками. Маскированный массив содержит обычный массив numpy и маску, которая указывает положение недопустимых записей.
np.ma.MaskedArray(data=arr, mask=invalid_mask)

Недопустимые записи в массиве иногда помечаются с использованием отрицательных значений или строк. Если мы знаем замаскированное значение, скажем -999 , мы можем также создать замаскированный массив, используя np.ma.masked_values(arr, value=-999) . Любая операция numpy, принимающая замаскированный массив в качестве аргумента, автоматически игнорирует эти недействительные записи, как показано ниже.
1. import math
2. def is_prime(n):
3. assert n > 1, 'Input must be larger than 1'
4. if n % 2 == 0 and n > 2:
5. return False
6. return all(n % i for i in range(3, int(math.sqrt(n)) + 1, 2))
7.
8. arr = np.array(range(2,100))
9. non_prime_mask = [not is_prime(n) for n in a]
10. prime_arr = np.ma.MaskedArray(data=arr, mask=non_prime_mask)
11. print(prime_arr)
12. # [2 3 -- 5 -- 7 -- -- -- 11 -- 13 -- -- -- 17 -- 19 -- -- -- 23 -- -- -- --
13. # -- 29 -- 31 -- -- -- -- -- 37 -- -- -- 41 -- 43 -- -- -- 47 -- -- -- --
14. # -- 53 -- -- -- -- -- 59 -- 61 -- -- -- -- -- 67 -- -- -- 71 -- 73 -- --
15. # -- -- -- 79 -- -- -- 83 -- -- -- -- -- 89 -- -- -- -- -- -- -- 97 -- --]
16.
17. arr = np.array(range(11))
18. print(arr.sum()) # 55
19.
20. arr[-1] = -999 # indicates missing value
21. masked_arr = np.ma.masked_values(arr, -999)
22. print(masked_arr.sum()) # 45
23.
NumPy, часть 2: базовые операции над массивами

Здравствуйте! Я продолжаю работу над пособием по python-библиотеке NumPy.
В прошлой части мы научились создавать массивы и их печатать. Однако это не имеет смысла, если с ними ничего нельзя делать.
Сегодня мы познакомимся с операциями над массивами.
Базовые операции
Математические операции над массивами выполняются поэлементно. Создается новый массив, который заполняется результатами действия оператора.
:1: RuntimeWarning: divide by zero encountered in true_divide
Для этого, естественно, массивы должны быть одинаковых размеров.
File
Также можно производить математические операции между массивом и числом. В этом случае к каждому элементу прибавляется (или что вы там делаете) это число.
NumPy также предоставляет множество математических операций для обработки массивов:
Полный список можно посмотреть здесь.
Многие унарные операции, такие как, например, вычисление суммы всех элементов массива, представлены также и в виде методов класса ndarray.
Индексы, срезы, итерации
Одномерные массивы осуществляют операции индексирования, срезов и итераций очень схожим образом с обычными списками и другими последовательностями Python (разве что удалять с помощью срезов нельзя).
File У многомерных массивов на каждую ось приходится один индекс. Индексы передаются в виде последовательности чисел, разделенных запятыми (то бишь, кортежами):
Когда индексов меньше, чем осей, отсутствующие индексы предполагаются дополненными с помощью срезов:
b[i] можно читать как b[i, ]. В NumPy это также может быть записано с помощью точек, как b[i, . ].
Например, если x имеет ранг 5 (то есть у него 5 осей), тогда
- x[1, 2, . ] эквивалентно x[1, 2, :, :, :],
- x[. , 3] то же самое, что x[:, :, :, :, 3] и
- x[4, . , 5, :] это x[4, :, :, 5, :].
Итерирование многомерных массивов начинается с первой оси:
Однако, если нужно перебрать поэлементно весь массив, как если бы он был одномерным, для этого можно использовать атрибут flat:
Как уже говорилось, у массива есть форма (shape), определяемая числом элементов вдоль каждой оси:
Форма массива может быть изменена с помощью различных команд:
Порядок элементов в массиве в результате функции ravel() соответствует обычному "C-стилю", то есть, чем правее индекс, тем он "быстрее изменяется": за элементом a[0,0] следует a[0,1]. Если одна форма массива была изменена на другую, массив переформировывается также в "C-стиле". Функции ravel() и reshape() также могут работать (при использовании дополнительного аргумента) в FORTRAN-стиле, в котором быстрее изменяется более левый индекс.
Метод reshape() возвращает ее аргумент с измененной формой, в то время как метод resize() изменяет сам массив:
Если при операции такой перестройки один из аргументов задается как -1, то он автоматически рассчитывается в соответствии с остальными заданными:
Объединение массивов
Несколько массивов могут быть объединены вместе вдоль разных осей с помощью функций hstack и vstack.
hstack() объединяет массивы по первым осям, vstack() — по последним:
Функция column_stack() объединяет одномерные массивы в качестве столбцов двумерного массива:
Аналогично для строк имеется функция row_stack().
Разбиение массива
Используя hsplit() вы можете разбить массив вдоль горизонтальной оси, указав либо число возвращаемых массивов одинаковой формы, либо номера столбцов, после которых массив разрезается "ножницами":
Функция vsplit() разбивает массив вдоль вертикальной оси, а array_split() позволяет указать оси, вдоль которых произойдет разбиение.
Копии и представления
При работе с массивами, их данные иногда необходимо копировать в другой массив, а иногда нет. Это часто является источником путаницы. Возможно 3 случая:
Вообще никаких копий
Простое присваивание не создает ни копии массива, ни копии его данных:
Python передает изменяемые объекты как ссылки, поэтому вызовы функций также не создают копий.
Представление или поверхностная копия
Разные объекты массивов могут использовать одни и те же данные. Метод view() создает новый объект массива, являющийся представлением тех же данных.
Срез массива это представление:
Глубокая копия
Метод copy() создаст настоящую копию массива и его данных:
Для вставки кода на Python в комментарий заключайте его в теги
- Модуль csv - чтение и запись CSV файлов
- Создаём сайт на Django, используя хорошие практики. Часть 1: создаём проект
- Онлайн-обучение Python: сравнение популярных программ
- Книги о Python
- GUI (графический интерфейс пользователя)
- Курсы Python
- Модули
- Новости мира Python
- NumPy
- Обработка данных
- Основы программирования
- Примеры программ
- Типы данных в Python
- Видео
- Python для Web
- Работа для Python-программистов
- Сделай свой вклад в развитие сайта!
- Самоучитель Python
- Карта сайта
- Отзывы на книги по Python
- Реклама на сайте
NumPy: матрицы и операции над ними
В этом ноутбуке из сторонних библиотек нам понадобится только NumPy. Для удобства импортируем ее под более коротким именем:
import numpy as np
1. Создание матриц
Приведем несколько способов создания матриц в NumPy.
Самый простой способ — с помощью функции numpy.array(list, dtype=None, . ).
В качестве первого аргумента ей надо передать итерируемый объект, элементами которого являются другие итерируемые объекты одинаковой длины и содержащие данные одинакового типа.
Второй аргумент является опциональным и определяет тип данных матрицы. Его можно не задавать, тогда тип данных будет определен из типа элементов первого аргумента. При задании этого параметра будет произведена попытка приведения типов.
Например, матрицу из списка списков целых чисел можно создать следующим образом:
a = np.array([1, 2, 3]) # Создаем одномерный массив print(type(a)) # Prints "" print(a.shape) # Prints "(3,)" - кортеж с размерностями print(a[0], a[1], a[2]) # Prints "1 2 3" a[0] = 5 # Изменяем значение элемента массива print(a) # Prints "[5, 2, 3]" b = np.array([[1,2,3],[4,5,6]]) # Создаем двухмерный массив print(b.shape) # Prints "(2, 3)" print(b[0, 0], b[0, 1], b[1, 0]) # Prints "1 2 4" print(np.arange(1, 5)) #Cоздает вектор с эелементами от 1 до 4
(3,) 1 2 3 [5 2 3] (2, 3) 1 2 4 [1 2 3 4]
matrix = np.array([[1, 2, 3], [2, 5, 6], [6, 7, 4]]) print ("Матрица:\n", matrix)
Матрица: [[1 2 3] [2 5 6] [6 7 4]]
Второй способ создания — с помощью встроенных функций numpy.eye(N, M=None, . ), numpy.zeros(shape, . ), numpy.ones(shape, . ).
Первая функция создает единичную матрицу размера N×M ; если M не задан, то M = N .
Вторая и третья функции создают матрицы, состоящие целиком из нулей или единиц соответственно. В качестве первого аргумента необходимо задать размерность массива — кортеж целых чисел. В двумерном случае это набор из двух чисел: количество строк и столбцов матрицы.
Примеры:
b = np.eye(5) print ("Единичная матрица:\n", b)
Единичная матрица: [[1. 0. 0. 0. 0.] [0. 1. 0. 0. 0.] [0. 0. 1. 0. 0.] [0. 0. 0. 1. 0.] [0. 0. 0. 0. 1.]]
c = np.ones((7, 5)) print ("Матрица, состоящая из одних единиц:\n", c)
Матрица, состоящая из одних единиц: [[1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.] [1. 1. 1. 1. 1.]]
d = np.full((2,2), 7) # Создает матрицу (1, 2) заполненую заданным значением print(d) # Prints "[[ 7. 7.] # [ 7. 7.]]" e = np.random.random((2,2)) # Создает еденичную матрицу (2, 2) заполненую случаными числами (0, 1) print(e) # Might print "[[ 0.91940167 0.08143941] # [ 0.68744134 0.87236687]]"
[[7 7] [7 7]] [[0.25744383 0.48056466] [0.13767881 0.40578168]]
Обратите внимание: размерность массива задается не двумя аргументами функции, а одним — кортежем!
Вот так — np.ones(7, 5) — создать массив не получится, так как функции в качестве параметра shape передается 7, а не кортеж (7, 5).
И, наконец, третий способ — с помощью функции numpy.arange([start, ]stop, [step, ], . ), которая создает одномерный массив последовательных чисел из промежутка [start, stop) с заданным шагом step, и метода array.reshape(shape).
Параметр shape, как и в предыдущем примере, задает размерность матрицы (кортеж чисел). Логика работы метода ясна из следующего примера:
v = np.arange(0, 24, 2) print ("Вектор-столбец:\n", v)
Вектор-столбец: [ 0 2 4 6 8 10 12 14 16 18 20 22]
d = v.reshape((3, 4)) print ("Матрица:\n", d)
Матрица: [[ 0 2 4 6] [ 8 10 12 14] [16 18 20 22]]
Более подробно о том, как создавать массивы в NumPy, см. документацию.
2. Индексирование
Для получения элементов матрицы можно использовать несколько способов. Рассмотрим самые простые из них.
Для удобства напомним, как выглядит матрица d:
print ("Матрица:\n", d)
Матрица: [[ 0 2 4 6] [ 8 10 12 14] [16 18 20 22]]
Элемент на пересечении строки i и столбца j можно получить с помощью выражения array[i, j].
Обратите внимание: строки и столбцы нумеруются с нуля!
print ("Второй элемент третьей строки матрицы:", d[2, 1])
Второй элемент третьей строки матрицы: 18
Из матрицы можно получать целые строки или столбцы с помощью выражений array[i, :] или array[:, j] соответственно:
print ("Вторая строка матрицы d:\n", d[1, :]) print ("Четвертый столбец матрицы d:\n", d[:, 3])
Вторая строка матрицы d: [ 8 10 12 14] Четвертый столбец матрицы d: [ 6 14 22]
Еще один способ получения элементов — с помощью выражения array[list1, list2], где list1, list2 — некоторые списки целых чисел. При такой адресации одновременно просматриваются оба списка и возвращаются элементы матрицы с соответствующими координатами. Следующий пример более понятно объясняет механизм работы такого индексирования:
print ("Элементы матрицы d с координатами (1, 2) и (0, 3):\n", d[[1, 0], [2, 3]])
Элементы матрицы d с координатами (1, 2) и (0, 3): [12 6]
# Slicing # Создадим матрицу (3, 4) # [[ 1 2 3 4] # [ 5 6 7 8] # [ 9 10 11 12]] a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) # Используя слайсинг, созадим матрицу b из элементов матрицы а # будем использовать 0 и 1 строку, а так же 1 и 2 столебц # [[2 3] # [6 7]] b = a[:2, 1:3] print(b) # ОБРАТИТЕ ВНИМАНИЕ НА ИЗМЕНЕНИЕ ИСХОДОЙ МАТРИЦЫ print(a[0, 1]) # Prints "2" b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1] print(a[0, 1]) # Prints "77"
[[2 3] [6 7]] 2 77
# Integer array indexing a = np.array([[1,2], [3, 4], [5, 6]]) print(a) print() # Пример Integer array indexing # В результате получится массив размерности (3,) # Обратите внимание, что до запятой идут индексы строк, после - столбцов print(a[[0, 1, 2], [0, 1, 0]]) # Prints "[1 4 5]" print() # По-другому пример можно записать так print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # Prints "[1 4 5]"
[[1 2] [3 4] [5 6]] [1 4 5] [1 4 5]
Примеры использования слайсинга:
# Создадим новый маассив, из которого будем выбирать эллементы a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]]) print(a) # prints "array([[ 1, 2, 3], # [ 4, 5, 6], # [ 7, 8, 9], # [10, 11, 12]])" # Создадим массив индексов b = np.array([0, 2, 0, 1]) # Выберем из каждой строки элемент с индексом из b (индекс столбца берется из b) print(a[np.arange(4), b]) # Prints "[ 1 6 7 11]" print() # Добавим к этим элементам 10 a[np.arange(4), b] += 10 print(a) # prints "array([[11, 2, 3], # [ 4, 5, 16], # [17, 8, 9], # [10, 21, 12]])
[[ 1 2 3] [ 4 5 6] [ 7 8 9] [10 11 12]] [ 1 6 7 11] [[11 2 3] [ 4 5 16] [17 8 9] [10 21 12]]
a = np.array([[1,2], [3, 4], [5, 6]]) bool_idx = (a > 2) # Найдем эллементы матрицы a, которые больше 2 # В результате получим матрицу b, такой же размерности, как и a print(bool_idx) # Prints "[[False False] print() # [ True True] # [ True True]]" # Воспользуемся полученным массивом для создания нового массива, ранга 1 print(a[bool_idx]) # Prints "[3 4 5 6]" # Аналогично print(a[a > 2]) # Prints "[3 4 5 6]"
[[False False] [ True True] [ True True]] [3 4 5 6] [3 4 5 6]
#Помните, что вы можете пользоваться сразу несколькими типами индексирования a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]]) row_r1 = a[1, :] row_r2 = a[1:2, :] print(row_r1, row_r1.shape) # Prints "[5 6 7 8] (4,)" print(row_r2, row_r2.shape) # Prints "[[5 6 7 8]] (1, 4)"
[5 6 7 8] (4,) [[5 6 7 8]] (1, 4)
Более подробно о различных способах индексирования в массивах см. документацию.
3. Векторы, вектор-строки и вектор-столбцы
Следующие два способа задания массива кажутся одинаковыми:
a = np.array([1, 2, 3]) b = np.array([[1], [2], [3]])
Однако, на самом деле, это задание одномерного массива (то есть вектора) и двумерного массива:
print ("Вектор:\n", a) print ("Его размерность:\n", a.shape) print ("Двумерный массив:\n", b) print ("Его размерность:\n", b.shape)
Вектор: [1 2 3] Его размерность: (3,) Двумерный массив: [[1] [2] [3]] Его размерность: (3, 1)
Обратите внимание: вектор (одномерный массив) и вектор-столбец или вектор-строка (двумерные массивы) являются различными объектами в NumPy, хотя математически задают один и тот же объект. В случае одномерного массива кортеж shape состоит из одного числа и имеет вид (n,), где n — длина вектора. В случае двумерных векторов в shape присутствует еще одна размерность, равная единице.
В большинстве случаев неважно, какое представление использовать, потому что часто срабатывает приведение типов. Но некоторые операции не работают для одномерных массивов. Например, транспонирование (о нем пойдет речь ниже):
a = a.T b = b.T
print ("Вектор не изменился:\n", a) print ("Его размерность также не изменилась:\n", a.shape) print ("Транспонированный двумерный массив:\n", b) print ("Его размерность изменилась:\n", b.shape)
Вектор не изменился: [1 2 3] Его размерность также не изменилась: (3,) Транспонированный двумерный массив: [[1 2 3]] Его размерность изменилась: (1, 3)
4. Datatypes
Все элементы в массиве numpy принадлежат одному типу. В этом плане массивы ближе к C, чем к привычным вам листам питона. Numpy имеет множество встренных типов, подходящих для решения большинства задач.
x = np.array([1, 2]) # Автоматический выбор типа print(x.dtype) # Prints "int64" x = np.array([1.0, 2.0]) # Автоматический выбор типа print(x.dtype) # Prints "float64" x = np.array([1, 2], dtype=np.int64) # Принудительное выставление типа print(x.dtype) # Prints "int64"
int32 float64 int64
5. Математические операции
К массивам (матрицам) можно применять известные вам математические операции. Следут понимать, что при этом у элементов должны быть схожие размерности. Поведение в случае не совпадения размерностей хорошо описанно в документации numpy.
x = np.array([[1,2],[3,4]], dtype=np.float64) y = np.array([[5,6],[7,8]], dtype=np.float64) arr = np.array([1, 2])
# Сложение происходит поэлеметно # [[ 6.0 8.0] # [10.0 12.0]] print(x + y) print() print(np.add(x, y)) print('С числом') print(x + 1) print('C массивом другой размерности') print(x + arr)
[[ 6. 8.] [10. 12.]] [[ 6. 8.] [10. 12.]] С числом [[2. 3.] [4. 5.]] C массивом другой размерности [[2. 4.] [4. 6.]]
# Вычитание print(x - y) print(np.subtract(x, y))
[[-4. -4.] [-4. -4.]] [[-4. -4.] [-4. -4.]]
# Деление # [[ 0.2 0.33333333] # [ 0.42857143 0.5 ]] print(x / y) print(np.divide(x, y))
[[0.2 0.33333333] [0.42857143 0.5 ]] [[0.2 0.33333333] [0.42857143 0.5 ]]
# Другие функции # [[ 1. 1.41421356] # [ 1.73205081 2. ]] print(np.sqrt(x))
[[1. 1.41421356] [1.73205081 2. ]]
6. Умножение матриц и столбцов
Напоминание теории. Операция умножения определена для двух матриц, таких что число столбцов первой равно числу строк второй.
Пусть матрицы A и B таковы, что A ∈ ℝ n×k и B ∈ ℝ k×m . Произведением матриц A и B называется матрица C , такая что cij = ∑ k r = 1 airbrj , где cij — элемент матрицы C , стоящий на пересечении строки с номером i и столбца с номером j .
В NumPy произведение матриц вычисляется с помощью функции numpy.dot(a, b, . ) или с помощью метода array1.dot(array2), где array1 и array2 — перемножаемые матрицы.
a = np.array([[1, 0], [0, 1]]) b = np.array([[4, 1], [2, 2]]) r1 = np.dot(a, b) r2 = a.dot(b)
print ("Матрица A:\n", a) print ("Матрица B:\n", b) print ("Результат умножения функцией:\n", r1) print ("Результат умножения методом:\n", r2)
Матрица A: [[1 0] [0 1]] Матрица B: [[4 1] [2 2]] Результат умножения функцией: [[4 1] [2 2]] Результат умножения методом: [[4 1] [2 2]]
Матрицы в NumPy можно умножать и на векторы:
c = np.array([1, 2]) r3 = b.dot(c)
print ("Матрица:\n", b) print ("Вектор:\n", c) print ("Результат умножения:\n", r3)
Матрица: [[4 1] [2 2]] Вектор: [1 2] Результат умножения: [6 6]
Обратите внимание: операция * производит над матрицами покоординатное умножение, а не матричное!
r = a * b
print ("Матрица A:\n", a) print ("Матрица B:\n", b) print ("Результат покоординатного умножения через операцию умножения:\n", r)
Матрица A: [[1 0] [0 1]] Матрица B: [[4 1] [2 2]] Результат покоординатного умножения через операцию умножения: [[4 0] [0 2]]
Более подробно о матричном умножении в NumPy см. документацию.
7. Объединение массивов
Массивы можно Объединенять. Есть горизонтальное и вертикальное объединение.
a = np.floor(10*np.random.random((2,2))) b = np.floor(10*np.random.random((2,2))) print(a) print(b) print() print(np.vstack((a,b))) print() print(np.hstack((a,b)))
[[4. 0.] [1. 4.]] [[9. 7.] [2. 6.]] [[4. 0.] [1. 4.] [9. 7.] [2. 6.]] [[4. 0. 9. 7.] [1. 4. 2. 6.]]
Массивы можно переформировать при помощи метода, который задает новый многомерный массив. Следуя следующему примеру, мы переформатируем одномерный массив из десяти элементов во двумерный массив, состоящий из пяти строк и двух столбцов:
a = np.array(range(10), float) print(a) print() # Превратим в матрицу a = a.reshape((5, 2)) print(a) print() # Вернем обратно print(a.flatten()) # Другой вариант print(a.reshape((-1))) # Превратим в марицу (9, 1) print(a.reshape((-1, 1))) # Превратим в марицу (1, 9) print(a.reshape((1, -1)))
[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] [[0. 1.] [2. 3.] [4. 5.] [6. 7.] [8. 9.]] [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] [[0.] [1.] [2.] [3.] [4.] [5.] [6.] [7.] [8.] [9.]] [[0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]]
Задания: (Блок 1)
Задание 1:
Решите без использования циклов средставми NumPy (каждый пункт решается в 1-2 строчки)
- Создайте вектор с элементами от 12 до 42
- Создайте вектор из нулей длины 12, но его пятый елемент должен быть равен 1
- Создайте матрицу (3, 3), заполненую от 0 до 8
- Найдите все положительные числа в np.array([1,2,0,0,4,0])
- Умножьте матрицу размерности (5, 3) на (3, 2)
- Создайте матрицу (10, 10) так, чтобы на границе были 0, а внтури 1
- Создайте рандомный вектор и отсортируйте его
- Каков эквивалент функции enumerate для numpy массивов?
- *Создайте рандомный вектор и выполните нормализацию столбцов (из каждого столбца вычесть среднее этого столбца, из каждого столбца вычесть sd этого столбца)
- *Для заданного числа найдите ближайший к нему элемент в векторе
- *Найдите N наибольших значений в векторе
# ваш код здесь
Задание 2:
Напишите полностью векторизованный вариант
Дан трёхмерный массив, содержащий изображение, размера (height, width, numChannels), а также вектор длины numChannels. Сложить каналы изображения с указанными весами, и вернуть результат в виде матрицы размера (height, width). Считать реальное изображение можно при помощи функции scipy.misc.imread (если изображение не в формате png, установите пакет pillow: conda install pillow). Преобразуйте цветное изображение в оттенки серого, использовав коэффициенты np.array([0.299, 0.587, 0.114]).
# ваш код здесь
8. Транспонирование матриц
Напоминание теории. Транспонированной матрицей A T называется матрица, полученная из исходной матрицы A заменой строк на столбцы. Формально: элементы матрицы A T определяются как a T ij = aji , где a T ij — элемент матрицы A T , стоящий на пересечении строки с номером i и столбца с номером j .
В NumPy транспонированная матрица вычисляется с помощью функции numpy.transpose() или с помощью метода array.T, где array — нужный двумерный массив.
a = np.array([[1, 2], [3, 4]]) b = np.transpose(a) c = a.T
print ("Матрица:\n", a) print ("Транспонирование функцией:\n", b) print ("Транспонирование методом:\n", c)
Матрица: [[1 2] [3 4]] Транспонирование функцией: [[1 3] [2 4]] Транспонирование методом: [[1 3] [2 4]]
В следующих разделах активно используется модуль numpy.linalg, реализующий некоторые приложения линейной алгебры. Более подробно о функциях, описанных ниже, и различных других функциях этого модуля можно посмотреть в его документации.
9. Определитель матрицы
Напоминание теории. Для квадратных матриц существует понятие определителя.
Пусть A — квадратная матрица. Определителем (или детерминантом) матрицы A ∈ ℝ n×n назовем число
detA = ∑ α1, α2, …, αn ( − 1) N(α1, α2, …, αn) ⋅aα11⋅⋅⋅aαnn,
где α1, α2, …, αn — перестановка чисел от 1 до n , N(α1, α2, …, αn) — число инверсий в перестановке, суммирование ведется по всем возможным перестановкам длины n .
Не стоит расстраиваться, если это определение понятно не до конца — в дальнейшем в таком виде оно не понадобится.
Например, для матрицы размера 2×2 получается:
det ⎛ ⎜ ⎝ a11 a12 a21 a22 ⎞ ⎟ ⎠ = a11a22 − a12a21
Вычисление определителя матрицы по определению требует порядка n! операций, поэтому разработаны методы, которые позволяют вычислять его быстро и эффективно.
В NumPy определитель матрицы вычисляется с помощью функции numpy.linalg.det(a), где a — исходная матрица.
a = np.array([[1, 2, 1], [1, 1, 4], [2, 3, 6]], dtype=np.float32) det = np.linalg.det(a)
print ("Матрица:\n", a) print ("Определитель:\n", det)
Матрица: [[1. 2. 1.] [1. 1. 4.] [2. 3. 6.]] Определитель: -1.0
Рассмотрим одно интересное свойство определителя. Пусть у нас есть параллелограмм с углами в точках (0, 0), (c, d), (a + c, b + d), (a, b) (углы даны в порядке обхода по часовой стрелке). Тогда площадь этого параллелограмма можно вычислить как модуль определителя матрицы ⎛ ⎜ ⎝ a c b d ⎞ ⎟ ⎠ . Похожим образом можно выразить и объем параллелепипеда через определитель матрицы размера 3×3 .
10. Ранг матрицы
Напоминание теории. Рангом матрицы A называется максимальное число линейно независимых строк (столбцов) этой матрицы.
В NumPy ранг матрицы вычисляется с помощью функции numpy.linalg.matrix_rank(M, tol=None), где M — матрица, tol — параметр, отвечающий за некоторую точность вычисления. В простом случае можно его не задавать, и функция сама определит подходящее значение этого параметра.
a = np.array([[1, 2, 3], [1, 1, 1], [2, 2, 2]]) r = np.linalg.matrix_rank(a)
print ("Матрица:\n", a) print ("Ранг матрицы:", r)
Матрица: [[1 2 3] [1 1 1] [2 2 2]] Ранг матрицы: 2
С помощью вычисления ранга матрицы можно проверять линейную независимость системы векторов.
Допустим, у нас есть несколько векторов. Составим из них матрицу, где наши векторы будут являться строками. Понятно, что векторы линейно независимы тогда и только тогда, когда ранг полученной матрицы совпадает с числом векторов. Приведем пример:
a = np.array([1, 2, 3]) b = np.array([1, 1, 1]) c = np.array([2, 3, 5]) m = np.array([a, b, c])
print (np.linalg.matrix_rank(m) == m.shape[0])
True
11. Системы линейных уравнений
Напоминание теории. Системой линейных алгебраических уравнений называется система вида Ax = b , где A ∈ ℝ n×m , x ∈ ℝ m×1 , b ∈ ℝ n×1 . В случае квадратной невырожденной матрицы A решение системы единственно.
В NumPy решение такой системы можно найти с помощью функции numpy.linalg.solve(a, b), где первый аргумент — матрица A , второй — столбец b .
a = np.array([[3, 1], [1, 2]]) b = np.array([9, 8]) x = np.linalg.solve(a, b)
print ("Матрица A:\n", a) print ("Вектор b:\n", b) print ("Решение системы:\n", x)
Матрица A: [[3 1] [1 2]] Вектор b: [9 8] Решение системы: [2. 3.]
Убедимся, что вектор x действительно является решением системы:
print (a.dot(x))
Бывают случаи, когда решение системы не существует. Но хотелось бы все равно “решить” такую систему. Логичным кажется искать такой вектор x , который минимизирует выражение ‖ Ax − b ‖ 2 — так мы приблизим выражение Ax к b .
В NumPy такое псевдорешение можно искать с помощью функции numpy.linalg.lstsq(a, b, . ), где первые два аргумента такие же, как и для функции numpy.linalg.solve(). Помимо решения функция возвращает еще три значения, которые нам сейчас не понадобятся.
a = np.array([[0, 1], [1, 1], [2, 1], [3, 1]]) b = np.array([-1, 0.2, 0.9, 2.1]) x, res, r, s = np.linalg.lstsq(a, b, rcond=None)
print ("Матрица A:\n", a) print ("Вектор b:\n", b) print ("Псевдорешение системы:\n", x)
Матрица A: [[0 1] [1 1] [2 1] [3 1]] Вектор b: [-1. 0.2 0.9 2.1] Псевдорешение системы: [ 1. -0.95]
12. Обращение матриц
Напоминание теории. Для квадратных невырожденных матриц определено понятие обратной матрицы.
Пусть A — квадратная невырожденная матрица. Матрица A − 1 называется обратной матрицей к A , если
AA − 1 = A − 1 A = I,
где I — единичная матрица.
В NumPy обратные матрицы вычисляются с помощью функции numpy.linalg.inv(a), где a — исходная матрица.
a = np.array([[1, 2, 1], [1, 1, 4], [2, 3, 6]], dtype=np.float32) b = np.linalg.inv(a)
print ("Матрица A:\n", a) print ("Обратная матрица к A:\n", b) print ("Произведение A на обратную должна быть единичной:\n", a.dot(b))
Матрица A: [[1. 2. 1.] [1. 1. 4.] [2. 3. 6.]] Обратная матрица к A: [[ 6. 9. -7.] [-2. -4. 3.] [-1. -1. 1.]] Произведение A на обратную должна быть единичной: [[1. 0. 0.] [0. 1. 0.] [0. 0. 1.]]
13. Собственные числа и собственные вектора матрицы
Напоминание теории. Для квадратных матриц определены понятия собственного вектора и собственного числа.
Пусть A — квадратная матрица и A ∈ ℝ n×n . Собственным вектором матрицы A называется такой ненулевой вектор x ∈ ℝ n , что для некоторого λ ∈ ℝ выполняется равенство Ax = λx . При этом λ называется собственным числом матрицы A . Собственные числа и собственные векторы матрицы играют важную роль в теории линейной алгебры и ее практических приложениях.
В NumPy собственные числа и собственные векторы матрицы вычисляются с помощью функции numpy.linalg.eig(a), где a — исходная матрица. В качестве результата эта функция выдает одномерный массив w собственных чисел и двумерный массив v, в котором по столбцам записаны собственные вектора, так что вектор v[:, i] соотвествует собственному числу w[i].
a = np.array([[-1, -6], [2, 6]]) w, v = np.linalg.eig(a)
print ("Матрица A:\n", a) print ("Собственные числа:\n", w) print ("Собственные векторы:\n", v)
Матрица A: [[-1 -6] [ 2 6]] Собственные числа: [2. 3.] Собственные векторы: [[-0.89442719 0.83205029] [ 0.4472136 -0.5547002 ]]
Обратите внимание: у вещественной матрицы собственные значения или собственные векторы могут быть комплексными.
14. Расстояния между векторами
Вспомним некоторые нормы, которые можно ввести в пространстве ℝ n , и рассмотрим, с помощью каких библиотек и функций их можно вычислять в NumPy.
p-норма
p-норма (норма Гёльдера) для вектора x = (x1, …, xn) ∈ ℝ n вычисляется по формуле:
‖ x ‖ p = ( n ∑ i = 1 | xi | p ) 1 ⁄ p , p ≥ 1.
В частных случаях при: * p = 1 получаем ℓ1 норму * p = 2 получаем ℓ2 норму
Далее нам понабится модуль numpy.linalg, реализующий некоторые приложения линейной алгебры. Для вычисления различных норм мы используем функцию numpy.linalg.norm(x, ord=None, . ), где x — исходный вектор, ord — параметр, определяющий норму (мы рассмотрим два варианта его значений — 1 и 2). Импортируем эту функцию:
from numpy.linalg import norm
ℓ1 норма
ℓ1 норма (также известная как манхэттенское расстояние) для вектора x = (x1, …, xn) ∈ ℝ n вычисляется по формуле:
‖ x ‖ 1 = n ∑ i = 1 | xi | .
Ей в функции numpy.linalg.norm(x, ord=None, . ) соответствует параметр ord=1.
a = np.array([1, 2, -3]) print('Вектор a:', a)
Вектор a: [ 1 2 -3]
print('L1 норма вектора a:\n', norm(a, ord=1))
L1 норма вектора a: 6.0
ℓ2 норма
ℓ2 норма (также известная как евклидова норма) для вектора x = (x1, …, xn) ∈ ℝ n вычисляется по формуле:
‖ x ‖ 2 = √ ( n ∑ i = 1 ( xi ) 2 ) .
Ей в функции numpy.linalg.norm(x, ord=None, . ) соответствует параметр ord=2.
print ('L2 норма вектора a:\n', norm(a, ord=2))
L2 норма вектора a: 3.7416573867739413
Более подробно о том, какие еще нормы (в том числе матричные) можно вычислить, см. документацию.
15. Расстояния между векторами
Для двух векторов x = (x1, …, xn) ∈ ℝ n и y = (y1, …, yn) ∈ ℝ n ℓ1 и ℓ2 раccтояния вычисляются по следующим формулам соответственно:
ρ1 ( x, y ) = ‖ x − y ‖ 1 = n ∑ i = 1 | xi − yi |
ρ2 ( x, y ) = ‖ x − y ‖ 2 = √ ( n ∑ i = 1 ( xi − yi ) 2 ) .
a = np.array([1, 2, -3]) b = np.array([-4, 3, 8]) print ('Вектор a:', a) print ('Вектор b:', b)
Вектор a: [ 1 2 -3] Вектор b: [-4 3 8]
print ('L1 расстояние между векторами a и b:\n', norm(a - b, ord=1)) print ('L2 расстояние между векторами a и b:\n', norm(a - b, ord=2))
L1 расстояние между векторами a и b: 17.0 L2 расстояние между векторами a и b: 12.12435565298214
16. Скалярное произведение и угол между векторами
a = np.array([0, 5, -1]) b = np.array([-4, 9, 3]) print ('Вектор a:', a) print ('Вектор b:', b)
Вектор a: [ 0 5 -1] Вектор b: [-4 9 3]
Скалярное произведение в пространстве ℝ n для двух векторов x = (x1, …, xn) и y = (y1, …, yn) определяется как:
⟨x, y⟩ = n ∑ i = 1 xiyi.
Длиной вектора x = (x1, …, xn) ∈ ℝ n называется квадратный корень из скалярного произведения, то есть длина равна евклидовой норме вектора:
| x | = √ ( ⟨x, x⟩ ) = √ ( n ∑ i = 1 x 2 i ) = ‖ x ‖ 2.
Теперь, когда мы знаем расстояние между двумя ненулевыми векторами и их длины, мы можем вычислить угол между ними через скалярное произведение:
⟨x, y⟩ = | x | |y|cos(α) ⟹ cos(α) = ( ⟨x, y⟩ )/( | x | |y| ) ,
где α ∈ [0, π] — угол между векторами x и y .
cos_angle = np.dot(a, b) / norm(a) / norm(b) print ('Косинус угла между a и b:', cos_angle) print ('Сам угол:', np.arccos(cos_angle))
Косинус угла между a и b: 0.8000362836474323 Сам угол: 0.6434406336093618
17. Комплексные числа в питоне
Напоминание теории. Комплексными числами называются числа вида x + iy , где x и y — вещественные числа, а i — мнимая единица (величина, для которой выполняется равенство i 2 = − 1 ). Множество всех комплексных чисел обозначается буквой ℂ (подробнее про комплексные числа см. википедию).
В питоне комплескные числа можно задать следующим образом (j обозначает мнимую единицу):
a = 3 + 2j b = 1j
print ("Комплексное число a:\n", a) print ("Комплексное число b:\n", b)
Комплексное число a: (3+2j) Комплексное число b: 1j
С комплексными числами в питоне можно производить базовые арифметические операции так же, как и с вещественными числами:
c = a * a d = a / (4 - 5j)
print ("Комплексное число c:\n", c) print ("Комплексное число d:\n", d)
Комплексное число c: (5+12j) Комплексное число d: (0.0487804878048781+0.5609756097560976j)
Задания: (Блок 2)
Задание 3:
Рассмотрим сложную математическую функцию на отрезке [1, 15]:
f(x) = sin(x / 5) * exp(x / 10) + 5 * exp(-x / 2)
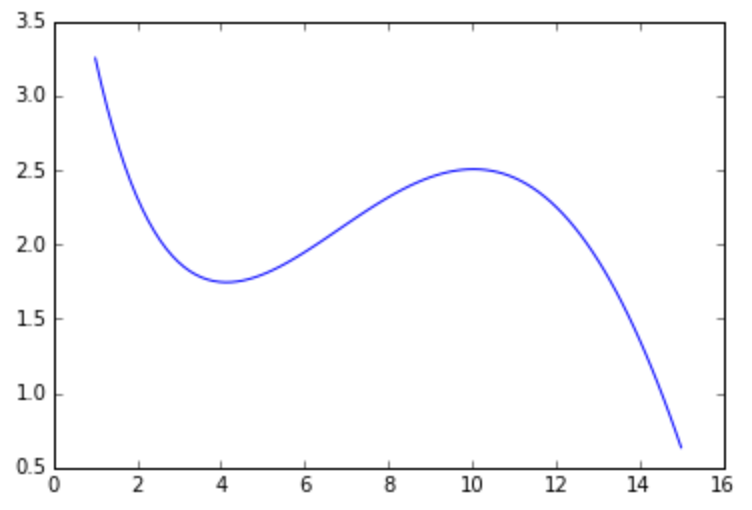
Она может описывать, например, зависимость оценок, которые выставляют определенному сорту вина эксперты, в зависимости от возраста этого вина. Мы хотим приблизить сложную зависимость с помощью функции из определенного семейства. В этом задании мы будем приближать указанную функцию с помощью многочленов.
Как известно, многочлен степени n (то есть w0 + w1x + w2x 2 + … + wnx n ) однозначно определяется любыми n + 1 различными точками, через которые он проходит. Это значит, что его коэффициенты w0 , … wn можно определить из следующей системы линейных уравнений:
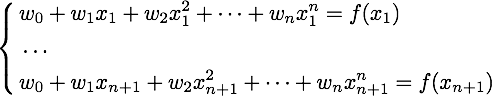
где через x1, . xn, xn + 1 обозначены точки, через которые проходит многочлен, а через f(x1), . f(xn), f(xn + 1) — значения, которые он должен принимать в этих точках.
Воспользуемся описанным свойством, и будем находить приближение функции многочленом, решая систему линейных уравнений.
- Сформируйте систему линейных уравнений (то есть задайте матрицу коэффициентов A и свободный вектор b) для многочлена первой степени, который должен совпадать с функцией f в точках 1 и 15. Решите данную систему с помощью функции scipy.linalg.solve. Нарисуйте функцию f и полученный многочлен. Хорошо ли он приближает исходную функцию?
- Повторите те же шаги для многочлена второй степени, который совпадает с функцией f в точках 1, 8 и 15. Улучшилось ли качество аппроксимации?
- Повторите те же шаги для многочлена третьей степени, который совпадает с функцией f в точках 1, 4, 10 и 15. Хорошо ли он аппроксимирует функцию? Коэффициенты данного многочлена (четыре числа в следующем порядке: w_0, w_1, w_2, w_3) являются ответом на задачу. Округлять коэффициенты не обязательно, но при желании можете произвести округление до второго знака (т.е. до числа вида 0.42)
Сайт построен с использованием Pelican. За основу оформления взята тема от Smashing Magazine. Исходные тексты программ, приведённые на этом сайте, распространяются под лицензией GPLv3, все остальные материалы сайта распространяются под лицензией CC-BY.