Подключение к базе данных PostgreSQL
В этом разделе описывается, как подключиться к базе данных PostgreSQL.
На этой странице
- Базовое подключение
- Подключение с помощью SSL-сертификата
Для подключения к экземпляру БД можно использовать клиентский psql для базового подключения или SSL-соединения. Рекомендуется использовать SSL-соединение.
Для подключения необходимы:
- Привязанный к экземпляру БД внешний IP-адрес.
- Установленный клиент PostgreSQL psql на ECS.
Базовое подключение
- Подключитесь к экземпляру виртуальной машины ECS , где развернут экземпляр RDS.
- Запустите следующую команду для подключения к базе данных RDS:
psql --no-readline -U user> -h host> -p port> -d datastore> -W
- -U — имя пользователя экземпляра базы данных RDS. По умолчанию — root .
- -h — IP-адрес экземпляра первичной БД. Получить этот IP-адрес можно на странице Instance Management , нажав на название экземпляра БД.
- через ECS, то IP-адрес можно найти на вкладке Basic Information разделе Connection Information → Floating IP Address .
- через EIP, то адрес IP будет располагаться на вкладке EIPs .
- -p — использующийся порт для базы данных. По умолчанию значение порта — 5432. Номер порта можно получить на странице Instance Management , нажав на нужный экземпляр RDS и перейдя в раздел Connection Information → Database Port .
- -d — название БД. По умолчанию название будет «postgres».
- -W — запрос пароля, который нужно будет указать при подключении. После запуска этой команды будет запрашиваться пароль.
psql --no-readline -U root -h 192.168.0.44 -p 5432 -d postgres -W
Подключение с помощью SSL-сертификата
- Войдите в консоль управления Advanced.
- Инструкция по входу с помощью личного кабинета Cloud.ru
- Инструкция по входу в консоль для IAM-пользователей
Запустите команду для подключения к экземпляру. В нашем примере используется команда для Linux:
psql --no-readline -h host> -p port> "dbname= user= sslmode=verify-ca sslrootcert="
-h — IP-адрес экземпляра первичной БД. Получить этот IP-адрес можно на странице Instance Management , нажав на название экземпляра БД.
Если подключение осуществляется:
- через ECS, то IP-адрес можно найти на вкладке Basic Information разделе Connection Information → Floating IP Address .
- через EIP, то адрес IP будет располагаться на вкладке EIPs .
Например, чтобы подключиться к экземпляру базы данных через SSL-соединение от имени пользователя root, выполните следующую команду:
psql --no-readline -h 192.168.0.44 -p 5432 "dbname=postgres user=root sslmode=verify-ca sslrootcert=/root/ca.pem" Password:
Если успешно установлено SSL-соединение, то отобразится сообщение:
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Как узнать имя сервера postgresql
График работы: будни с 9:00 до 18:00 Общие вопросы: contact@falcongaze.ru Отдел продаж: sales@falcongaze.ru Техподдержка: support@falcongaze.ru Вопросы партнерства: partner@falcongaze.ru СМИ: pr@falcongaze.ru https://falcongaze.com/ru/
- О DLP-системе
- Что такое DLP-система SecureTower?
- Интерфейс DLP-системы SecureTower
Задачи SecureTower
- Защита от утечек данных по вине сотрудниковКонтроль работы сотрудников на компьютерахАнализ поведения сотрудника на компьютере (UBA)Выявление потенциально-опасных сотрудниковВедение архива бизнес-коммуникацииКонтроль всех каналов коммуникации
- О компанииКонтактыНаши клиентыНаши партнерыСтать партнеромРабота с учебными заведениямиВакансииЛицензии и сертификаты
Документация
- О DLP-системе
- Что такое DLP-система SecureTower?
- Интерфейс DLP-системы SecureTower
Задачи SecureTower
- Защита от утечек данных по вине сотрудниковКонтроль работы сотрудников на компьютерахАнализ поведения сотрудника на компьютере (UBA)Выявление потенциально-опасных сотрудниковВедение архива бизнес-коммуникацииКонтроль всех каналов коммуникации
- О компанииКонтактыНаши клиентыНаши партнерыСтать партнеромРабота с учебными заведениямиВакансииЛицензии и сертификаты
Документация


Руководство администратора
Настройка базы данных PostgreSQL
Для того, чтобы настроить подключение к базе данных под управлением PostgreSQL (версии 9.3 и выше) в окне Настройка базы данных :
- Выберите один из способов настройки подключения к базе данных:
- Для того, чтобы указать реквизиты доступа к базе данных под управлением PostgreSQL, следуйте рекомендациям пункта Реквизиты доступа текущего параграфа .
- Для того, чтобы задать параметры подключения в форме строки подключения, следуйте рекомендациям пункта Строка подключения текущего параграфа.
- Если требуется настроить индексацию базы данных и режим сохранения файлов в базу, выберите вкладку Дополнительные настройки и следуйте рекомендациям пункта Дополнительные настройки подключения.
- После завершения ввода параметров подключения нажмите Проверить подключение в нижнем левом углу окна настроек. Дождитесь успешного завершения проверки (статус подключения
 ). В случае возникновения ошибки соединения с сервером (статус подключения
). В случае возникновения ошибки соединения с сервером (статус подключения  или
или  ), убедитесь, что требуемая база данных установлена на указанном сервере и введенные параметры авторизации верны.
), убедитесь, что требуемая база данных установлена на указанном сервере и введенные параметры авторизации верны.
- Нажмите Создать для добавления базы данных в список используемых Центральным сервером.
Реквизиты доступа
Для того, чтобы настроить доступ к базе данных под управлением PostgreSQL в окне вкладки Реквизиты доступа :
- Укажите название соединения в соответствующем поле ввода.
- В списке СУБД выберите PostgreSQL.
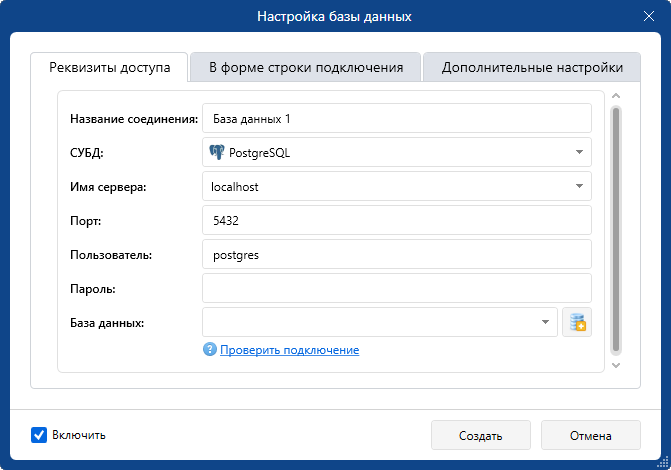

- В поле Имя сервера введите имя сервера, на котором хранится или будет храниться база данных, либо выберите имя ранее подключенного сервера из списка. База данных может быть расположена на локальном компьютере (localhost) или на любом другом компьютере, который будет указан в данном поле.
- Укажите порт, который будет использоваться для подключения к базе данных. По умолчанию установлен номер порта 5432.
- В соответствующих полях введите параметры авторизации пользователя в СУБД: имя пользователя и пароль для доступа к базе данных.
- В поле База данных введите имя базы данных, расположенной на компьютере, указанном в поле Имя сервера , либо выберите в списке ранее добавленную базу данных. Если такая база данных отсутствует, нажмите кнопку , в окне Создать базу данных введите имя новой базы и нажмите Создать .
Рекомендуется использовать средства СУБД для создания новых баз данных. Используйте кодировку UTF-8 при создании базы данных.
Строка подключения
Для того, чтобы задать строку подключения:
- Выберите вкладку В форме строки подключения .
- Введите параметры подключения к базе данных под управлением PostgreSQL в соответствующем поле. Подробнее см. https://postgrespro.ru/docs/postgrespro/9.6/libpq-connect.html#libpq-connstring.
Пример строки подключения Центрального сервера к PostgreSQL с использованием SSL:
port=5432; host=192.168.10.10; user=postgres; password=yourpw; sslmode=require; dbname=db01;
Примечание.
Строка подключения также формируется автоматически на основании результатов заполнения полей вкладки Реквизиты доступа и может быть дополнена при необходимости.
Дополнительные настройки подключения
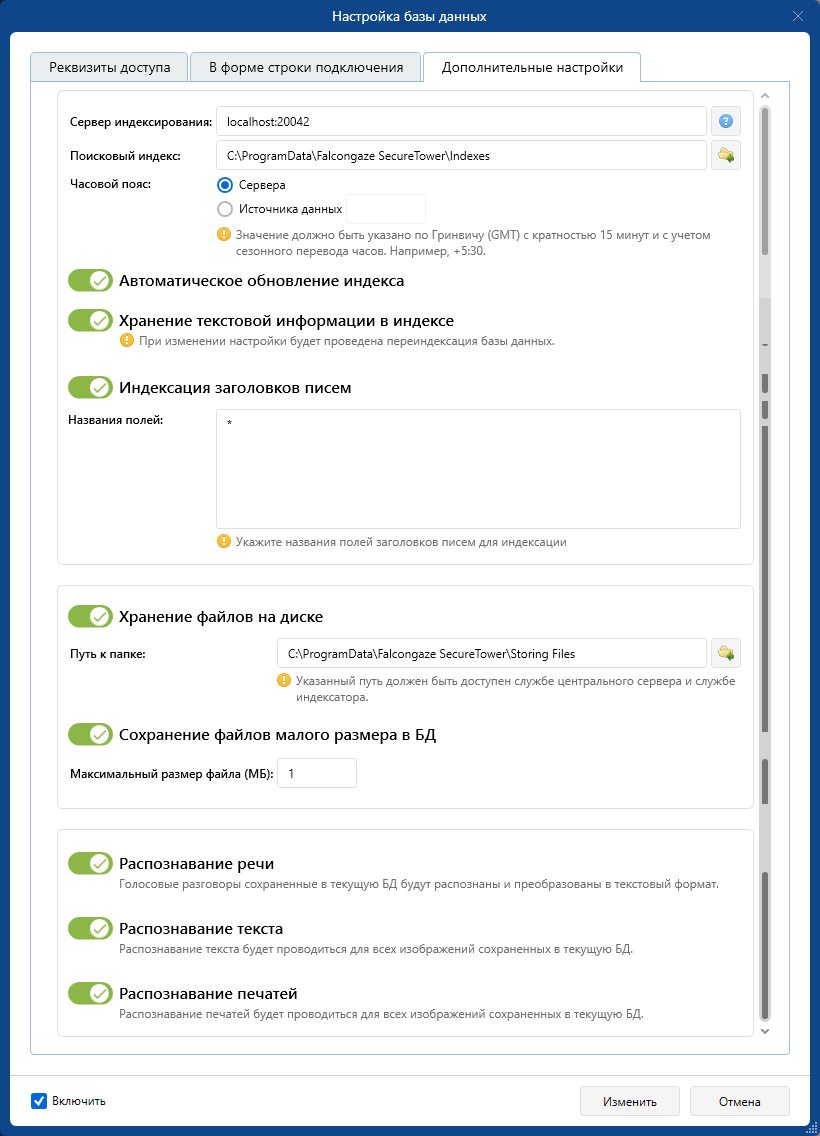
В окне вкладки Дополнительные параметры для просмотра и настройки доступны следующие параметры подключения и работы с базой:
- Имя сервера индексирования в поле Сервер индексирования . Если необходимо использовать сервер, отличный от установленного по умолчанию, введите нужный адрес сервера. Для проверки соединения с сервером нажмите кнопку проверки подключения
 справа от поля и дождитесь успешного завершения проверки (статус
справа от поля и дождитесь успешного завершения проверки (статус  ). В случае возникновения ошибки соединения с сервером, убедитесь, что адрес сервера указан верно и служба сервера запущена.
). В случае возникновения ошибки соединения с сервером, убедитесь, что адрес сервера указан верно и служба сервера запущена.
- Полный путь к поисковому индексу в поле Поисковый индекс . Если необходимо изменить путь к папке индекса, введите нужный путь хранения индекса либо нажмите кнопку обзора и укажите на диске сервера требуемый путь, по которому будут сохраняться файлы поискового индекса.
- Часовой пояс источников данных. По умолчанию система использует часовой пояс Центрального сервера и автоматически учитывает сезонный перевод часов. Если часовые пояса сервера и сети источников данных отличаются, введите часовой пояс сети, данные из которой будут сохраняться в базу. В противном случае время перехвата данных, полученных в дневное время, будет искажено. Часовой пояс должен быть указан по Гринвичу (GMT) с учетом сезонного перевода часов, значение минут должно быть кратно 15. Например, часовой пояс источников данных, расположенных в Индии, указывается как +5:30.
Примечание.
Рекомендуется использовать отдельные базы для хранения данных перехвата сетей с различными часовыми поясами.
Если поле Часовой пояс заполнено, система не учитывает сезонный перевод часов автоматически. При очередном переводе часов скорректируйте значение часового пояса вручную.
- Автоматическое обновление индекса . По умолчанию индекс обновляется автоматически. Если требуется обновлять индекс вручную, установите переключатель в неактивное положение. Ручное обновление индекса производится в настройках статистики базы данных.
- Хранение текстовой информации в индексе . При отключении данной опции поиск по банкам цифровых отпечатков будет потреблять больше ресурсов и занимать больше времени.
- Индексация заголовков писем . По умолчанию опция отключена. Для эффективного контроля почтовой переписки пользователей требуется указать конкретное название полей, взятых из заголовков писем, через пробел или каждое название в новой строке. Для индексирования всех существующих полей достаточно указать символ * .
Данные, полученные в результате перехвата FTP-трафика, переписок в мессенджерах, контроля накопителей информации, облачных сервисов и сетевых ресурсов, помимо прочей информации могут содержать файлы большого размера. Для того, чтобы база данных работала быстро, рекомендуется сохранять перехваченные файлы на диск сервера или сетевого ресурса:
- На вкладке Дополнительные настройки установите переключатель Хранение файлов на диске в активное положение.


- В поле Путь к папке введите путь к папке, в которую требуется сохранять все перехваченные файлы. Для выбора папки на диске сервера используйте кнопку обзора .
Примечание.
Если требуется сохранять файлы на диске сетевого ресурса, укажите сетевой путь к ресурсу.
- Убедитесь, что служба Центрального сервера запущена под учетной записью, которая имеет право доступа к указанной папке (подробнее см. п. Настройка параметров запуска сервисов).
- Для того, чтобы избежать снижения быстродействия файловой системы (возникающего в результате обработки большого числа файлов), рекомендуется сохранять файлы небольшого размера в базу данных. Для этого установите переключатель Сохранять файлы малого размера в БД в активное положение и укажите максимально допустимый размер файла. Файлы, размер которых не превышает заданное значение, будут сохраняться в базу данных. Файлы, размер которых больше заданного, будут сохраняться в указанную папку на диске компьютера.

5. Для отключения процессов распознавания речи, текста или печатей в текущей базе данных воспользуйтесь соответствующими переключателями. Данный блок настроек не влияет на работу других существующих баз данных.
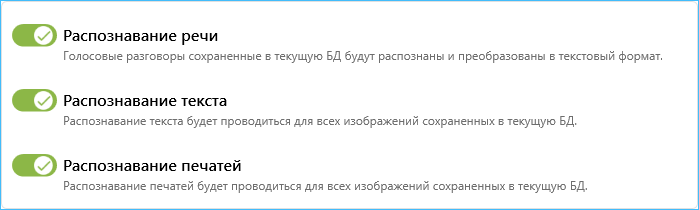
Примечание.
Данный блок настроек не активирует распознавание в текущей базе данных в ситуации, когда в настройках Центрального сервера распознавание отключено.
Использование и настройка PostgreSQL
pg_config — эта утилита выводит параметры (например, с какими параметрами скомпилирован PostgreSQL) конфигурации текущей установленной версии PostgreSQL. Находится в пакете postgresql-devel (для ОС Fedora Linux) postgresql-server-dev-8.3(для ОС Debian 5).
pg_ctl является утилитой для запуска, остановки, перезапуска, перезагрузки конфигурационных файлов, информирования о состоянии сервера PostgreSQL, или отправки сигналов PostgreSQL- процессу. Показать статус севера:
# sudo -u postgres pg_ctl status -D /var/lib/pgsql/data
PostgreSql postgresql.conf — настройки сервера.
PostgreSQL (произносится «Постгре-Эс-Кю-Эль», коротко называется «Постгрес») — свободная объектно-реляционная система управления базами данных (12 правил Кодда: что такое система управления базами данных). Использует порт 5432/tcp/udp. PostgreSQL использует только один механизм хранения данных под названием Postgres storage system (система хранения Postgres), в котором транзакции и внешние ключи полностью функциональны, в отличии от Движок БД MySQL, в котором InnoDB и BDB являются единственными типами таблиц, которые поддерживают транзакции.
По умолчанию PostgreSQL настроен так, что каждый локальный пользователь может подсоединиться к базе совпадающей по названию с регистрационным именем клиента, при условии что такая база данных уже создана.
Все объекты (таблицы, индексы …) базы данных в PostgreSQL хранятся в каталоге data/base/OID, т.е. названием каталога содержащего БД, будет не имя БД (как в Движок БД MySQL), а номер (OID) БД.
MVCC — одна из ключевых технологий доступа к данным, которая используется в PostgreSQL. Она позволяет осуществлять параллельное чтение и изменение записей (tuples) одних и тех же таблиц без блокировки этих таблиц. Чтобы иметь такую возможность, данные из таблицы сразу не удаляются, а лишь помечаются как удаленные. Изменение записей осуществляется путем маркировки этих записей как удаленных, и созданием новых записей с измененными полями. Таким образом, история изменений одной записи сохраняется в базе данных и доступна для чтения другими транзакциями. Этот способ хранения записей позволяет параллельным процессам иметь неблокирующий доступ к записям, которые были удалены или изменены в параллельных незакрытых транзакциях. Техника, используемая в этом подходе, относительно простая. У каждой записи в таблицы есть системные скрытые поля xmin, xmax.
xmin — хранит номер транзакции, в которой запись была создана.
xmax — хранит номер транзакции, в которой запись была удалена или изменена.Перед началом выборки данных PostgreSQL сохраняет снапшот текущего состояния БД. На основании данных снапшота, полей xmin, xmax осуществляется фильтрация записей.
pg_hba.conf идентификация пользователей
pg_hba.conf — настройка политики доступа к базам данных и идентификации пользователей сервера Использование и настройка PostgreSQL.
В этом файле описываются клиентские компьютеры сети, с которых разрешен доступ к SQL серверу Использование и настройка PostgreSQL, а также методы идентификации клиентов. Этот файл может содержать два вида записей:
Запись вида «host». host <имя базы данных> [аргумент для авторизации]
Запись типа «local». Эта запись определяет авторизацию доступа к базе данных локальных пользователей. Идентично «host», за исключением того, что IP- адрес и маска адреса опущены за ненадобностью.
trust в этом режиме авторизации доступа не производится. Соединение считается доверительным.
Каждая запись в файле pg_hba.conf должна полностью умещаться в одной строке. Перенос записей на другую строку запрещен.
Примеры записей pg_hba.conf:
Разрешить всем пользователям доступ с любого хоста к всем базам данных по логину и паролю
# TYPE DATABASE USER ADDRESS METHOD host all all all md5
Разрешить пользователю(dbuser) доступ к базе данных(mother) с любого хоста по логину и паролю
host mother dbuser all md5
Кодировка БД PostgreSQL и locale
PostgreSQL поддерживает только общую для всех баз кластера кодировку, которая должна совпадать с локальной кодировкой (Настройка переменных локализации в Linux), иначе не будут работать строковые функции сортировки, upper/lower и т.п. Локаль общая для всех процессов сервера — соответственно он не может создать две базы в разных кодировках — кодировка всегда одна для всего сервера и всех его БД.
Посмотреть кодировку сервера (show server_encoding) и клиента(show client_encoding):
postgres=# show server_encoding; server_encoding ----------------- UTF8 (1 row)
Т.е. создать базу в другой кодировке можно, но тогда в ней будут неправильно работать функции обработки строк и сортировка строк.
Указывать список кодировок нужно не для createdb (create database), а для подключения клиента к серверу (client_encoding), если кодировка символов которую ожидает программа-клиент не совпадает с её (программы-клиента) текущей системной локалью, с которой она была запущена.
Клиенты администрирования PostgreSQL
pgAdmin — GUI для PostgreSQL. Лучший графический клиент из существующих.
DBeaver Community Free Universal Database Tool — бесплатный многоплатформенный инструмент для работы с базами данных для разработчиков, администраторов баз данных, аналитиков и всех, кому необходимо работать с базами данных. Поддерживает все популярные базы данных: MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase, MS Access, Teradata, Firebird, Apache Hive, Phoenix, Presto и др.
phpPgAdmin — веб- приложение с открытым кодом, написанное на языке PHP и представляющее собой веб- интерфейс для администрирования СУБД PostgreSQL.
OpenOffice и SDBC. Для прямого доступа из OpenOffice к PostgreSQL без промежуточного уровня в виде ODBC/JDBC драйверов разрабатывается postgresql-sdbc драйвер.
# apt install openoffice.org-sdbc-postgresql
DbVisualizer в бесплатной версии ограничен набор функций.
psql
psql — PostgreSQL interactive terminal.
PL/pgSQL ( (Procedural Language/PostGres Structured Query Language) — процедурное расширение языка SQL, используемое в СУБД PostgreSQL.
В директории /usr/share/doc/postgresql* можно найти дополнительную информацию по запуску.
Подключиться к локальному серверу.
$ sudo -u postgres psql psql (8.4.5) Type "help" for help. postgres=#
Подключиться к удаленному серверу.
$ psql -h 192.168.1.20 -U postgres
В psql узнать подробности об определённом SQL команде можно при помощи \h (ключ \? выводит помощь по мета-командам), например для drop table:
postgres=# \h drop table Command: DROP TABLE Description: remove a table Syntax: DROP TABLE [ IF EXISTS ] name [, . ] [ CASCADE | RESTRICT ]
Пример выполнения SQL запроса из командой строки
# sudo -u postgres psql -d mybd --command="select * from pg_stat_user_indexes where schemaname='public';"
Как в PostgreSQL посмотреть список пользователей?
postgres=# select * from pg_shadow; postgres=# \du
Вывести список баз данных:
postgres=# select * from pg_database; или postgres=# \l Из командной строки: # psql -U postgres -A -q -t -c "select datname from pg_database" или: # psql -l
Вывести название текущей базы данных:
SELECT current_database();
Вывести имя (идентификатор) текущего пользователя:
SELECT current_user;
Вывести список таблиц активной базы данных (если после ключа \d указать имя таблицы — будет выведена структура таблицы):
postgres=# \dt или select * from pg_tables; # будут выведены все таблицы, в том числе и системные select tablename from pg_tables where schemaname='public';
Удалить БД testbd777
# sudo -u postgres dropdb testbd777
Залить(восстановить) данные в БД c именем test777
# sudo -u postgres psql test777 < lost_cdr.sql
regexp_split_to_table. В текстовом поле ipaddr хранятся IP адреса разделенные ; т.е. 1 строка - много IP. Запрос выводит все IP в столбик т.н. 1 строка - 1 IP
SELECT regexp_split_to_table(ipaddr, E';') as ip FROM peers;
Вывести версию Postgresql:
postgres=# SELECT version(); PostgreSQL 8.4.8 on x86_64-redhat-linux-gnu, compiled by GCC gcc (GCC) 4.4.5 20101112 (Red Hat 4.4.5-2), 64-bit
Пример экранирования одинарной кавычки в слове Кот-д'Ивуар. В PHP для экранирования спецсимволов используется функция pg_escape_string().
$ psql -U postgres -d mydb --command="INSERT INTO countries (english,russian) VALUES ('Ivory Coast', 'Кот-д''Ивуар');"Для смены активной базы данных в psql, применяется ключ \с
Вывести время запуска сервера и uptimeSELECT pg_postmaster_start_time(); pg_postmaster_start_time ------------------------------- 2013-08-21 14:20:45.451467+00 SELECT current_timestamp - pg_postmaster_start_time() AS uptime;
Посмотреть и удалить активные запросы
Если запрос запущен из интерфейса pgsql, то завершение работы сервера не поможет - запрос все равно продолжит свое выполнение, необходимо вызывать функцию pg_cancel_backend.
select * from pg_stat_activity; # посмотреть все запросы select * from pg_stat_activity WHERE current_query like 'SELECT%'; # посмотреть все SELECT запросы select * from pg_stat_activity WHERE current_query like 'INSERT%'; # снять все активные select запросы SELECT pg_cancel_backend(procpid) as x FROM pg_stat_activity WHERE current_query like 'SELECT%'; # снять запрос VACUUM SELECT pg_cancel_backend(procpid) as x FROM pg_stat_activity WHERE current_query like 'VACUUM%';
SELECT запросы можно снимать из ОС командой kill
# ps auxww | grep ^postgres . postgres 15724 97.7 11.3 2332996 1871476 ? Rs 07:50 1:53 postgres: postgres mybd 127.0.0.1(53624) SELECT . # kill 15724
procpid содержит PID процесса, которому можно сделать kill при необходимости. Например PID можно узнать запросом(отсортируем по длительности выполнения)
select datname,procpid,now()-query_start as duration,current_query from pg_stat_activity order by duration DESC;
Транзакции в PostgreSQL
В PostgreSQL Транзакция - это список команд SQL, которые находятся внутри блока, начинающегося командой BEGIN и заканчивающегося командой COMMIT.
PostgreSQL фактически считает каждый оператор SQL запущенным в транзакции. Если вы не указываете команду BEGIN, то каждый отдельный оператор имеет неявную команду BEGIN перед оператором и (при успешной отработке оператора) команду COMMIT после оператора. Группа операторов заключаемая в блок между BEGIN и COMMIT иногда называется транзакционным блоком.
Пример запуска транзакции из файла delprices.sql, которая удаляет в БД test777 из таблиц prices и ratesheets строки с >
# nano delprices.sql BEGIN; DELETE FROM prices WHERE ratesheet_id=2; DELETE FROM ratesheets WHERE > Выполним транзакцию для test777:
# sudo -u postgres psql -l # sudo -u postgres psql test777 < delprices.sql
Мониторинг, логи, размер БД PostgreSQL
Размер базы данных PostgreSQL, таблицы, столбца, количество строк. Мониторинг использования диска.
Лог файлы
Лог файлы PostgreSQL находятся в директории pg_log, для Fedora полный путь /var/lib/pgsql/data/pg_log. Детализация лог файлов настраивается в postgresql.conf.
Мониторинг
bucardo.org check_postgres - Perl cкрипт для мониторинга более 20 параметров, определяющих состояние СУБД PostgreSQL.
Текущую активность базы данных легко оценить с помощью команды ps, для вывода в реальном времени (с задержкой 1 секунда) можно использовать утилиту Команда watch с практическим примерами:
# watch -n 1 'ps auxww | grep ^postgres' postgres 14164 0.0 0.0 188492 5296 ? S Dec13 0:46 /usr/bin/postmaster -p 5432 -D /var/lib/pgsql/data postgres 14166 0.0 0.0 159904 1264 ? Ss Dec13 0:05 postgres: logger process postgres 14168 0.0 0.1 188636 27208 ? Ss Dec13 0:49 postgres: writer process postgres 14169 0.0 0.0 188492 1348 ? Ss Dec13 0:23 postgres: wal writer process postgres 14170 0.0 0.0 188804 1752 ? Ss Dec13 0:17 postgres: autovacuum launcher process postgres 14171 0.0 0.0 160176 1468 ? Ss Dec13 0:45 postgres: stats collector process postgres 21596 0.0 0.1 190228 30476 ? Ss Dec27 0:58 postgres: postgres mbill 127.0.0.1(37047) idle postgres 21597 0.0 0.0 189716 5672 ? Ss Dec27 0:00 postgres: postgres mbill 127.0.0.1(37048) idle
Так как для каждого клиента создаётся своя копия процесса postmaster, то это позволяет подсчитать число активных клиентов. Статусная строка даёт информацию о состоянии клиента. Фразы writer process, stats buffer process и stats collector process соответствуют системным процессам, запущенным самим PostgreSQL при старте. Пользовательские процессы имеют статусную строку вида:
postgres: «пользователь» «база» «хост» «статус»
«пользователь», «база» и «хост» соответствуют имени пользователя «пользователь» подсоединявшегося к базе «база» с компьютера «хост». «статус» может принимать следующие параметры:
idle - ожидание команды от клиента,
idle in transaction - ожидание команды от клиента внутри транзакции (между BEGIN и окончанием транзакции),
SQL- команда - выполняется эта команда, например, SELECT,
waiting - ждём когда разблокируется занятая другим процессом таблица. Для уточнения из-за чего возникла блокировка, нужно анализировать представление pg_locks.
Views сборщик статистики
Представления (Views) сборщика статистики.
Statistics Collector (Standard Statistics Views): описание системных таблицах, собирающих информацию об активности базы данных.
Если в PostgreSql postgresql.conf разрешён сбор статистики (logging_collector = on), то информация об активности базы данных собирается в специальных системных таблицах.
Информация собранная "статистическим сборником" может оказаться полезной для оценки эффективности базы данных и запросов. Из этих представлений можно узнать, например
Для каких таблиц стоит создать новые индексы (индикатором служит большое количество полных просмотров и большое количество прочитанных блоков).
Какие индексы вообще не используются в запросах. Их имеет смысл удалить, если, конечно, речь не идёт об индексах, обеспечивающих выполнение ограничений PRIMARY KEY и UNIQUE.
Достаточен ли объём буфера сервера.
Возможен "дедуктивный" подход, при котором сначала создаётся большое количество индексов, а затем неиспользуемые индексы удаляются.
Для сброса системной статистики(файл pgstat.stat) в ноль применяется команда
select pg_stat_reset();
Стандартные Statistics Views. Вывести все представления каталога
select schemaname,viewname,viewowner from pg_views where schemaname='pg_catalog';
pg_stat_activity - Каждая строка показывает: процесс сервера, OID базы данных, имя базы данных, ID процесса, OID пользователя, имя пользователя, имя приложения, адрес клиента и порт,время, текущею транзакцию, текущий запрос, статус процесса, текст запроса. Колонки показывающие данные текущего запроса доступны если параметр track_activities включен. Эти колонки доступны только для суперпользователя или пользователя владельца процесса.
select * from pg_stat_activity; # Вывести запросы отсортированные по длительности выполнения select datname,client_addr,now()-query_start as duration,current_query from pg_stat_activity order by duration DESC;
pg_stat_bgwriter
pg_stat_database - Одна строка на кажду БД. Выводит OID базы данных, имя базы данных, количество процессов подключенных к базе(numbackends), кол-во транзакций примененных(xact_commit) и отмененных(xact_rollback), количество прочитанных блоков(blks_read), количество попаданий в буфер(blks_hit), количество выбранных(tup_returned), переданных(tup_fetched), добавленных(tup_inserted), обновленных(tup_updated) и удаленных строк(tup_deleted).
select * from pg_stat_database;
Вывести соотношение hit/read. При выполнении запроса PostgreSQL сначала смотрит, есть ли нужные в запросе данные в разделяемой памяти (shared buffers). Если они найдены, засчитывается hit, если нет - делается сравнительно медленный системный вызов fread для поднятия данных с диска или из дискового кеша операционной системы и засчитывается read. В среднем, верно правило: чем больше отношение hit/read, тем лучше настроен PostgreSQL, так как он очень мало читает с диска, в основном извлекая данные из разделяемой памяти. Для большинства не очень больших баз это отношение должно лежать в пределах 5000-10000. Не стремитесь, однако, искусственно завысить настройку shared_buffers, которая прямо определяет hit/read: слишком большие размеры разделяемой памяти ведут к потере производительности в базах с интенсивной записью. Также стоит помнить, что fread может быть довольно быстрым, если данные находятся в дисковом кеше ОС.
select datname, case when blks_read = 0 then 0 else blks_hit/blks_read end as ratio from pg_stat_database;
pg_stat_all_tables - Для каждой таблицы в текущей базе данных (включая TOAST таблицы): OID таблицы(relid), схема(schemaname) и имя таблицы(relname), количество последовательны просмотров(seq_scan), количество строк выбранных запросами(seq_tup_read), количество просмотров индексов (все индексы данной таблицы)(idx_scan), количество строк выбранных через сканирование индексов(idx_tup_fetch), количество: пересечений строк(n_tup_ins), обновленных(n_tup_upd), удаленных строк(n_tup_del), количество обновленных HOT строк(n_tup_hot_upd), количество живых(n_live_tup) и мертвых строк(n_dead_tup), время последнего ручного vacuum, время последнего автоматического vacuum, время последнего ручного analyze, время последнего автоматического analyze. Запросы для активной БД:
select * from pg_stat_all_tables where schemaname='public'; select relname,last_vacuum,last_autovacuum,last_analyze,last_autoanalyze from pg_stat_all_tables where schemaname='public';
pg_stat_sys_tables - То же что и pg_stat_all_tables, только системные таблицы.
pg_stat_user_tables - То же что и pg_stat_all_tables, только пользовательские таблицы. Статистика seq scan/index scan. Список по таблицам: какое количество запросов к ним было выполнено посредством последовательного просмотра; какое количество запросов было выполнено с использованием индексов; а также отношение этих двух чисел. Позволяет оценить, все ли нужные индексы созданы в данной таблице. Если ваши таблицы содержат более нескольких тысяч рядов, последовательный просмотр будет выполняться медленнее просмотра индекса, поэтому в идеальном случае seqscan-ов в таких таблицах быть не должно. Если у вас они все же есть, анализируйте запросы к таким таблицам и создавайте соответствующие индексы. При этом важно не перестараться: чем больше индексов по колонкам таблицы, тем дороже становятся операции обновления данных. Также не забывайте, что после создания индекса таблице нужно делать ANALYZE, иначе планировщик запросов не заметит изменений в структуре таблицы.
select relname,seq_scan,idx_scan, case when idx_scan = 0 then 100 else seq_scan/idx_scan end as ratio from pg_stat_user_tables order by ratio desc; select relname,seq_scan,idx_scan, case when idx_scan = 0 then 100 else seq_scan/idx_scan end as ratio,n_live_tup,n_dead_tup from pg_stat_user_tables order by ratio desc;
Количество модификаций, произошедших в таблице. Список по таблицам: какое количество записей в них было добавлено, изменено и удалено с момента последнего сброса статистики. Администратор БД должен представлять, какие таблицы являются самыми нагруженными в текущей базе данных, а также каково соотношение между различными типами модифицирующих запросов к ним.
select relname,n_tup_ins,n_tup_upd,n_tup_del from pg_stat_user_tables order by n_tup_ins desc;
pg_stat_all_indexes - Поможет оценить эффективность и частоту использования индексов при реальной работе. Для каждого индекса текущей базы: OID таблицы и OID, схема, имя таблица и индекса, количество просмотров индекса(idx_scan), количество записей возвращенных при сканировании индекса(idx_tup_read), количество живых строк(idx_tup_fetch) таблицы полученных простым сканированием индексов используя этот индекс.
select * from pg_stat_all_indexes;
pg_stat_sys_indexes - То же что и pg_stat_all_indexes, только системные таблицы.
pg_stat_user_indexes - То же что и pg_stat_all_indexes, только пользовательские таблицы.select * from pg_stat_user_indexes where schemaname='public';
Статистика по индексам. Список по индексам: сколько записей из индекса были использованы в запросах по этому индексу; сколько рядов при этом получилось достать из родительской таблицы; разность этих двух чисел. Суть данной статистики проста: если у вас большая разница read-ов и fetch-ей, значит индекс устарел и ссылается на уже несуществующие данные, т.е. не всякий просмотр индекса и чтение из него соответствующего указателя на данные из таблицы (read) вызывает чтение самих данных из таблицы (fetch). В этом случае необходимо перестроить данный индекс, чтобы он соответствовал реальным данным в таблице.
select relname,indexrelname,idx_tup_read,idx_tup_fetch,(idx_tup_read-idx_tup_fetch) as diff, CASE WHEN idx_tup_read=0 THEN 0 ELSE (idx_tup_read::float4-idx_tup_fetch)/idx_tup_read END as r FROM pg_stat_user_indexes ORDER BY r desc;
pg_statio_all_tables - Для каждой таблицы текущей базы данных (включая TOAST таблицы), OID таблицы, схема и имя таблицы, количество блоков прочитанных с диска, количество попаданий в буфер, количество блоков прочитанных с диска и попавших в буфер для всех индексов таблицы, количество блоков прочитанных с диска и попавших в буфер that table’s auxiliary TOAST table (if any), количество блоков прочитанных с диска и попавших в буфер для индекса TOAST таблиц.
pg_statio_sys_tables - То же что и pg_statio_all_tables, только системные таблицы.
pg_statio_user_tables - То же что и pg_statio_all_tables, только пользовательские таблицы.pg_statio_all_indexes - Для каждого индекса текущей базы данных: OID таблицы и индекса, имя таблицы и индекса, количество блоков прочитанных с диска и попаданий в буфер.
pg_statio_sys_indexes - То же что и pg_statio_all_indexes, только системные таблицы.
pg_statio_user_indexes - То же что и pg_statio_all_indexes, только пользовательские таблицыpg_statio_all_sequences - Для каждой последовательности в текущей базе данных: OID последовательности, схема и имя последовательности, количество прочитанных блоков с диска и попаданий в буфер.
pg_statio_sys_sequences - То же что и pg_statio_all_sequences, только системные таблицы.
pg_statio_user_sequences - То же что и pg_statio_all_sequences, только пользовательские таблицы.
pg_stat_user_functions - Значения времени указано в миллисекундах.
pg_locks блокировки в PostgreSQL - информация о блокировках в базе данных.Уровни блокировок таблиц
Explicit Locking - документация о типах блокировок в PostgreSQL.
Команда LOCK TABLE предназначена для блокировки таблиц на время транзакции. Блокировкой называется временное ограничение доступа к таблице (в зависимости от выбранного режима). Сеанс, заблокировавший таблицу, пользуется нормальным доступом; последствия блокировки распространяются только на других пользователей, пытающихся получить доступ к заблокированной таблице.
Блокировка не означает отказа в доступе. С точки зрения пользователя, подключенного к базе данных и пытающегося обратиться к заблокированному ресурсу, блокировка приводит к задержке, но не к отказу в предоставлении доступа. Пользователю приходится ожидать либо завершения заблокированной команды пользователем, либо снятия блокировки с таблицы.
Некоторые команды SQL автоматически устанавливают блокировку для выполнения своих функций; в таких случаях PostgreSQL всегда выбирает минимально необходимый уровень блокировки. После завершения транзакции блокировка немедленно снимается.
Команда LOCK TABLE без параметра устанавливает максимально жесткий режим блокировки (ACCESS EXCLUSIVE). Чтобы ограничения были менее жесткими, следует явно задать нужный режим.
Блокировка таблиц возможна только в транзакциях. Выполнение команды LOCK TABLE вне транзакционного блока не приводит к ошибке, но установленная блокировка немедленно снимается. Транзакция создается командой BEGIN; команда COMMIT фиксирует изменения в базе данных и снимает блокировку.
Ситуация взаимной блокировки (deadlock) возникает в там случае, когда каждая из двух транзакций ожидает снятия блокировки другой транзакцией. Хотя PostgreSQL распознает взаимные блокировки и завершает их командой ROLLBACK, это все равно причиняет определенные неудобства. Приложения не должны сталкиваться с проблемой взаимных блокировок, поэтому проектируйте их так, чтобы объекты всегда блокировались в одинаковом порядке.
ACCESS SHARE MODE. Устанавливается автоматически командой SELECT для таблиц, из которых производится выборка данных. В заблокированных таблицах запрещается выполнение команд ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровня ACCESS EXCLUSIVE MODE.
ROW SHARE MODE. Устанавливается автоматически командами SELECT, содержащими секцию FOR UPDATE или FOR SHARE. В заблокированных таблицах запрещается выполнение команд ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
ROW EXCLUSIVE MODE. Устанавливается автоматически командами UPDATE, INSERT и DELETE. В заблокированных таблицах запрещается выполнение команд ALTER TABLE, DROP TABLE и CREATE INDEX. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней SHARE MODE, SHARE ROW EXCLUSIVE MODE, EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
SHARE UPDATE EXCLUSIVE MODE . Устанавливается автоматически командами VACUUM (без FULL), ANALYZE и CREATE INDEX CONCURRENTLY.
SHARE MODE. Устанавливается автоматически командами CREATE INDEX (без CONCURRENTLY). В заблокированных таблицах запрещается выполнение команд INSERT, UPDATE, DELETE, ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней ROW EXCLUSIVE MODE, SHARE ROW EXCLUSIVE MODE, EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
SHARE ROW EXCLUSIVE MOOE. Специальный режим блокировки, практически идентичный режиму EXCLUSIVE MODE, но допускающий установку параллельных блокировок уровня ROW SHARE MODE.
EXCLUSIVE MODE. Запрещает выполнение команд INSERT, UPDATE, DELETE, CREATE INDEX, ALTER TABLE, DROP TABLE и VACUUM, а также команд SELECT с секцией FOR UPDATE. В этом режиме для заблокированных таблиц также запрещаются параллельные блокировки уровней ROW SHARE MODE, ROW EXCLUSIVE MODE, SHARE MODE, SHARE ROW EXCLUSIVE MODE и ACCESS EXCLUSIVE MODE.
ACCESS EXCLUSIVE MODE. Устанавливается автоматически командами ALTER TABLE, DROP TABLE и VACUUM. В этом режиме для заблокированных таблиц запрещаются любые команды или параллельные блокировки любого уровня.
Подключение к PostgreSQL с локального компьютера
У ряда хостинг-провайдеров доступна возможность небезопасного подключения к PostgreSQL с домашнего или рабочего компьютера. На нашем хостинге в целях безопасности удаленное подключение к PostgreSQL запрещено.
Но присутствует возможность использовать SSH-туннель до сервера хостинга. Это позволит обеспечить зашифрованное соединение с базой данных PostgreSQL.
В данном примере для удаленной работы с PostgreSQL разберем подключение с помощью DBeaver.
1. Подготовка к работе
Для настройки подключения нам понадобятся реквизиты подключения по SSH, включающие в себя
- ip-адрес сервера (1)
- логин (2)
- пароль (3)
Данные реквизиты должны были прийти на вашу электронную почту при создании контейнера хостинга. Если не можете найти это письмо, реквизиты можно получить в панели управления хостингом. Пароль можно сбросить и получить новый.

Так же нам понадобится ip-адрес PostgreSQL-сервера, который мы можем определить следующим образом.
В настройках сайта переходим на вкладку PostgreSQL и получаем имя хоста (сервера).

В разделе Файлы запускаем Терминал

В терминале набираем команду ping «имя хоста PostgreSQL» (1), в нашем случае
и смотрим ip-адрес, который отвечает на наши запросы (2).

2. Настройка DBeaver
Последнюю версию DBeaver можно скачать с сайта dbeaver.io .
Запустив DBeaver выбираем в меню «Создать новое подключение». Выбираем PostgreSQL.

Далее настраиваем SSH-туннель:
- Ставим галочку «Использовать тунель SSH»
- Вводим IP-адрес из параметров подключения по SSH
- Вводим имя пользователя (логин)
- Пароль
- Жмем на кнопку «Тест соединения»
При первом подключении появится запрос относительно необходимости принять и сохранить ключ сервера в списке постоянных ключей. Ответьте согласием на этот вопрос.
- При успешном подключении – должно появиться такое окно

Возвращаемся на вкладку «Главная»
- В поле «Хост» пишем ip-адрес сервера, по которому отзывался PostgreSQL в Терминале
- В поле База данных – имя нашей базы данных из настроек PostgreSQL
- Пользователь и пароль из настроек PostgreSQL
- Нажимаем «Тест соединения»
- При успешном подключении – должно появиться такое окно

Теперь возможно работать с базой данных PostgreSQL удаленно со своего компьютера, используя DBeaver.
Инструкция подготовлена пользователем услуги Хостинг.