Измерение времени выполнения программы на Python
Одной из распространенных задач, с которыми сталкиваются разработчики, является определение времени выполнения программы или отдельного блока кода.
Алексей Кодов
Автор статьи
7 июля 2023 в 17:13
Одной из распространенных задач, с которыми сталкиваются разработчики, является определение времени выполнения программы или отдельного блока кода. Важность этой задачи обусловлена тем, что знание времени выполнения позволяет оптимизировать код, улучшая его эффективность и производительность.
В Python для измерения времени выполнения кода часто используется модуль timeit . Однако, он обычно применяется для измерения времени выполнения небольших фрагментов кода, а не всей программы. Как же можно измерить время выполнения всей программы?
Использование модуля time
Самый простой способ измерить время выполнения программы — использовать модуль time . В основе этого подхода лежит идея о том, что нужно зафиксировать время в момент начала выполнения программы, а затем, когда программа закончит работу, снова зафиксировать время и вычесть из него время начала. Разница между конечным и начальным временем и будет временем выполнения программы.
Пример кода, который демонстрирует этот подход:
import time start_time = time.time() # время начала выполнения # ваш код end_time = time.time() # время окончания выполнения execution_time = end_time - start_time # вычисляем время выполнения print(f"Время выполнения программы: секунд")
В этом примере функция time() модуля time возвращает текущее время в секундах с начала эпохи (обычно это 00:00:00 1 января 1970 года).
Использование модуля datetime
Альтернативный подход — использовать модуль datetime . Этот подход аналогичен предыдущему, но вместо функции time() используется функция datetime.now() . Пример кода:
from datetime import datetime start_time = datetime.now() # время начала выполнения # ваш код end_time = datetime.now() # время окончания выполнения execution_time = end_time - start_time # вычисляем время выполнения print(f"Время выполнения программы: секунд")
В этом примере функция datetime.now() возвращает текущее дату и время, а разница между конечным и начальным временем вычисляется как разность между двумя объектами datetime .
В заключение стоит отметить, что оба этих подхода позволяют измерить время выполнения всей программы или любого ее фрагмента. Выбор между ними зависит от ваших предпочтений и конкретных требований задачи.
Как сократить время выполнения данной программы (Python)?
Есть одна неинтересная задача, которую мне вроде как удалось решить (условия снизу, код в конце).
Складывай и умножай.
Ограничение времени 2 секунды
Ограничение памяти 64Mb
Ввод стандартный ввод или input.txt
Вывод стандартный вывод или output.txt
Вам даны два массива одинаковой длины A и B.
Вы должны выполнять 3 типа запросов:
“* l r x”: прибавить целое число x ко всем Ai, где l≤i≤r.
“. l r x”: прибавить целое число x ко всем Bi, где l≤i≤r.
“? l r”: вычислить сумму Al⋅Bl + … + Ar⋅Br.
Массивы пронумерованы, начиная с единицы. Изначально оба массива заполнены нулями.
Формат ввода
Первая строка входа содержит два целых числа n и m, разделённых пробелами — длина массивов и количество запросов, соответственно (1≤n,m≤100000).
Последующие m содержат запросы в формате, описанном в условии. Для каждого запроса 1≤l≤r≤n и 1≤x <10**9+7.
Формат вывода
Для каждого запроса третьего типа выведите остаток от деления соответствующей суммы на 10**9 + 7.
Пример
Ввод:
5 4
* 1 4 10
. 2 5 8
? 1 3
? 2 5
Вывод:
160
240
Все вроде и ничего, но на одном из тестой выдает TL. Время работы — 2,081 с. вместо 2-х с..
Хотелось бы переделать программку так, чтобы этой ошибки не было. Код моего решения:
# Functions def func_1(l,r,x,S): for i in range(l-1,r): S[i] += x return S def func_2(l,r,A,B): s = 0 for i in range(l-1,r): s += A[i] * B[i] return s % (10**9 + 7) # End of functions In_0 = list(map(int,input().split())) L = In_0[0] N = In_0[1] A = [0] * L B = [0] * L for i in range(N): In = list(input().split()) if In[0] == '*': A = func_1(int(In[1]),int(In[2]),int(In[3]),A) elif In[0] == '.': B = func_1(int(In[1]),int(In[2]),int(In[3]),B) elif In[0] == '?': print(func_2(int(In[1]),int(In[2]),A,B))- Вопрос задан более трёх лет назад
- 714 просмотров
Ускорение кода на Python средствами самого языка

Каким бы хорошим не был Python, есть у него проблема известная все разработчикам — скорость. На эту тему было написано множество статей, в том числе и на Хабре.
- Использовать Psyco
- Переписать часть программы на С используя Python C Extensions
- Сменить
мозгиалгоритм
- «Порог вхождения» у C и Python/C API все же выше, чем у «голого» Python’a, что отсекает эту возможность для разработчиков, не знакомых с C
- Одной из ключевых особенностей Python является скорость разработки. Написание части программы на Си снижает ее, пропорционально части переписанного в Си кода к всей программе
Так что же делать?
Тогда, если для вашего проекта выше перечисленные методы не подошли, что делать? Менять Python на другой язык? Нет, сдаваться нельзя. Будем оптимизировать сам код. Примеры будут взяты из программы, строящей множество Мандельброта заданного размера с заданным числом итераций.
Время работы исходной версии при параметрах 600*600 пикселей, 100 итераций составляло 3.07 сек, эту величину мы возьмем за 100%
Скажу заранее, часть оптимизаций приведет к тому, что код станет менее pythonic, да простят меня адепты python-way.
Шаг 0. Вынос основного кода программы в отдельную
Данный шаг помогает интерпретатору python лучше проводить внутренние оптимизации про запуске, да и при использовании psyco данный шаг может сильно помочь, т.к. psyco оптимизирует лишь функции, не затрагивая основное тело программы.
Если раньше рассчетная часть исходной программы выглядела так:
for Y in xrange(height): for X in xrange(width): #проверка вхождения точки (X,Y) в множество Мандельброта, itt итераций То, изменив её на:
def mandelbrot(height, itt, width): for Y in xrange(height): for X in xrange(width): #проверка вхождения точки (X,Y) в множество Мандельброта, itt итераций mandelbrot(height, itt, width) мы получили время 2.4 сек, т.е. 78% от исходного.
Шаг 1. Профилирование
Стандартная библиотека Python’a, это просто клондайк полезнейших модулей. Сейчас нас интересует модуль cProfile, благодаря которому, профилирование кода становится простым и, даже, интересным занятием.
Полную документацию по этому модулю можно найти здесь, нам же хватит пары простых команд.
python -m cProfile sample.py
Ключ интерпетатора -m позволяет запускать модули как отдельные программы, если сам модуль предоставляет такую возможность.
Результатом этой команды будет получение «профиля» программы — таблицы, вида
4613944 function calls (4613943 primitive calls) in 2.818 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
.
С её помощью, легко определить места, требующие оптимизации (строки с наибольшими значениями ncalls (кол-во вызовов функции), tottime и percall (время работы всех вызовов данной функции и каждого отдельного соответственно)).
Для удобства можно добавить ключ -s time , отсортировав вывод профилировщика по времени выполнения.
В моем случае интересной частью вывода было (время выполнение отличается от указанного выше, т.к. профилировщик добавляет свой «оверхед»):
4613944 function calls (4613943 primitive calls) in 2.818 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
1 2.309 2.309 2.766 2.766 mand_slow.py:22(mandelbrot)
3533224 0.296 0.000 0.296 0.000
360000 0.081 0.000 0.081 0.000
360000 0.044 0.000 0.044 0.000
360000 0.036 0.000 0.036 0.000
.
Итак, профиль получен, теперь займемся оптимизацией вплотную.
Шаг 2. Анализ профиля
Видим, что на первом месте по времени стоит наша основная функция mandelbrot, за ней идет системная функция abs, за ней несколько функций из модуля math, далее — одиночные вызовы функций, с минимальными временными затратами, они нам не интересны.
Итак, системные функции, «вылизаные» сообществом, нам врядли удастся улучшить, так что перейдем к нашему собственному коду:
Шаг 3. Математика
Сейчас, код выглядит так:
pix = img.load() #загрузим массив пикселей def mandelbrot(height, itt, width): step_x = (2 - width / 1.29) / (width / 2.6) - (1 - width / 1.29) / (width / 2.6) #шаг по оси х for Y in xrange(height): y = (Y - height / 2) / (width / 2.6) #для Y рассчет шага не так критичен как для Х, его отсутствие положительно повлияет на точность x = - (width / 1.29) / (width / 2.6) for X in xrange(width): x += step_x z = complex(x, y) phi = math.atan2(y, x - 0.25) p = math.sqrt((x - 0.25) ** 2 + y ** 2) pc = 0.5 - 0.5 * math.cos(phi) if p 2: color = (i * 255) // itt pix[X, Y] = (color, color, color) break else: pix[X, Y] = (255, 255, 255) print("\r%d/%d" % (Y, height)), Заметим, что оператор возведения в степень ** — довольно «общий», нам же необходимо лишь возведение во вторую степень, т.е. все конструкции вида x**2 можно заменить на х*х, выиграв таким образом еще немного времени. Посмотрим на время:
1.9 сек, или 62% изначального времени, достигнуто простой заменой двух строк:
p = math.sqrt((x - 0.25) ** 2 + y ** 2) . Z_i = Z_i **2 + z p = math.sqrt((x - 0.25) * (x - 0.25) + y * y) . Z_i = Z_i * Z_i + z Шажки 5, 6 и 7. Маленькие, но важные
Прописная истина, о которой знают все программисты на Python — работа с глобальными переменными медленней работы с локальными. Но часто забывается факт, что это верно не только для переменных но и вообще для всех объектов. В коде функции идут вызовы нескольких функций из модуля math. Так почему бы не импортировать их в самой функции? Сделано:
def mandelbrot(height, itt, width): from math import atan2, cos, sqrt pix = img.load() #загрузим массив пикселей Еще 0.1сек отвоевано.
Вспомним, что abs(x) вернет число типа float. Так что и сравнивать его стоит с float а не int:
if abs(Z_i) > 2: ------> if abs(Z_i) > 2.0: Еще 0.15сек. 53% от начального времени.
И, наконец, грязный хак.
В конкретно этой задаче, можно понять, что нижняя половина изображения, равна верхней, т.о. число вычислений можно сократить вдвое, получив в итоге 0.84сек или 27% от исходного времени.
Заключение
Профилируйте. Используйте timeit. Оптимизируйте. Python — мощный язык, и программы на нем будут работать со скоростью, пропорциональной вашему желанию разобраться и все отполировать:)
Цель данной статьи, показать, что за счет мелких и незначительных изменения, таких как замен ** на *, можно заставить зеленого змея ползать до двух раз быстрее, без применения тяжелой артиллерии в виде Си, или шаманств psyco.
Также, можно совместить разные средства, такие как вышеуказанные оптимизации и модуль psyco, хуже не станет:)
Спасибо всем кто дочитал до конца, буду рад выслушать ваши мнения и замечания в комментариях!
UPD Полезную ссылку в коментариях привел funca.
- python
- python c api
- python speed
- performance optimization
- оптимизация кода
- python 2.7
6 способов измерить скорость программы на Python
Недавно мы решали сложную задачу Эйнштейна с помощью кода на Python, а потом оптимизировали его, чтобы сократить время выполнения. Там всё было просто: с четырёх часов мы оптимизировали время выполнения до долей секунды, и это было явно заметно. Но бывает так, что даже полсекунды оптимизации — это очень хорошо, когда речь идёт о высоконагруженных сервисах. Например, в соцсетях, которыми пользуются сотни тысяч пользователей в минуту. Сегодня мы покажем целых 6 простых способов измерения времени работы кода, которые может использовать каждый.
Как измерять время выполнения кода
В большинстве случаев измерить время работы кода можно так:
- Зафиксировать время начала работы.
- Зафиксировать время окончания работы.
- Вычесть первое значение из второго.
Ещё важно измерять время выполнения кода при одних и тех же условиях:
- конфигурация и мощность компьютера должны совпадать для всех замеров;
- загрузка процессора должна быть одинаковой;
- программа для работы с кодом должна быть одной и той же с одинаковой версией.
Но даже если эти условия выполняются, результаты нескольких замеров могут немного различаться для одного и того же кода. На это могут влиять фоновые процессы, поэтому для точных измерений проводят несколько замеров в чистой среде, когда кроме кода и системных процессов ничего нет.
Если будете заниматься оптимизацией, вот вам на вырост: нужно различать понятия wall time («время на стене») и процессорное время. Первое показывает прошедшее время от начала до конца работы, второе — время, которое процессор затратил на выполнение кода. Их значения могут различаться, если программа ожидает высвобождение ресурсов для выполнения. Но сейчас можно без этих тонкостей.
Модуль datetime
С помощью такого способа можно измерить время выполнения кода в формате часы:минуты:секунды:микросекунды. Мы использовали модуль datetime, когда оптимизировали код для решения загадки Эйнштейна и ускоряли работу программы более чем в 200 тысяч раз.
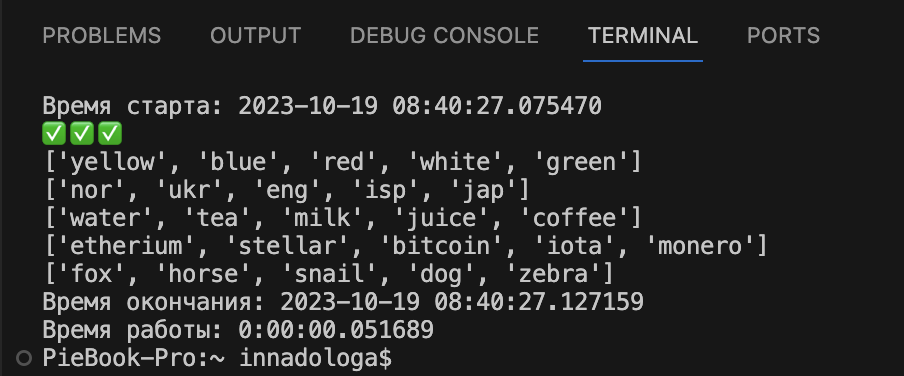
# подключаем модуль datetime import datetime # фиксируем и выводим время старта работы кода start = datetime.datetime.now() print('Время старта: ' + str(start)) # код, время работы которого измеряем #фиксируем и выводим время окончания работы кода finish = datetime.datetime.now() print('Время окончания: ' + str(finish)) # вычитаем время старта из времени окончания print('Время работы: ' + str(finish - start))Результат — 51 тысячная секунды. Неплохо, но что покажут другие способы?
Модуль time
Модуль time предоставляет разные возможности для измерения времени работы кода:
- time.time() поможет измерить время работы в секундах. Если нужно получить время в минутах, результат вычисления нужно разделить на 60, в миллисекундах — умножить на 1000.
- time.perf_counter() также можно использовать для измерения времени в секундах, но таймер не будет зависеть от системных часов. Функцию используют, чтобы избежать погрешностей. Функция time.perf_counter_ns() вернёт значение в наносекундах.
- time.monotonic() подходит для больших программ, поскольку эта функция не зависит от корректировки времени системы. Функция использует отдельный таймер, как и time.perf_counter(), но имеет более низкое разрешение. С помощью time.monotonic_ns() можно получить результат в наносекундах.
- time.process_time() поможет получить сумму системного и пользовательского процессорного времени в секундах, не включая время сна. Если процесс выполнения блокируется функцией time.sleep() или приостанавливается операционной системой, это время не включается в отчётное. Для наносекунд есть функция time.process_time_ns(), но её поддерживают не все платформы.
- time.thread_time() сообщит время выполнения текущего потока, а не процесса. Если в коде есть функция time.sleep(), время её выполнения не будет включено.
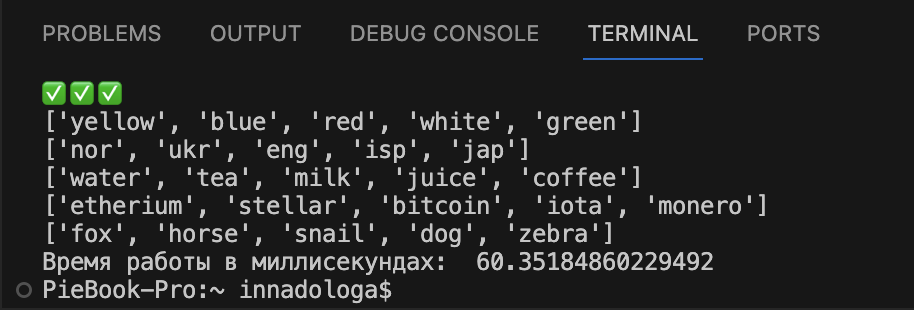
Time.time(). Давайте посчитаем время выполнения нашего кода с помощью функции time.time() в миллисекундах:
# подключаем модуль time import time # фиксируем время старта работы кода start = time.time() # код, время работы которого измеряем #фиксируем время окончания работы кода finish = time.time() # вычитаем время старта из времени окончания и получаем результат в миллисекундах res = finish - start res_msec = res * 1000 print('Время работы в миллисекундах: ', res_msec)Получаем результат: 61 тысячная секунды. Результат отличается от предыдущего, тут уже нужно было бы хорошо сделать серию тестов и посчитать среднее значение.
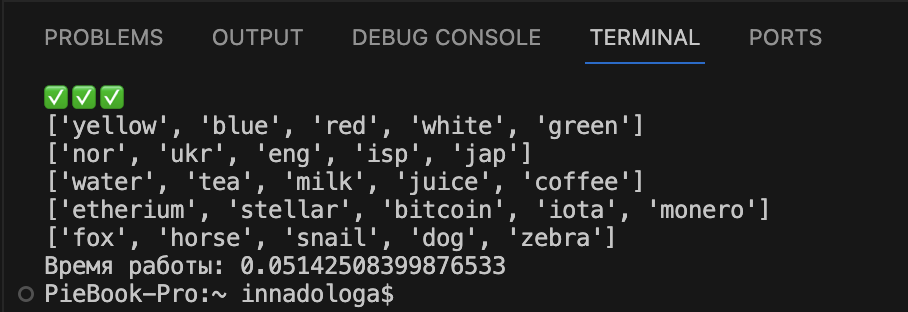
Time.perf_counter(). Посчитаем время выполнения нашего кода с помощью функции time.perf_counter() в секундах:
# подключаем модуль time import time # фиксируем время старта работы кода start = time.perf_counter() # код, время работы которого измеряем #фиксируем время окончания работы кода finish = time.perf_counter() # вычитаем время старта из времени окончания и выводим результат print('Время работы: ' + str(finish - start))Мы получили 51 тысячную секунды — почти такой же результат, как и в самый первый раз. Кажется, что это точное время, но посмотрим, что будет дальше.
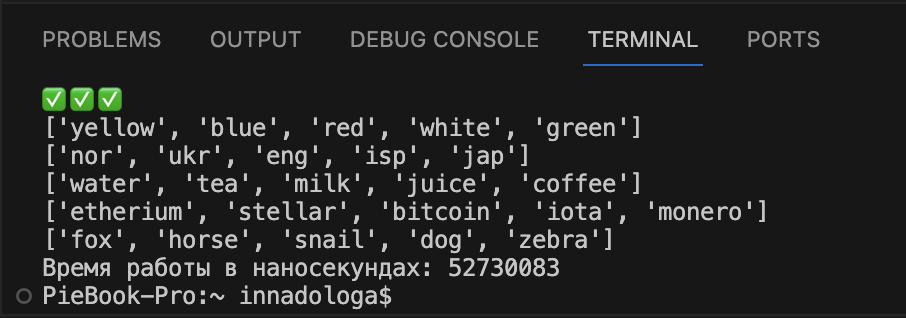
Time.monotonic_ns(). Посчитаем время выполнения нашего кода с помощью функции time.monotonic_ns() в наносекундах:
# подключаем модуль time import time # фиксируем время старта работы кода start = time.monotonic_ns() # код, время работы которого измеряем #фиксируем время окончания работы кода finish = time.monotonic_ns() # вычитаем время старта из времени окончания и получаем результат в наносекундах print('Время работы в наносекундах: ' + str(finish - start))Результат примерно такой же — 52 тысячные секунды, но количество цифр в результате меньше, чем в предыдущем случае.
Time.process_time(). Посчитаем сумму системного и пользовательского процессорного времени в секундах:
# подключаем модуль time import time # фиксируем время старта работы кода start = time.process_time() # код, время работы которого измеряем #фиксируем время окончания работы кода finish = time.process_time() # вычитаем время старта из времени окончания и выводим результат print('Время работы: ' + str(finish - start))Время работы снова выросло — с 51 до 62 тысячных секунды. Для одних программ такой разброс вообще некритичен, а для других это может означать, что нужно провести больше тестов.
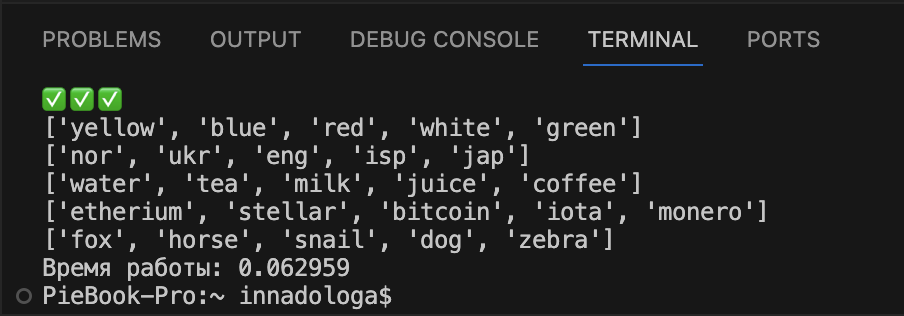
Time.thread_time(). Наконец, посчитаем время выполнения кода с помощью time.thread_time():
# подключаем модуль time import time # фиксируем время старта работы кода start = time.thread_time() # код, время работы которого измеряем #фиксируем время окончания работы кода finish = time.thread_time() # вычитаем время старта из времени окончания и выводим результат print('Время работы: ' + str(finish - start))Время работы снова выглядит правдоподобно в сравнении с предыдущим результатом.
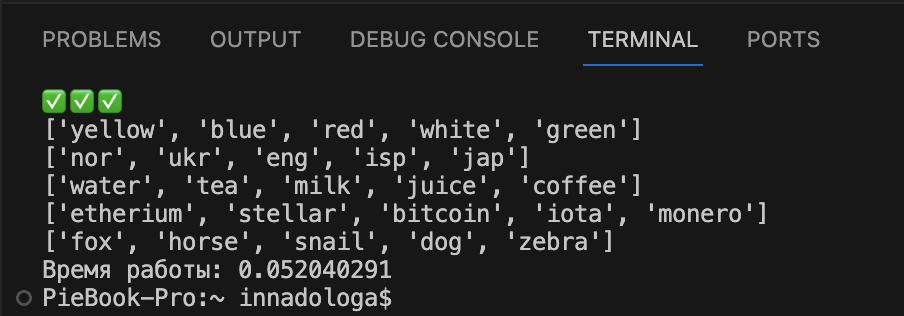
Что дальше
В следующий раз продолжим оптимизировать наш код решения задачи Эйнштейна: отформатируем и избавимся от вложенных данных. Подпишитесь, чтобы не пропустить продолжение.