17 Дек Что такое AI, ML и Data Science? Машинное обучение (ML). Часть 2

Итак, мы продолжаем цикл статей о AI и ML, для начала приведем ключевые определения.
Что такое AI, ML и Data Science?
Давайте попробуем дать ответ на вопрос: “что такое ИИ, ML, Data Science и чем они отличаются?”
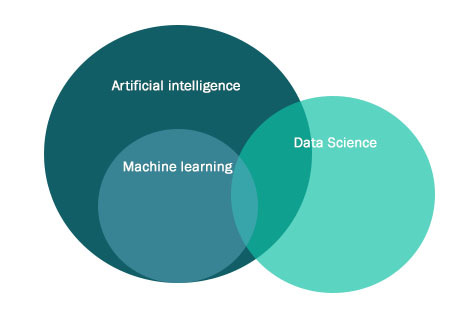
Чаще всего под термином Искусственный интеллект мы подразумеваем, что это некая система (абстракция), обладающая свойствами интеллекта человека, которая может мыслить, решать задачи (в том числе творческие), которые подразумевают наличие мыслительного процесса для его выполнения. Пожалуй, самое важное, что нужно знать — искусственного интеллекта, который описан выше, на данный момент, не существует. Слишком сложен наш мозг и сознание в целом для того, чтобы их оцифровать или сделать математическую модель, копирующую работу нашего сознания. Однако, существуют попытки (в том числе довольно удачные) имитации деятельности нашего мозга для решения тех или иных задач. Одним из направлений в ИИ, подпадающим под такую формулировку, является Machine Learning (ML).
Прежде чем перейти к ML, дадим более строгое определение для ИИ.

Искусственный интеллект, ИИ (Artificial Intelligence, AI) — инженерно-математическая дисциплина, занимающаяся созданием программ и устройств, имитирующих когнитивные (интеллектуальные) функции человека, включающие, в том числе, анализ данных и принятие решений.
Сильный ИИ/Человекоподобный ИИ (Strong AI, Super‑AI) — интеллектуальный алгоритм, способный решать широкий спектр интеллектуальных задач, как минимум, наравне с человеческим разумом.
Слабый ИИ/Специальный ИИ (Narrow AI, Weak AI) — интеллектуальный алгоритм, имитирующий человеческий разум в решении конкретных узкоспециализированных задач (игра в шахматы, распознавание лиц, общение на естественном языке, поиск информации и т.п.).

Машинное обучение — класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение за счёт опыта решений множества сходных задач. Для построения таких методов используются средства математической статистики, численных методов оптимизации, математического анализа, теории вероятностей, теории графов, а также различные техники работы с данными в цифровой форме.
Допустим, у нас есть алгоритм, который позволяет торговать на бирже. Он не знает о существовании биржи, трейдеров, брокеров и т.д. — это просто мат модель, которая обучена торговать на сотнях тысяч примеров. Аналогично, алгоритм, который водит беспилотный автомобиль, понятия не имеет о том, что такое автомобиль, дорога, двигатель, как он работает, и так далее. Алгоритм обучен на большом количестве примеров как решать ту или иную задачу, но не владеет способностью выходить за рамки сформулированной заранее задачи.
Алгоритмы машинного обучения — это программная реализация той или иной мат модели. Эта модель, на основании большого количества данных, “учится” решать ту или иную задачу, находя нужные закономерности в данных. Именно машинному обучению и принципам его работы и реализации его в проектах и будет посвящена основная часть этой статьи.

Data science — это обобщённое название отрасли, вида профессии, в которой основной упор делается на работу с данными. Дата Сайентистом может быть как человек, работающий с базами данных, или человек, разрабатывающий алгоритмы машинного обучения, так и человек, обслуживающий инфраструктуру, предназначенную для работы с данными.
Data science — это такое же обобщённое понятие, как и Сomputer science.
Теперь, разобравшись в терминах, остается вопрос: “А зачем нужен ML?”
Продолжение и ответ на этот вопрос читайте в следующей статье (часть 3)…
Распространенные мифы, которых следует опасаться в Data Science и машинном обучении
Что такое машинное обучение: Data Science или искусственный интеллект? Это один из самых распространенных вопросов, который мне задают. Этот вопрос ставит в тупик и начинающих пользователей, и специалистов по подбору персонала, и даже руководителей.
Начинающих пользователей волнует, как стать специалистом по обработке и анализу данных; руководители задаются вопросом, насколько важное влияние оказывает Data Science на бизнес. Люди, работающие в этой сфере, не могут определиться, как себя называть: Data Scientist, Data Engineer или Data Analyst.
В этом посте я попытаюсь прояснить некоторые мифы и дать общее понятие о том, что такое Data Science, и как ее интерпретируют в деловом мире.
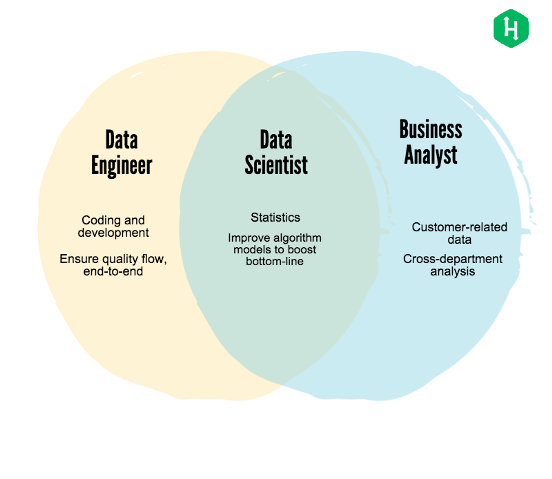
Миф 1: Data Scientist/Engineer/Analyst – это одно и то же.
Это искаженный миф, с которым я сталкивался много раз в своей карьере и который вредит как сотруднику, так и компании. Это все равно, что QA-инженера (специалиста по функциональному тестированию программного обеспечения на этапе разработки) называть инженером-программистом.
В широком смысле Data Scientist – это тот, кто имеет опыт и знания, как минимум, в двух из трех областей: статистики, программирования и машинного обучения. Такой сотрудник хочет работать над сложной бизнес-задачей, где он может использовать свои знания для поиска решений. Он стремится потратить бóльшую часть своей работы для создания предиктивных моделей и проведения статистических экспериментов, чтобы получить бизнес-решение. Это смесь исследовательской работы и программирования, а характер работы и нагрузка различаются в зависимости от размера компании/команды.
Data Engineering – это работа, в которой человек сосредотачивается на создании инфраструктуры для запуска приложений, выполняющих такие задания, как: предиктивное моделирование, обновление панелей потоковой передачи данных, выполнение ежедневных заданий для создания отчетов и поддержание непрерывного потока данных. Хороший инженер данных должен знать SQL (язык структурированных запросов) и Spark (программную платформу распределенной обработки данных).
Data Analyst – это человек, который больше склонен к интерпретации и анализу бизнес-результатов, а не к процессу их создания. Такой человек предпочитает использовать инструменты для получения этих результатов и будет тратить бóльшую часть своего времени на интерпретацию и извлечение из них ценности для бизнеса. Аналитики данных были в этой отрасли задолго до того, как туда пришли исследователи данных, и основным инструментом выбора тогда был Excel. На самом деле, даже сегодня для небольшого объема данных Excel является наиболее эффективным инструментом. В настоящее время также используются такие инструменты, как PowerBI, Azure, которые предоставляют возможность выполнять аналитику большого объема данных. Основное внимание, однако, уделяется точному сообщению ежедневных результатов, а также результатов новой проверяемой гипотезы. Эти входные данные и формируют основание для важного принятия решений в бизнесе.
Миф 2: Глубокое обучение – это машинное обучение или искусственный интеллект
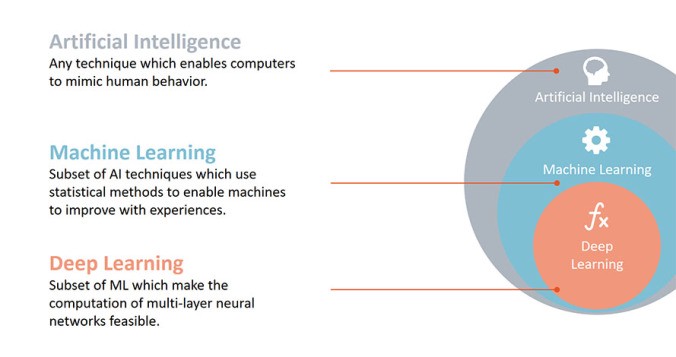
Благодаря маркетингу и шумихе вокруг него, о глубоком обучении сегодня знают многие. Как следствие, люди считают, что глубокое обучение может решить любую проблему в области Data Science или машинного обучения.
Глубокое обучение, несомненно, является одним из самых сложных понятий в современном машинном обучении, которые следует уяснить. Глубокое обучение получило свое название из-за того, что «нейронная сеть», подразумеваемая в его структуре, имеет несколько уровней и поэтому называется «глубокой» сетью. То, что предлагается через tensorflow, pytorch или keras, – просто основа для применения этой концепции.
Фреймворк достаточно сложен для изучения. Он эффективен, но не эквивалентен опыту, полученному в машинном обучении. Машинное обучение – это огромное поле, в котором используются концепции и алгоритмы из целого ряда областей: статистики, теории информации, оптимизации, поиска информации, нейронных сетей и т.д., и имеет множество алгоритмов, каждый из которых может быть полезен в конкретных случаях его использования.
Глубокое обучение, например, было очень эффективно в машинном зрении и распознавании речи, но его использование в анализе тональности высказываний или простой задаче прогнозирования, которая может быть решена с помощью линейной регрессии, является абсолютно лишним.
Разумно потратить время на исследовательский анализ и понимание масштабов проблемы до того, как использовать алгоритм, для решения конкретной проблемы.
Миф 3: Data Science нельзя изучить за 3 месяца
Как бы мне ни хотелось, чтобы это было неправдой, но это не так. Чтобы стать Data Scientist, нужно знать гораздо больше импортирования библиотеки через «scikit-learn» и «tensorflow».
Это одна из тех областей, где результаты не детерминированы, то есть одна и та же последовательность шагов не всегда ведет к одному и тому же результату. Все зависит от качества и количества предоставленных данных, а перед вызовом функции «train» следует совершить много действий.
Конечно, вы можете научиться импортировать библиотеки и записывать последовательность шагов для создания модели, но эта модель не всегда будет эффективной. Однако нужно понимать принцип работы и зависимости применяемого алгоритма. Крайне важно это знать, иначе настройка моделей или объяснение результатов руководству будет сопряжено с рядом проблем.
Вот так я всегда объясняю, когда меня спрашивают, как научиться кодированию за одну ночь.
Это небольшая попытка подчеркнуть и прояснить распространенные мифы в области машинного обучения и Data Science. Надеюсь, поможет.
Data Science vs Machine Learning: в чем разница?
Data Science — это большая и серьезная область, которая решает задачи от подбора фильма на вечер до предсказания рака на ранней стадии. Вместе с развитием этой сферы растет количество направлений и профессий в ней. Так как человек не алгоритм, в таком количестве данных можно запутаться. Например, Data Science и Machine Learning часто используют как синонимы, хотя это не совсем так. Они тесно связаны между собой, но работают с данными по-разному. Разбираемся, как, на примерах.

Освойте профессию «Data Scientist» на курсе с МГУ

Что такое Data Science
Data Science — это наука о том, как извлекать знания из данных, делать большие объемы информации полезными. Она состоит из множества разных методов и подходов, таких как анализ данных, машинное обучение, статистика, data mining. Дата-сайентисты работают с разными данными: структурированными таблицами, текстовыми документами, изображениями и звуковыми файлами. Задача специалистов — выявлять закономерности, тренды и взаимосвязи, которые можно использовать для принятия решений, создания прогнозов или улучшения бизнес-процессов.
25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

- сбор данных;
- очистка и подготовка;
- исследовательский анализ;
- построение моделей, их обучение;
- оценка эффективности моделей;
- презентация результатов.
Этап построения и обучения моделей — это часть Data Science, которая относится к Machine Learning.
Что такое Machine Learning
Machine Learning — это один из методов Data Science, который позволяет компьютерам учиться на основе данных. Machine Learning использует алгоритмы и математические модели, чтобы анализировать данные и выявлять в них закономерности. Алгоритмы запоминают, как это делается, и обучаются работать с любым набором похожих данных. Этот процесс позволяет системе улучшать свою производительность с опытом и адаптироваться к изменяющимся условиям.
Вернемся к примеру с интернет-магазином. Здесь обученная модель может анализировать действия пользователя на сайте и предсказывать, какие товары ему могут быть интересны и с большей вероятностью отправятся в корзину. На основе этих данных можно создавать персональные рекомендации на сайте или автоматизировать рассылку подборок на почту пользователя.
Как алгоритмы учатся выполнять такие задачи? Существует три основных типа машинного обучения:
Обучение с учителем (Supervised Learning). В наборе данных каждая запись имеет метку, соответствующую ее классу. Алгоритм машинного обучения должен научиться связывать характеристики данных с этими метками, чтобы классифицировать новые данные. Например, задача — научить компьютер узнавать котиков на фотографиях. Нужно показать алгоритму много фотографий с котиками и без и пояснить: «Вот это — котик, а это — нет». Затем показать компьютеру новые фотографии и спросить: «Это котик или нет?» В итоге компьютер научится сам определять, котик на фотографии или другой объект.
Обучение без учителя (Unsupervised Learning). Этот тип обучения используется, когда меток для данных нет. Алгоритм должен самостоятельно обнаружить структуру или закономерности в данных. В этом случае есть много фотографий, но ML-специалист не знает, котики на них или нет. Он просто отдает компьютеру все данные фотографий и ставит задачу: «Найди котиков». В результате компьютер находит области на фотографиях, где, скорее всего, есть котики, и сообщает об этом.
Обучение с подкреплением (Reinforcement Learning). Этот тип обучения похож на обучение с учителем, но вместо того чтобы получать метки для каждого примера, алгоритм получает награду или штраф за свои действия. По факту обучения разным данным присваивают позитивные значения и негативные. Это позволяет ему учиться на своих ошибках и стремиться к лучшим результатам.

Алгоритмы машинного обучения варьируются от простых, таких как линейная регрессия, до сложных, таких как нейронные сети. Простейшая линейная регрессия поможет, например, выбрать подержанный телефон по самой оптимальной цене. Алгоритм может посмотреть цены в нескольких объявлениях, вывести средний ценник, учесть важные параметры (например, осталась ли гарантия на телефон) и сделать вывод — подходящий телефон будет стоить X–Y тысяч рублей. Нейронные сети способны решать более сложные задачи, такие как обработка изображений и естественного языка, генерация картинок и текста.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
Чем отличаются Data Science и Machine Learning
Основное различие между Data Science и Machine Learning — в целях и задачах. Data Science стремится извлечь полезные знания из данных и предоставить инсайты для принятия решений. Data Science охватывает использование статистических методов, визуализации данных, исследование паттернов. Machine Learning фокусируется на создании моделей, способных автоматически делать прогнозы на основе данных.
Разберем на примере. Пользователь хочет купить телефон на сайте. Если он заходит на сайт впервые, сначала он просматривает все телефоны случайным образом. Затем он использует фильтры, чтобы сузить свои предпочтения, — например, бренд, объем аккумулятора, разрешение камеры. Из полученных результатов выбирает 4–5 телефонов и сравнивает их. После того, как пользователь выберет модель телефона, под товаром он увидит рекомендацию — похожий телефон по более низкой цене или с большим количеством функций, сопутствующие аксессуары для выбранного вами телефона и так далее. Как веб-сайт рекомендует их, если о человеке мало что известно?
Все благодаря данным миллионов других людей, которые выбирали тот же телефон, а также искали/покупали аксессуары. Ранее накопленный массив данных помогает системе автоматически рекомендовать вам то же самое. Весь процесс сбора данных от пользователей — очистка, фильтрация необходимых данных для оценки, поиск схожих тенденций — это Data Science.
На основе собранных данных и выявленных тенденций машина понимает, что это аксессуары, которые другие пользователи обычно покупают вместе с конкретным телефоном. Следовательно, он строит предположения, основываясь на том, чему он «научился» раньше. Это Machine Learning.
Итог
Возможно, различия будут более понятны, если представить их упорядоченно — в виде таблицы.
Data science и Machine learning — отличие и сходства

В сфере работы с данными часто можно встретить два понятия – Data Science и Machine Learning. Первое связано с исследованием данных, второе – с машинным обучением (к написанию программ для станков эта деятельность не имеет отношения). Более подробный рассказ о том, в чем отличие Data Science от Machine Learning, ждет вас далее.
Что такое Machine Learning и Data Science
- сбор, очистка и визуализация данных;
- использование методов неструктурированного управления данными;
- разработка программного обеспечения для автоматизации обработки данных;
- построение моделей и создание прогнозов.
Machine Learning – это особая область работы с данными, которая помогает обрабатывать массивы с информацией в автоматическом режиме, без участия человека. Это становится возможным благодаря использованию целого набора методик и алгоритмов, помогающих машине находить закономерности в данных и использовать их при прогнозировании.
Специалист по машинному обучению – это инженер, который и создает программу или компьютерную модель для тестирования различных решений и поиска наилучшего из них. Алгоритмы, созданные для этих целей, могут создавать прогнозы даже для сложных вопросов.
Машинное обучение применяется при прогнозировании трафика, создании рекомендательных систем (например, для фильмов в онлайн-кинотеатре), для сегментации клиентов, ранжирования выдачи в поиске и других процессов.
Какие навыки нужны, чтобы стать специалистом по Data Science или Machine Learning
Для работы с данными в рамках Data Science необходимо знание языка программирования Python или R, хотя бы базовое понимание SQL, а также владение алгоритмами машинного обучения.
Языки программирования помогают исследователю получать из необработанных данных больше информации, выводов и закономерностей, чем при ручном изучении. Без них целостный анализ не получится, поэтому Python или R – основа основ.
Вся неструктурированная информация изначально представлена в виде огромного массива, который нужно перенести в базу данных, а потом уже обрабатывать. Для этого нужно уметь работать в системах на основе SQL: MySQL, Oracle SQL, PostgreSQL и другие.
Алгоритмы Machine Learning – неотъемлемая часть Data Science, ведь они помогают автоматизировать множество рутинных процессов. Поэтому каждый исследователь данных должен знать хотя бы основы машинного обучения.
Если машинное обучение – часть науки о данных, то какие навыки необходимы таким специалистам? В первую очередь, инженер Machine Learning должен:
- Знать основы информатики и статистики;
- Уметь оценивать данные и составлять на их основе модели;
- Понимать и успешно применять алгоритмы;
- Владеть методами обработки естественного языка;
- Уметь проектировать архитектуры данных.
Если исходных данных слишком мало, нужно уметь их генерировать или собирать из других источников, а если слишком много – автоматизировать их обработку. В обоих случаях инженер машинного обучения должен создать модель и научить ее действовать по выбранному алгоритму.
На первый взгляд, Data Science и Machine Learning можно представить как взаимозаменяемые сферы деятельности. Но на деле это не совсем так – наука данных и машинное обучение – это в чем-то пересекающиеся, но существующие независимо друг от друга области.
Кратко: Data Science и машинное обучение – чем отличается одно от другого
Чтобы наш заключительный раздел получился действительно кратким, представим отличия Data Science от Machine Learning в виде таблицы.
| Data Science | Machine Learning |
| Фокус на алгоритмах и статистических исследованиях | Основное внимание уделяет разработке ПО и программированию |
| Работа с неконтролируемыми и контролируемыми алгоритмами | Автоматизация сложных аналитических процессов |
| Использование регрессии и классификации | Использует масштабирование разрозненных данных |
| Интерпретация результатов обязательна | Обработка данных необходима для планирования |
| Презентует результаты анализа менеджерам и руководителям, чтобы те принимали управленческие решения | Результаты работы включаются в таблицу или интегрируются в пользовательский интерфейс |
Другими словами, Machine Learning – это алгоритмы и ПО для автоматизации анализа данных, а Data Science – это исследование массивов информации, которое проводится для получения практической пользы. Для последнего используются разные методы, в том числе машинного обучения. Если вы хотите освоить одну из этих профессий, пройдите онлайн-курсы, выбрать которые можно с помощью нашего сервиса.