Установка Beautifulsoup и примеры
Разберем как производится установка beautifulsoup — библиотеки, которая позволяет работать с содержимым веб-страниц в интернете, извлекая из больших объемов структурированной информации нужную. Используется для парсинга.
Python beautifulsoup: установка и использование, примеры
Прежде всего, создадим виртуальное окружение. Назвать его можно, например, parser
Подробнее о виртуальном окружении и необходимых для его работы пакетах
(parser) admin@desktop:/
В терминале после активации появляется указанное ранее имя.
Как установить beautifulsoup python
BeautifulSoup является частью библиотеки bs4, парсер также требует requests, все устанавливается через pip из окружения
Successfully installed certifi-2018.8.24 chardet-3.0.4 idna-2.7 requests-2.19.1 urllib3-1.23 beautifulsoup4-4.6.3 bs4-0.0.1
Пример вывода на скриншоте:
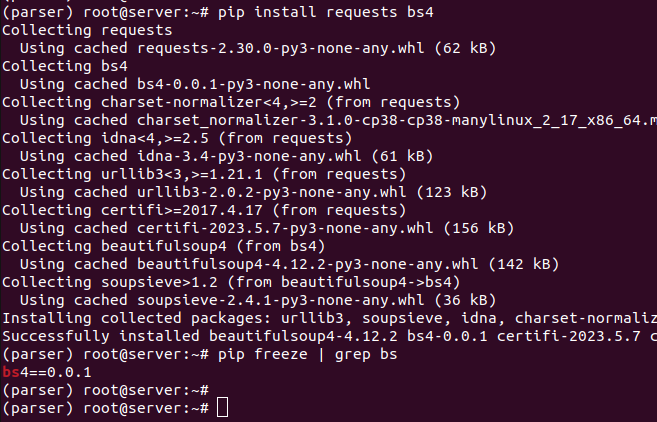
Установка завершена, теперь можно перейти к созданию скрипта
import requests from bs4 import BeautifulSoup page = requests.get('https://yandex.ru') soup = BeautifulSoup(page.text, 'html.parser')
Создается объект BeautifulSoup, в скобках указываются два параметра.
Первый — результат применения метода text к содержимому переменной page. Переменная page содержит текст страницы, путь к которой задан.
Второй аргумент — html.parser
С данными далее можно производить любые манипуляции.
Пример форматирования результата полученного с помощью BeautifulSoup
Добавим в скрипт такие строки
city = soup.find(class_='geolink__reg') print (city.prettify())
Вызов скрипта из консоли
Скрипт спарсил главную страницу Яндекса и получил содержимое тега с классом geolink__reg из HTML кода. Класс выбран для демонстрации при визуальном анализе исходного кода (CTRL+U в браузере).
В данном случае в нем находится город, определенный при помощи geoip
Здесь используется метод prettify, который позволяет создавать отформатированное дерево тегов с результатами поиска.
Теперь закомментируем последний print и вместо него
city = soup.find(class_='geolink__reg') #print (city.prettify) print (city.contents[0])
Если вызвать скрипт сейчас можно увидеть, что он отдает только сам контент, в данном случае — имя города.
Екатеринбург
Это достигнуто использованием contents[0], все лишние тэги удалены. Результаты парсинга можно сохранять в csv файлы или обычные текстовые документы. Записывать можно не все, а выбирать только нужное содержимое работая с ним как с текстом.
Скрипты с BeautifulSoup можно запускать по какому-то расписанию по системному планировщику задач CRON
Туториал по библиотеке BeautifulSoup4
Парсеры — это программы, которые скачивают из интернета странички и разбирают их на составляющие: заголовок, картинка, текст… С помощью него можно выкачать с сайта гигабайты полезной информации. Библиотека BeautifulSoup4 как раз предназначена для парсинга.
В этой статье вы узнаете как распарсить сайт Франка Сонненберга. Цель: по ссылке на пост вытащить его название, текст и картинку.
Франк Сонненберг — известный американский писатель и коуч. За свои книги он попал в “Топ 100 Американских мыслителей”, а его блог принадлежит списку “Лучшие блоги о лидерстве 21 века”.
Прежде чем начинать…
Для прохождения этого туториала вам понадобятся 3 библиотеки:
$ pip install requests BeautifulSoup4 lxml Получить страничку поста
Будем парсить пост “Are You Grateful?”. Чтобы распарсить HTML-страничку с постом, сначала нужно её скачать. Это можно сделать с помощью requests , вот статья об этой библиотеке.
import requests url = 'https://www.franksonnenbergonline.com/blog/are-you-grateful/' response = requests.get(url) response.raise_for_status() print(response.text) Здесь мы просто сделали запрос по ссылке и получили в ответ огромный HTML. Начинаться он будет примерно так:
DOCTYPE html> html lang="en-US"> head > meta charset="UTF-8" /> meta name="viewport" content="width=device-width, initial-scale=1" /> . Парсинг поста
У вас есть HTML страничка, но как достать оттуда заголовок поста, картинку и текст? Наконец, на сцену выходит BeautifulSoup. Сейчас вы получили HTML из response.text , но это просто строка с HTML кодом. Для работы с библиотекой BeautifulSoup нужно сделать из этой строки HTML-суп:
from bs4 import BeautifulSoup soup = BeautifulSoup(response.text, 'lxml') print(soup.prettify()) В Python-коде суп — это новый объект с кучей возможностей. Например, теперь можно вывести HTML красиво, с отступами, с помощью метода soup.prettify() :
DOCTYPE html> html lang="en-US"> head> meta charset="utf-8"/> meta content="width=device-width, initial-scale=1" name="viewport"/> title> Are You Grateful? . Супом он называется исторически, вот статья об этом термине. Если вкратце, то на самом деле верстальщики иногда косячат и, например, забывают закрывать теги или оставляют какие-нибудь неисправности. Такой код на HTML стали называть tag soup . Браузеры умеют самостоятельно исправлять какие-то огрехи и делать из такого “супа” нормальный, рабочий HTML. Но если вы скачиваете страничку через requests , то браузер тут ни при чём, и вы получите такой HTML, какой написали верстальщики сайта, со всеми его ошибками.
Для этого и нужна библиотека lxml , она подправит мелкие недочёты, и с ней BeautifulSoup справится даже с очень плохой вёрсткой. В этой строчке вы как раз говорите библиотеке BeautifulSoup использовать lxml :
soup = BeautifulSoup(response.text, 'lxml') Заголовок поста
Заголовок поста можно легко найти методом супа .find() . Для начала нужно узнать в какой тег этот заголовок обёрнут. В этом помогут инструменты разработчика:
Итак, тег h1 . Вот что вернёт метод .find() :
print(soup.find('h1')) #
Это тоже суп, но уже не со всей HTML-страницей, а только с этим тегом и тегами внутри него. Заголовка поста тут нет: пост называется Are You Grateful? , а такого текста в этом теге нет. Похоже, что это не тот тег , который вы искали. Их на странице несколько и BeautifulSoup4 выдал первый, который нашёл. Это тег , который находится в самом верху страницы:
Как же найти заголовок поста, а не страницы? Можно уточнить запрос: заголовок поста лежит в теге , а тот — в :
Давайте попробуем такой запрос:
title_tag = soup.find('main').find('header').find('h1') print(title_tag) # Are You Grateful?
Тег нашли, а как достать его текст? Всё очень просто:
title_tag = soup.find('main').find('header').find('h1') title_text = title_tag.text print(title_text) # Are You Grateful? Победа, вы добрались до заголовка поста!
Картинка поста
Картинку можно найти так же: это единственный тег внутри тега . Но давайте попробуем другой подход, найдём её по классу. У картинки есть классы:
У картинки есть 3 класса, они перечислены через пробел:
attachment-post-image size-post-image wp-post-image Класс attachment-post-image переводится как “Картинка поста”, а значит наверняка он есть только у картинок поста. Вот как найти тег img , у которого есть такой класс:
soup.find('img', class_='attachment-post-image') # ![]() # fortunate, things to be grateful for, why you should be grateful, Frank Sonnenberg" class token comment"># size-post-image wp-post-image" height="400" sizes="(max-width: 800px) 100vw, 800px" # src="https://www.franksonnenbergonline.com/wp-content/uploads/2019/10/image_are-you-grateful.jpg" ...
# fortunate, things to be grateful for, why you should be grateful, Frank Sonnenberg" class token comment"># size-post-image wp-post-image" height="400" sizes="(max-width: 800px) 100vw, 800px" # src="https://www.franksonnenbergonline.com/wp-content/uploads/2019/10/image_are-you-grateful.jpg" ... Тот же .find() , только указали параметр class_ . Нижнее подчёркивание разработчики библиотеки добавили для того, чтобы не было пересечения со словом class из Python, которое используется для создания классов.
Осталось достать адрес картинки, он лежит в аргументе src :
soup.find('img', class_='attachment-post-image')['src'] # https://www.franksonnenbergonline.com/wp-content/uploads/2019/10/image_are-you-grateful.jpg Домашнее задание
Осталось спарсить текст поста. Сделать это можно одним из способов выше: по классу или тегам, с помощью метода find .
Попробуйте бесплатные уроки по Python
Получите крутое код-ревью от практикующих программистов с разбором ошибок и рекомендациями, на что обратить внимание — бесплатно.
Переходите на страницу учебных модулей «Девмана» и выбирайте тему.
Установка красивого супа
Резюме: Для установки BeautifulSoup в Windows используйте команду: PIP Установите BeautifulSoup4. Чтобы установить его в Linux, используйте команду: sudo apt-get install python3-bs4. Цель: В этом руководстве мы обсудим, как установить BeautioSoup? Поскольку BeautifulSoup не является стандартной библиотекой Python, нам нужно установить его, прежде чем мы сможем использовать его … Установка красивого супа Подробнее »
- Автор записи Автор: Shubham Sayon
- Дата записи 03.09.2021
Автор оригинала: Shubham Sayon.
Резюме: Чтобы установить BeautifulSoup в Windows Используйте команду: PIP Установите BeautifulSoup4 Отказ Чтобы установить его в Linux, используйте команду: sudo apt-get install python3-bs4 Отказ
Цель : В этом руководстве мы обсудим, как установить BeautifulSoup ?
Поскольку BeautifulSoup не является стандартной библиотекой Python, нам нужно установить его, прежде чем мы сможем использовать его, чтобы соскрести сайты. Следовательно, мы посмотрим на шаги для установки пакета Boysuous 4 (также называемого BS4), а также обсуждают некоторые из проблем, которые придумывают после установки.
Примечание: Текущий релиз это Красивый суп 4.9.3 (3 октября 2020 года).
❂ Установка красивыхsoup В машине Linux
❖ Платформа: Debian или Ubuntu
Если вы используете Python в ОС на основе Debian или Ubuntu, вам необходимо установить красивый суп с помощью менеджера системного пакета, используя следующую команду:
✻ для Python 2.x.
$sudo apt-get install python-bs4
✻ для Python 3.x.
$sudo apt-get install python3-bs4
Если вы не хотите использовать диспетчер пакетов системы, вы можете использовать easy_install или пипс установить BS4.
✻ Команда для установки BS4 Использование easy_install :
$easy_install beautifulsoup4
✻ Команда для установки BS4 Использование Пип :
$pip install beautifulsoup4
# Примечание: Если вы используете Python3, вам может потребоваться установить easy_install3. или PIP3 соответственно, прежде чем вы сможете их использовать.
❖ Платформа: Windows
Установка BS4 В Windows является одним из шагов и очень прост. Используйте следующую команду, чтобы установить его, используя интерфейс командной строки.
pip install beautifulsoup4
❂ Некоторые распространенные проблемы после установки
Вы можете столкнуться с ошибкой, если установлена неправильная версия. Давайте посмотрим на причину ошибок!
❖ Ошибка : ImportError «Нет модуля по имени HTMLParser»
Причина: Ошибка возникает, потому что вы используете версию Python 2 в Python 3.
❖ Ошибка : ImportError «Нет модуля по имени HTML.Parser»
Причина: Ошибка возникает, потому что вы используете версию Python 3 в Python 2.
Решение: Удалите существующую установку и переустановите BeautifulSoup.
❖ Ошибка .: SyntaxError “Неверный синтаксис” на линии «[документ]»
Решение: Конвертировать Python 2 версии кода в Python 3 с помощью:
- Установка пакета –
- python3 setup.py. установить
- 2To3-3,2 -W BS4
❂ Установка парсера
Красивый суп поддерживает Parser HTML по умолчанию, которое включено в стандартную библиотеку Python. Однако он также поддерживает другую внешнюю или стороннюю парсеров Python, как показано в таблице ниже:
Анализатор Типичное использование Преимущества Недостатки Python HTML.Parser. BeautifulSoupsup (Markup, «HTML.Parser») Аккумуляторы в комплекте удерживают Speedlenient (как на Python 2.7.3 и 3.2.) Не так быстро, как lxml, менее снисходительно, чем html5lib. HTML Parser LXML CountrySoup (разметки, “lxml”) Очень Fastlenient Внешняя зависимость XML Parser LXML Beautifulsoup (Markup, «LXML-XML») BeautifulSoup (Markup, «XML») Очень быстро Только в настоящее время поддерживается XML Parser Внешняя зависимость HTML5LIB BeautifulSoup (Markup, «HTML5LIB») Чрезвычайно lenientparses страниц так же, как веб-браузер делает Valid HTML5 Очень замедленная зависимость Python Используйте следующие команды для установки lxml или HTML5LIB парсер,
Linux:
$apt-get install python-lxml $apt-get insall python-html5lib
Windows:
$pip install lxml $pip install html5lib
Заключение
С этим мы дойдем до конца этого хрустящего урока о том, как установить Beautifulsoup библиотека. Пожалуйста, не стесняйтесь следить за шагами и установить его в свою систему. Если вы хотите узнать, как использовать библиотеку BeautifulSoup и Scrape веб-страницу, пожалуйста, следуйте за Это руководство И посмотрите на шаг за шагом руководство, чтобы соскрести свою веб-страницу.
Пожалуйста, подпишитесь и оставайтесь настроенными для более интересных статей!
Куда пойти отсюда?
Достаточно теории, давайте познакомимся!
Чтобы стать успешным в кодировке, вам нужно выйти туда и решать реальные проблемы для реальных людей. Вот как вы можете легко стать шестифункциональным тренером. И вот как вы польские навыки, которые вам действительно нужны на практике. В конце концов, что такое использование теории обучения, что никто никогда не нуждается?
Практические проекты – это то, как вы обостряете вашу пилу в кодировке!
Вы хотите стать мастером кода, сосредоточившись на практических кодовых проектах, которые фактически зарабатывают вам деньги и решают проблемы для людей?
Затем станьте питоном независимым разработчиком! Это лучший способ приближения к задаче улучшения ваших навыков Python – даже если вы являетесь полным новичком.
Присоединяйтесь к моему бесплатным вебинаре «Как создать свой навык высокого дохода Python» и посмотреть, как я вырос на моем кодированном бизнесе в Интернете и как вы можете, слишком от комфорта вашего собственного дома.
Присоединяйтесь к свободному вебинару сейчас!
Я профессиональный Python Blogger и Content Creator. Я опубликовал многочисленные статьи и создал курсы в течение определенного периода времени. В настоящее время я работаю полный рабочий день, и у меня есть опыт в областях, таких как Python, AWS, DevOps и Networking.
Вы можете связаться со мной @:
Читайте ещё по теме:
- Руководство по синтаксическому анализу HTML с помощью BeautifulSoup в Python
- Python не распознается как внутренняя или внешняя команда
- Аргументы командной строки в Python
- Начало работы с сосканием в Python
- Системная команда Python: Как выполнять команды оболочки в Python?
- Краткое введение в пакет SH
- Как установить PIP в Windows?
beautifulsoup4 4.12.2
Beautiful Soup is a library that makes it easy to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms for iterating, searching, and modifying the parse tree.
Quick start
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup("SomebadHTML") >>> print(soup.prettify())
Some bad HTML
>>> soup.find(text="bad") 'bad' >>> soup.i HTML # >>> soup = BeautifulSoup("Somebad XML", "xml") # >>> print(soup.prettify()) Some bad XML Links
- Homepage
- Documentation
- Discussion group
- Development
- Bug tracker
- Complete changelog
Note on Python 2 sunsetting
Beautiful Soup’s support for Python 2 was discontinued on December 31, 2020: one year after the sunset date for Python 2 itself. From this point onward, new Beautiful Soup development will exclusively target Python 3. The final release of Beautiful Soup 4 to support Python 2 was 4.9.3.
Supporting the project
If you use Beautiful Soup as part of your professional work, please consider a Tidelift subscription. This will support many of the free software projects your organization depends on, not just Beautiful Soup.
If you use Beautiful Soup for personal projects, the best way to say thank you is to read Tool Safety, a zine I wrote about what Beautiful Soup has taught me about software development.
Building the documentation
The bs4/doc/ directory contains full documentation in Sphinx format. Run make html in that directory to create HTML documentation.
Running the unit tests
Beautiful Soup supports unit test discovery using Pytest:
$ pytest