Периодические задачи¶
celery beat — это планировщик; он запускает задания через регулярные промежутки времени, которые затем выполняются доступными рабочими узлами в кластере.
По умолчанию записи берутся из настройки beat_schedule , но можно использовать и пользовательские хранилища, например, хранить записи в базе данных SQL.
Вы должны убедиться, что для расписания одновременно работает только один планировщик, в противном случае вы получите дублирующиеся задачи. Использование централизованного подхода означает, что расписание не нужно синхронизировать, и служба может работать без использования блокировок.
Часовые пояса¶
В расписаниях периодических задач по умолчанию используется часовой пояс UTC, но вы можете изменить используемый часовой пояс с помощью параметра timezone .
Примером часового пояса может быть Европа/Лондон :
timezone = 'Europe/London'
Этот параметр должен быть добавлен в ваше приложение, либо путем его непосредственной настройки с помощью ( app.conf.timezone = ‘Europe/London’ ), либо путем добавления его в ваш модуль конфигурации, если вы установили его с помощью app.config_from_object . Более подробную информацию о параметрах конфигурации смотрите в Конфигурация .
Планировщик по умолчанию (хранящий расписание в файле celerybeat-schedule ) автоматически определит, что часовой пояс изменился, и сам сбросит расписание, но другие планировщики могут быть не такими умными (например, планировщик базы данных Django, см. ниже), и в этом случае вам придется сбросить расписание вручную.
Celery рекомендует и совместим с новой настройкой USE_TZ , представленной в Django 1.4.
Для пользователей Django будет использоваться часовой пояс, указанный в настройке TIME_ZONE , или вы можете указать пользовательский часовой пояс только для Celery с помощью настройки timezone .
Планировщик базы данных не перезагружается при изменении настроек, связанных с часовым поясом, поэтому вы должны сделать это вручную:
$ python manage.py shell >>> from djcelery.models import PeriodicTask >>> PeriodicTask.objects.update(last_run_at=None)
Django-Celery поддерживает только Celery 4.0 и ниже, для Celery 4.0 и выше, сделайте следующее:
$ python manage.py shell >>> from django_celery_beat.models import PeriodicTask >>> PeriodicTask.objects.update(last_run_at=None)
Записи¶
Чтобы периодически вызывать задачу, необходимо добавить запись в список расписания ударов.
from celery import Celery from celery.schedules import crontab app = Celery() @app.on_after_configure.connect def setup_periodic_tasks(sender, **kwargs): # Calls test('hello') every 10 seconds. sender.add_periodic_task(10.0, test.s('hello'), name='add every 10') # Calls test('world') every 30 seconds sender.add_periodic_task(30.0, test.s('world'), expires=10) # Executes every Monday morning at 7:30 a.m. sender.add_periodic_task( crontab(hour=7, minute=30, day_of_week=1), test.s('Happy Mondays!'), ) @app.task def test(arg): print(arg) @app.task def add(x, y): z = x + y print(z)
Установка их из обработчика on_after_configure означает, что при использовании test.s() мы не будем оценивать приложение на уровне модуля. Обратите внимание, что on_after_configure отправляется после установки приложения, поэтому задачи вне модуля, в котором объявлено приложение (например, в файле tasks.py , расположенном по celery.Celery.autodiscover_tasks() ), должны использовать более поздний сигнал, например on_after_finalize .
Функция add_periodic_task() добавит запись в настройку beat_schedule за кадром, и эту же настройку можно использовать для установки периодических заданий вручную:
Пример: Запускайте задачу tasks.add каждые 30 секунд.
app.conf.beat_schedule = 'add-every-30-seconds': 'task': 'tasks.add', 'schedule': 30.0, 'args': (16, 16) >, > app.conf.timezone = 'UTC'
Если вы задаетесь вопросом, где должны находиться эти настройки, пожалуйста, смотрите Конфигурация . Вы можете либо установить эти параметры непосредственно в вашем приложении, либо оставить отдельный модуль для настройки.
Если вы хотите использовать кортеж из одного элемента для args , не забудьте, что конструктор — это запятая, а не пара круглых скобок.
Использование timedelta для расписания означает, что задание будет отправляться с интервалом в 30 секунд (первое задание будет отправлено через 30 секунд после запуска celery beat , а затем каждые 30 секунд после последнего запуска).
Существует также расписание, подобное Crontab, см. раздел Crontab schedules.
Как и в случае с cron, задачи могут накладываться друг на друга, если первая задача не завершится раньше следующей. Если это вызывает беспокойство, следует использовать стратегию блокировки, чтобы гарантировать, что одновременно может выполняться только один экземпляр (см., например, Обеспечение выполнения задания только по одному разу ).
Доступные поля¶
Имя задания для выполнения.
Частота выполнения. Это может быть число секунд как целое число, timedelta , или crontab . Вы также можете определить свои собственные типы расписаний, расширив интерфейс schedule .
Позиционные аргументы ( list или tuple ).
Аргументы ключевых слов ( dict ).
Варианты исполнения ( dict ). Это может быть любой аргумент, поддерживаемый apply_async() – exchange , routing_key , expires и так далее.
Если relative равно true timedelta расписания планируются «по часам». Это означает, что частота округляется до ближайшей секунды, минуты, часа или дня в зависимости от периода timedelta . По умолчанию relative равно false, частота не округляется и будет относиться к моменту запуска celery beat.
Расписания Crontab¶
Если вы хотите больше контролировать время выполнения задания, например, определенное время суток или день недели, вы можете использовать тип расписания crontab :
from celery.schedules import crontab app.conf.beat_schedule = # Executes every Monday morning at 7:30 a.m. 'add-every-monday-morning': 'task': 'tasks.add', 'schedule': crontab(hour=7, minute=30, day_of_week=1), 'args': (16, 16), >, >
Синтаксис этих выражений Crontab очень гибкий.
Пример.
Смысл
Выполняйте каждую минуту.
Выполнять ежедневно в полночь.
Выполнять каждые три часа: полночь, 3 утра, 6 утра, 9 утра, полдень, 3 вечера, 6 вечера, 9 вечера.
То же, что и предыдущий.
Выполняется каждые 15 минут.
Выполняется каждую минуту (!) по воскресеньям.
То же, что и предыдущий.
Выполнять каждые десять минут, но только между 3-4 часами утра, 5-6 часами вечера и 10-11 часами вечера по четвергам или пятницам.
Выполнять каждый четный час и каждый час, кратный трем. Это означает: в каждый час за исключением: 1 утра, 5 утра, 7 утра, 11 утра, 1 вечера, 5 вечера, 7 вечера, 11 вечера.
Выполнение часа, кратного 5. Это означает, что он срабатывает в 15:00, а не в 17:00 (так как 15:00 равно 24-часовому значению часов «15», которое делится на 5).
Выполнять каждый час, кратный 3, и каждый час в рабочее время (с 8 утра до 5 вечера).
crontab(0, 0, day_of_month=’2′)
Выполнять во второй день каждого месяца.
Выполняйте в каждый четный день.
Выполнять в первую и третью недели месяца.
Выполняется одиннадцатого мая каждого года.
Выполнять каждый день в первый месяц каждого квартала.
Дополнительную документацию см. в разделе celery.schedules.crontab .
Солнечные графики¶
Если у вас есть задание, которое должно выполняться в соответствии с восходом, закатом, рассветом или сумерками, вы можете использовать тип расписания solar :
from celery.schedules import solar app.conf.beat_schedule = # Executes at sunset in Melbourne 'add-at-melbourne-sunset': 'task': 'tasks.add', 'schedule': solar('sunset', -37.81753, 144.96715), 'args': (16, 16), >, >
Аргументы просты: solar(event, latitude, longitude)
Обязательно используйте правильный знак для обозначения широты и долготы:
Подписаться
Аргумент
Смысл
Возможными типами событий являются:
Событие
Смысл
Выполните в момент, после которого небо уже не будет полностью темным. Это происходит, когда солнце находится на 18 градусов ниже горизонта.
Выполняется, когда солнечного света достаточно, чтобы горизонт и некоторые объекты были различимы; формально, когда солнце находится на 12 градусов ниже горизонта.
Выполняйте, когда света достаточно для того, чтобы объекты были различимы, и можно было приступать к активному отдыху; формально, когда Солнце находится на 6 градусов ниже горизонта.
Выполняется, когда верхний край солнца появляется над восточным горизонтом утром.
Выполняется, когда солнце находится выше всего над горизонтом в этот день.
Выполняется, когда край солнца исчезает над западным горизонтом в вечернее время.
Выполняйте в конце гражданских сумерек, когда объекты еще различимы и видны некоторые звезды и планеты. Формально, когда солнце находится на 6 градусов ниже горизонта.
Выполняется, когда солнце находится на 12 градусов ниже горизонта. Объекты больше не различимы, а горизонт больше не виден невооруженным глазом.
Выполнить в момент, после которого небо становится полностью темным; формально, когда солнце находится на 18 градусов ниже горизонта.
Все солнечные события рассчитываются по UTC, поэтому на них не влияют настройки вашего часового пояса.
В полярных регионах солнце может всходить и заходить не каждый день. Планировщик способен обрабатывать такие случаи (т.е. событие sunrise не будет выполняться в день, когда солнце не восходит). Единственным исключением является solar_noon , которое формально определяется как момент прохождения солнца через небесный меридиан, и будет происходить каждый день, даже если солнце находится ниже горизонта.
Сумерки определяются как период между рассветом и восходом солнца, а также между закатом и сумерками. Вы можете запланировать событие в соответствии с «сумерками» в зависимости от вашего определения сумерек (гражданские, морские или астрономические), а также от того, хотите ли вы, чтобы событие произошло в начале или конце сумерек, используя соответствующее событие из списка выше.
Дополнительную документацию см. в разделе celery.schedules.solar .
Celery: начинаем правильно

10 Фев. 2016 , Python, 170958 просмотров, Celery Best Practices: practical approach

В этой статье мне хотелось бы поделиться с читателями своим опытом работы с таким замечательным инструментом в Python как Celery. Celery это ничто иное как распределённая очередь заданий, реализованная на языке Python. На момент написания этой статьи, самой последней версией является 3.1.20. Неосведомлённый читатель может не знать для чего вообще нужна система очередей задач наподобие Celery, поэтому кратко поясню этот момент.
Что такое Celery и зачем оно нам?
Часто ли вам приходилось сталкиваться с типовыми задачами в веб-приложениях вроде отправки электронного письма посетителю или обработки загруженных данных. Чаще всего такого рода манипуляции не требуют участия конечного пользователя вашего проекта, то есть их можно выполнять в фоновом режиме. Те из нас, кто реализует выполнение этих задач в одном из процессов веб-сервера, «тормозят» тем самым его работу, увеличивая время отклика и ухудшают user experience.
В данной заметке я опущу вводную информацию по установке и настройке Celery в вашем проекте. Кстати, Celery из коробки умеет работать с Django. Ранее был отдельный python пакет, соединяющий Django и Celery,именовался он django-celery. Сейчас он заброшен, так как последнее обновление было более года назад. Стоит отметить, что django-celery не работает Django 1.9 из-за изменений в работе cache backend. Исправленную версию можно посмотреть в моём форке. Одной из удобных фич django-celery является интеграция с Django Admin по части управления periodic tasks.
Советы по работе с Celery
Не используйте базу данных в качестве broker/backend
Брокер отвечает за передачу сообщений (задач) между так называемыми исполнителями (workers). Проблема использования базы данных заключается в её ограничениях — она просто не предназначена для этого. Дело в том, что с ростом количества исполнителей, нагрузка на базу будет только возрастать, а учитывая тот факт, что каждый worker имеет ещё ряд потоков, ситуация может стать катастрофической даже при малых нагрузках. Всё это приведёт к бутылочному горлышку в виде затыка на I/O, потере задач, а возможно и неоднократному их исполнению (два воркера могут получить одну и ту же задачу на исполнение). Отличным production-ready решением является использование RabbitMQ или Redis для этой роли.
Бэкэнд в случае с Celery выступает в качестве хранилища результатов выполнения задач (task). Одной из причин создания django-celery как раз являлась возможность подключения БД для сохранения результатов. Признаюсь, что в самом начале работы с Celery я неоднократно в проектах использовал этот подход. Пожалуйста, не повторяйте мою ошибку. С ростом нагрузки на приложение проблемы будут расти словно грибы после дождя (более того, «из коробки» celery не чистит базу от «устаревших» результатов) . Правда тут есть нюансы касательно вашего приложения. Об этом читайте ниже. Production-ready решением для роли backend неплохо зарекомендовал себя демон memcached. Пользуемся более 2-х лет, проблем ни разу не было.
Разделяйте задачи по очередям
Это очень важный момент. По мере развития вашего приложения, в проекте будут появляться критичные для выполнения задачи: проверка статуса платежа, формирование отчёта, отправка электронных писем и так далее. Терять их недопустимо. Если все задачи складировать в одну очередь, то в один прекрасный момент она может забиться, поставив под угрозу выполнение критически важного кода. Мой подход: разделяйте очереди по приоритетам.
Несомненно очередей может быть больше, тут всё на усмотрение разработчика и архитектуры его приложения.
В базовых настройках Celery это выглядит следующим образом:
CELERY_QUEUES = ( Queue('high', Exchange('high'), routing_key='high'), Queue('normal', Exchange('normal'), routing_key='normal'), Queue('low', Exchange('low'), routing_key='low'), ) CELERY_DEFAULT_QUEUE = 'normal' CELERY_DEFAULT_EXCHANGE = 'normal' CELERY_DEFAULT_ROUTING_KEY = 'normal' CELERY_ROUTES = < # -- HIGH PRIORITY QUEUE -- # 'myapp.tasks.check_payment_status': , # -- LOW PRIORITY QUEUE -- # 'myapp.tasks.close_session': , > В данном конкретном примере объявлена очередь по-умолчанию под названием normal. То есть задачи явно не указанные в списке будут автоматически распределены в эту очередь. В high попадает задача под названием check_payment_status, а в low задача close_session.
Запускать исполнителей Celery для этих очередей необходимо следующим образом:
celery worker -E -l INFO -n worker.high -Q high celery worker -E -l INFO -n worker.normal -Q normal celery worker -E -l INFO -n worker.low -Q low Здесь мы явно задаём имена исполнителей и названия очередей в которых необходимо мониторить задачи на исполнение.
ВАЖНО! Если вы явно указали для задачи очередь в которую ей нужно будет падать, и при этом запустили одного из исполнителей Celery без явного указания очереди, например вот так:
celery worker -E -l INFO -n worker.whatever То при наступлении ситуации, когда все исполнители очереди high будут заняты, Celery автоматически перенаправит новую задачу исполнителям без конкретной очереди. Поэтому при использовании раздельных очередей задач, не запускайте исполнителей без указания для них явного наименования очереди.
Логгируйте ошибки
Логгирование ошибок и своевременный их анализ это основа надёжных приложений. Очень важно иметь полную картину происходящего внутри вашего кода. По-умолчанию Celery все ошибки пишет в stderr, а прочая информация, связанная с исполнением попадает в stdout. Контролировать вывод ошибок можно через стандартный python logging, достаточно повесить свой handler на logger под названием «celery». Практика развёртывания боевых приложений, использующих Celery, показывает, что в качестве процесс-менеджера используют supervisord. В его настройках можно задавать путь до файла в который он будет складировать всю информацию, генерируемую демоном. Но вручную анализировать текстовые логи на предмет ошибок неудобно и неэффективно. Лично я использую для этих целей Sentry. Вот как выглядит у меня logging config:
CELERYD_HIJACK_ROOT_LOGGER = False LOGGING = < 'handlers': < 'celery_sentry_handler': < 'level': 'ERROR', 'class': 'core.log.handlers.CelerySentryHandler' >>, 'loggers': < 'celery': < 'handlers': ['celery_sentry_handler'], 'level': 'ERROR', 'propagate': False, >, > > Важной опцией здесь является наличие CELERYD_HIJACK_ROOT_LOGGER = False. По-умолчанию значение этой переменной является True, что позволяет celery «перекрывать» все ранее объявленные кастомные обработчики logging.
При указанном выше подходе нет необходимости дополнительно в коде задач (task) логгировать ошибки/исключения отдельно. О том что такое Sentry, для чего оно используется и как его настроить я напишу отдельную статью немного позже.
Пишите задачи маленькими
При написании задач старайтесь придерживаться принципа минимализма кода. То есть не нужно в самом celery task описывать бизнес логику задачи. Например, если вам необходимо генерировать и отправлять отчёт, то не нужно в самом task писать код генерации и отправки. Разбейте его на 3 части:
- Код генерации отчёта
- Код отправки письма
- Задача (task) по выполнению этих действий
from .utils import generate_report, send_email @app.task(bind=True) def send_report(): filename = generate_report() send_email(subject, message, attachments=[filename]) Это, во-первых, позволит легче читать код (есть явное разделение на подзадачи). Во-вторых, тестировать такой код намного легче (привет модульным тестам!). В-третьих, отлавливать ошибки также будет намного легче и прозрачнее.
«Гасите» задачи вовремя
Явно указывайте лимит на выполнение задачи. Это можно сделать несколькими способами:
- Через декоратор @app.task, передавая soft_time_limit, time_limit.
- Глобально задать таймлимит при запуске исполнителя (worker), передав ему соответствующие аргументы (их можно найти в документации к Celery). В этом случае для всех задач, попадающих в заданную очередь будет один и тот же таймлимит.
Указание таймлимита очень важно, так как в некоторых случаях его отсутствие попросту приведёт к «зависанию» исполнителя при выполнении неоднозначных задач (требующих длительного времени, коннект к внешнему сервису и так далее).
Не храните результаты исполнения без необходимости
В большинстве случаев результат выполнения вашей задачи вам не нужен (например, если происходит отправка письма). В такой ситуации вам нет необходимости хранить что-то. Если ваши задачи полностью попадают в эту категорию, то в настройках Celery можно задать глобальный параметр CELERY_IGNORE_RESULT = True, который будет игнорировать результат исполнения всех ваших task-функций.
Используйте Flower для мониторинга исполнения задач
Всегда используйте Flower при работе с Celery. Всегда! Данный инструмент это небольшое веб приложение, написанное с использованием микрофреймворка Flask, а также Tornado для поддержки веб-сокетов. Flower позволяет вам всегда быть в курсе того как исполняются ваши задачи. Немного скриншотов:
![]()
Не поленитесь и потратьте время на его изучение. Оно окупится многократно!
Не передавайте ORM объекты в качестве аргументов
Я пару раз попадался на этом хитром трюке, который потрепал мне изрядно нервы. Рассмотрим вот такой код:
from .models import Profile @app.task(bind=True): def send_notification(profile): send_email(profile.user.email, subject, message_body) profile.notified = True profile.save() def notify_user(): profile = Profile.objects.get(id=1) check_smthng() send_notification.delay(profile) profile.activated = True profile.save() Не самый лучший пример для демонстрации побочного эффекта при передаче ORM объекта, но всё же. В данной ситуации код, описанный в send_notification, сохранит объект, изменив лишь notified = True, но activated останется по-прежнему равен False. Лучшим решением будет передача идентификатора объекта в базе данных, а в самой task функции необходимо непосредственно обращаться к объекту через его id.
BROKER_TRANSPORT_OPTIONS и visibility_timeout
При использовании Celery нередко приходиться прибегать к помощи отложенных задач, используя apply_async и передавая аргументы eta или countdown. Но делать это нужно осторожно, так как даже здесь нас поджидают «подводные камни». О чём речь? Очень часто у разработчиков, начинающих использовать очередь задач вроде Celery, происходят аномалии вроде выполнения одного и того же таска несколькими воркерами одновременно. Согласитесь, нежелательный сценарий. Так может происходить по причине того, что время, через которое должна выполниться задача, превышает visibility_timeout. По умолчанию для Redis этот параметр равен 1 часу. То есть если вы укажете выполнение задачи через 2 часа, то демон celery подождёт 1 час, поймёт, что никто из доступных воркеров не откликнулся и насильно назначит всем воркерам её выполнение при наступлении дедлайна (eta/countdown). Поэтому не забывайте про этот параметр, если вы собираетесь использовать механизмы eta/countdown/retry, задайте visibility_timeout равным самому длительному eta/countdown в вашем проекте. Подробнее можно почитать тут.
UPD: С недавних пор у блога появился свой Telegram канал, где я стараюсь делиться со своими подписчиками интересными находками из сети на тему разработки программного обеспечения и смежных с этой областью материалов.
Long-running tasks
Старайтесь не использовать Celery для выполнения долгих задач. На этот аргумент есть ряд причин:
- Процессы, живущие долго, потребляют память, но не освобождают её. Даже с учётом работы сборщика мусора. Такой механизм необходим, чтобы избежать фрагментации оперативной памяти.
- Celery заточен на выполнение большого количества задач, требующих мало времени на их исполнение. Когда задачи тяжелые и выполняются долго, образуются очереди.
Если нет возможности использовать что-то другое, то при работе с long-running tasks в Celery знайте следующее:
По-умолчанию 1 воркер процесс будет забирать из очереди 4 задачи за раз. Это особенно актуально знать, если Celery масштабируется на кластере через центрального брокера. То есть, если у вас 3 отдельные машины и на каждой крутится по 10 воркеров на очередь, то каждая машина будет забирать по 40 задач. Отсюда очевидно возникает проблема равномерного распределения задач по кластеру. Такое поведение оправдано в некоторых случаях, т.к. оно уменьшает количество обращений к брокеру, увеличивая производительность при выполнении небольших тасков. Чтобы изменить это, переопределите параметр CELERYD_PREFETCH_MULTIPLIER. Например:
CELERYD_PREFETCH_MULTIPLIER = 1Долгоживущие процессы имеют тенденцию к пожиранию памяти, но вот назад её зачастую не возвращают, поэтому в контексте использования Celery с ними иногда имеет смысл перезагружать воркеры после выполнения заданного количества тасков. За это отвечает параметр CELERYD_MAX_TASKS_PER_CHILD
CELERYD_MAX_TASKS_PER_CHILD= 1Настройка выше будет перезагружать воркер-процесс после выполнения 1 таска.
Полезные ссылки
- Документация Celery
- Celery: Distributed Task Queue
- Flower: Celery task monitoring
- Пакет django-celery
- Python RQ: очередь задач на базе Redis
Запускаем django и celery на хостинге
С появлением на нашем хостинге возможности запуска Фоновых процессов, запуск и использование Celery значительно упростилось. Пожалуй, даже можно сказать, что до Фоновых процессов запустить Celery должным образом было невозможно, поскольку постоянное наличие в памяти сервера хостинга запущенного процесса celery никаким образом не гарантировалось.
Что такое Фоновые процессы и чем они помогают в запуске Celery?
Celery — это планировщик асинхронных задач (asynchronous task queue). Процесс celery, запускающий наши задачи, должен работать отдельно от процесса сайта и в случае перезапуска контейнера сайта он должен стартовать автоматически. Как раз функционал автоматического перезапуска процесса в случае рестарта, падения и тп и обеспечивается Фоновыми процессами.
Создаем сайт
Фоновые процессы привязаны к сайтам, а сайты располагаются внутри контейнеров. Ознакомиться с процессом создания сайта на python (django) можно в этой статье.
Далее мы будем считать, что сайт создан, нужная версия python установлена и настроена через Личный кабинет и вы зашли на сервер по ssh. Для этой статьи в качестве примера мы создали сайт с именем celery.na4u.ru с развернутым на нем Django в связке с MySQL. При разворачивании сайта было автоматически создано django-приложение na4u .
Кроме этого, для работы Celery нам потребуется Redis. Чтобы активировать Redis, нужно в Личном кабинете перейти на страницу вашего контейнера (Хостинг -> выбираем требуемый контейнер), нажать на кнопку “Настройка тарифа” и активировать опцию Redis.
Устанавливаем зависимости и настраиваем Django
В консоли сервера переходим в папку app нашего сайта:
cd celery.na4u.ru/app В вашем любимом текстовом редакторе, будь то vim, nano, mcedit и тп, создаем файл requirements.txt следующего содержания:
django==4.1 celery redis django-celery-beat django-celery-results И теперь устанавливаем все прописанные в requirements.txt зависимости:
pip install -r requirements.txt Вновь берем свой любимый текстовый редактор и на этот раз вносим корректировки в файл na4u/settings.py :
INSTALLED_APPS = [ . 'django_celery_beat', 'django_celery_results', . ] DATABASES = < 'default': < . 'OPTIONS': , >, > CELERY_RESULT_BACKEND = 'django-db' CELERY_BROKER_URL = 'redis://localhost:6379' CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers.DatabaseScheduler' Теперь необходимо применить миграции для вновь добавленных django-приложений. Для этого в консоли сервера выполняем:
./manage.py migrate Далее, в папке нашего проекта na4u создаем файл celery.py :
import os from celery import Celery # set the default Django settings module for the 'celery' program. # this is also used in manage.py os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'na4u.settings') app = Celery('na4u') # Using a string here means the worker don't have to serialize # the configuration object to child processes. # - namespace='CELERY' means all celery-related configuration keys # should have a `CELERY_` prefix. app.config_from_object('django.conf:settings', namespace='CELERY') # Load task modules from all registered Django app configs. app.autodiscover_tasks() Наконец, отредактируем файл na4u/__init__.py чтобы он выглядел следующим образом:
from .celery import app as celery_app # noqa __all__ = ('celery_app',) Таким образом, при запуске django наш celery.app всегда будет импортирован.
Если до этого момента всё прошло удачно, мы можем запустить Celery в консоли:
celery -A na4u worker --beat Но, как вы наверняка понимаете, если сейчас закрыть консоль, то Celery будет остановлен. Да и никаких задач наш Celery пока не выполняет. Давайте исправим это.
Создаем задачи для Celery
Создадим django-приложение в котором будет размещаться код асинхронно выполняемых задач:
python manage.py startapp tasks
Конечно же это приложение нужно добавить в список INSTALLED_APPS в нашем settings.py :
INSTALLED_APPS = [ . 'tasks', . ] Теперь в папке tasks создадим файл tasks.py:
from celery import shared_task @shared_task def add(x, y): """ Супер сложная функция, требующая огромных вычислительных мощностей и поэтому запускаемая асинхронно """ return x + y Убедиться что Celery теперь стартует и видит нашу вновь созданную функцию можно с помощью команды
celery -A na4u worker -l info --beat Запускаем Celery как фоновый процесс
Давайте сделаем чтобы Celery работал постоянно. Для этого в Личном кабинете в нашем контейнере находим сайт celery.na4u.ru и переходим во вкладку Фоновые процессы:

И конечно же теперь нужно нажать на кнопку “Добавить процесс”. В появившемся окне в поле “Команда для запуска” мы пишем команду, которая запускает Celery:
cd ~/celery.na4u.ru/app && ~/celery.na4u.ru/.env/bin/celery -A na4u worker -l info --beat Теперь нажмем на кнопку “Добавить и запустить” и Celery запустится.
Чтобы убедиться что запуск Celery прошел успешно, в консоли запустите команду:
tail -f ~/celery.na4u.ru/log/service-ID-runlog/current где ID — это уникальный идентификатор процесса, который отображается в личном кабинете в списке созданных вами фоновых процессов. Эта команда покажет текущий лог Celery, обновляемый в реальном времени.
Убеждаемся что Celery запущен и работает
Чтобы убедиться что Celery запущен и работает, в папке app нашего сайта запускаем команду
./manage.py shell И в консоли python выполняем:
In [1]: from tasks.tasks import add In [2]: add(2, 2) Out[2]: 4 In [3]: add.delay(2, 3) Out[3]:
Собственно, вот и всё. Остается добавить, что после внесения изменения в код задач потребуется перезапуск процесса Celery. Это можно сделать двумя способами:
- Либо в Личном кабинете во вкладке Фоновых процессов нажать на кнопку перезапуска процесса Celery в выпадающем меню
- Либо в консоли сервера выполнить команду touch ~/celery.na4u.ru/reload
Как настроить Celery в Django
В этом руководстве по использованию Celery совместно с Django я расскажу:
- Как настроить Celery с Django.
- Как протестировать Celery-задачу в Django-оболочке.
- Где контролировать работу Celery-приложения.
Вы можете использовать на исходный код проекта из этого репозитория.
Зачем приложению на Django нужен Celery
Celery нужен для запуска задач в отдельном рабочем процессе ( worker ), что позволяет немедленно отправить HTTP-ответ пользователю в веб-процессе (даже если задача в рабочем процессе все еще выполняется). Цикл обработки запроса не будет заблокирован, что повысит качество взаимодействия с пользователем.
Ниже приведены некоторые примеры использования Celery:
- Вы создали приложение с функцией отправки комментариев, в которых пользователь может использовать символ @, чтобы упомянуть другого пользователя, после чего последний получит уведомление по электронной почте. Если пользователь упоминает 10 человек в своем комментарии, веб-процессу необходимо обработать и отправить 10 электронных писем. Иногда это занимает много времени (сеть, сервер и другие факторы). В данном случае Celery может организовать отправку писем в фоновом режиме, что в свою очередь позволит вернуть HTTP-ответ пользователю без ожидания.
- Нужно создать миниатюру загруженного пользователем изображения? Такую задачу стоит выполнить в рабочем процессе.
- Вам необходимо делать что-то периодически, например, генерировать ежедневный отчет, очищать данные истекшей сессии. Используйте Celery для отправки задач рабочему процессу в назначенное время.
Когда вы создаете веб-приложение, постарайтесь сделать время отклика не более, чем 500мс (используйте New Relic или Scout APM), если пользователь ожидает ответа слишком долго, выясните причину и попытайтесь устранить ее. В решении такой проблемы может помочь Celery.
Celery или RQ
RQ (Redis Queue) — еще одна библиотека Python, которая решает вышеуказанные проблемы.
Логика работы RQ схожа с Celery (используется шаблон проектирования производитель/потребитель). Далее я проведу поверхностное сравнение для лучшего понимания, какой из инструментов более подходит для задачи.
- RQ (Redis Queue) проста в освоении, направлена на снижение барьера в использовании асинхронного рабочего процесса. В ней отсутствуют некоторые функции, и она работает только с Redis и Python.
- Celery предоставляет больше возможностей, поддерживает множество различных серверных конфигураций. Одним из минусов такой гибкости является более сложная документация, что довольно часто пугает новичков.
Я предпочитаю Celery, поскольку он замечательно подходит для решения многих проблем. Данная статья написана мной, чтобы помочь читателю (особенно новичку) быстро изучить Celery!
Брокер сообщений и бэкенд результатов
Брокер сообщений — это хранилище, которое играет роль транспорта между производителем и потребителем.
Из документации Celery рекомендуемым брокером является RabbitMQ, потому что он поддерживает AMQP (расширенный протокол очереди сообщений).
Так как во многих случаях нам не нужно использовать AMQP, другой диспетчер очереди, такой как Redis, также подойдет.
Бэкенд результатов — это хранилище, которое содержит информацию о результатах выполнения Celery-задач и о возникших ошибках.
Здесь рекомендуется использовать Redis.
Как настроить Celery
Celery не работает на Windows. Используйте Linux или терминал Ubuntu в Windows.
Далее я покажу вам, как импортировать Celery worker в ваш Django-проект.
Мы будем использовать Redis в качестве брокера сообщений и бэкенда результатов, что немного упрощает задачу. Но вы свободны в выборе любой другой комбинации, которая удовлетворяет требованиям вашего приложения.
Используйте Docker для подготовки среды разработки
Если вы работаете в Linux или Mac, у вас есть возможность использовать менеджер пакетов для настройки Redis (brew, apt-get install), однако я хотел бы порекомендовать вам попробовать применить Docker для установки сервера redis.
- Вы можете скачать Docker-клиент здесь.
- Затем попробуйте запустить службу Redis $ docker run -p 6379: 6379 —name some-redis -d redis
Команда выше запустит Redis на 127.0.0.1:6379.
- Если вы намерены использовать RabbitMQ в качестве брокера сообщений, вам нужно изменить только приведенную выше команду.
- Закончив работу с проектом, вы можете закрыть Docker-контейнер — окружение вашей рабочей машины по-прежнему будет чистым.
Теперь импортируем Celery в наш Django-проект.
Создание Django-проекта
Рекомендую создать отдельное виртуальное окружение и работать в нем.
$ pip install django==3.1 $ django-admin startproject celery_django $ python manage.py startapp pollsНиже представлена структура проекта.
├── celery_django │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── polls ├── __init__.py ├── admin.py ├── apps.py ├── migrations │ └── __init__.py ├── models.py ├── tests.py └── views.pyФайл celery.py
Давайте приступим к установке и настройке Celery.
pip install celery==4.4.7 redis==3.5.3 flower==0.9.7 Создайте файл celery_django/celery.py рядом с celery_django/wsgi.py.
""" Файл настроек Celery https://docs.celeryproject.org/en/stable/django/first-steps-with-django.html """ from __future__ import absolute_import import os from celery import Celery # этот код скопирован с manage.py # он установит модуль настроек по умолчанию Django для приложения 'celery'. os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celery_django.settings') # здесь вы меняете имя app = Celery("celery_django") # Для получения настроек Django, связываем префикс "CELERY" с настройкой celery app.config_from_object('django.conf:settings', namespace='CELERY') # загрузка tasks.py в приложение django app.autodiscover_tasks() @app.task def add(x, y): return x / yФайл __init__.py
Давайте продолжим изменять проект, в celery_django/__init__.py добавьте.
from __future__ import absolute_import, unicode_literals # Это позволит убедиться, что приложение всегда импортируется, когда запускается Django from .celery import app as celery_app __all__ = ('celery_app',)Дополнение settings.py
Поскольку Celery может читать конфигурацию из файла настроек Django, мы внесем в него следующие изменения.
CELERY_BROKER_URL = "redis://127.0.0.1:6379/0" CELERY_RESULT_BACKEND = "redis://127.0.0.1:6379/0"Есть кое-что, о чем следует помнить.
При изучении документации Celery вы вероятно увидите, что broker_url — это ключ конфигурации, который вы должны установить для диспетчера сообщений, однако в приведенном выше celery.py:
- app.config_from_object('django.conf: settings', namespace = 'CELERY') сообщает Celery, чтобы он считывал значение из пространства имен CELERY , поэтому, если вы установите просто broker_url в своем файле настроек Django, этот параметр не будет работать. Правило применяется для всех ключей конфигурации в документации Celery.
- Некоторые конфигурационные ключи различаются между Celery 3 и Celery 4, так что, пожалуйста, загляните в документацию при настройке.
Отправка заданий Celery
После завершение работы с конфигурацией все готово к использованию Celery. Мы будем запускать некоторые команды в отдельном терминале, но я рекомендую вам взглянуть на Tmux, когда у вас будет время.
Сначала запустите Redis-клиент, потом celery worker в другом терминале, celery_django — это имя Celery-приложения, которое вы установили в celery_django/celery.py.
$ celery worker -A celery_django --loglevel=info -------------- celery@DESKTOP-111111 v4.4.7 (cliffs) --- ***** ----- -- ******* ---- Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.27 2021-03-15 15:03:44 - *** --- * --- - ** ---------- [config] - ** ---------- .> app: celery_django:0x7ff07f818ac0 - ** ---------- .> transport: redis://127.0.0.1:6379/0 - ** ---------- .> results: redis://127.0.0.1:6379/0 - *** --- * --- .> concurrency: 4 (prefork) -- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker) --- ***** ----- -------------- [queues] .> celery exchange=celery(direct) key=celery [tasks] . celery_django.celery.addДалее запустим приложение в новом терминале, которое поможет нам отслеживать Celery-задачу (я расскажу об этом чуть позже).
$ flower -A celery_django --port=5555 [I 210315 16:11:39 command:135] Visit me at http://localhost:5555 [I 210315 16:11:39 command:142] Broker: redis://127.0.0.1:6379/0 [I 210315 16:11:39 command:143] Registered tasks: ['celery.accumulate', 'celery.backend_cleanup', 'celery.chain', 'celery.chord', 'celery.chord_unlock', 'celery.chunks', 'celery.group', 'celery.map', 'celery.starmap', 'celery_django.celery.add'] [I 210315 16:11:39 mixins:229] Connected to redis://127.0.0.1:6379/0Затем откройте http://localhost:5555/. Вы должны увидеть информационную панель, на которой отображаются детали выполнения рабочего процесса Celery.
Теперь войдем в Django shell и попробуем отправить Celery несколько задач.
$ python manage.py migrate $ python manage.py shell . >>> from celery_django.celery import add >>> task = add.delay(1, 2)Рассмотрим некоторые моменты:
- Мы используем xxx.delay для отправки сообщения брокеру. Рабочий процесс получает эту задачу и выполняет ее.
- Когда вы нажимаете клавишу enter для ввода task = add.delay(1, 2) , кажется, что команда быстро завершает выполнение (отсутствие блокировки), но метод добавления все еще активен в рабочем процессе Celery.
- Если вы проверите вывод терминала, где был запущен Celery, то увидите что-то вроде этого:
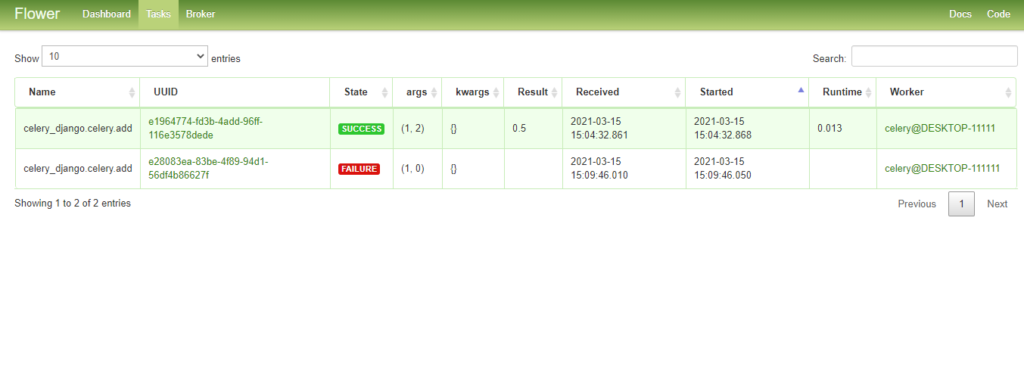
[2021-03-15 15:04:32,859: INFO/MainProcess] Received task: celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578de de] [2021-03-15 15:04:32,882: INFO/ForkPoolWorker-1] Task celery_django.celery.add[e1964774-fd3b-4add-96ff-116e3578dede] s ucceeded in 0.013418699999988348s: 0.5Рабочий процесс получил задачу в 15:04:32, и она была успешно выполнена.
Думаю, теперь у вас уже есть базовое представление об использовании Celery. Попробуем ввести еще один блок кода.>>> print(task.state, task.result) SUCCESS 0.5Затем давайте попробуем вызвать ошибку в Celery worker и посмотрим, что произойдет.
>>> task = add.delay(1, 0) >>> type(task) celery.result.AsyncResult >>> task.state 'FAILURE' >>> task.result ZeroDivisionError('division by zero')Как видите, результатом вызова метода delay является экземпляр AsyncResult.
Мы можем использовать его следующим образом:
- Проверить состояние задачи.
- Узнать возвращенное значение (результат) или сведения об исключении.
- Получить другие метаданные.
Мониторинг Celery с помощью Flower
Flower позволяет отобразить информацию о работу Celery более наглядно на веб-странице с дружественным интерфейсом. Это значительно упрощает понимание происходящего, поэтому я хочу обратить внимание на Flower, прежде чем углубиться в дальнейшее рассмотрение Celery.
URL-адрес панели управления: http://127.0.0.1:5555/. Откройте страницу задач — Tasks.
При изучении Celery довольно полезно использовать Flower для лучшего понимания деталей.
Когда вы развертываете свой проект на сервере, Flower не является обязательным компонентом. Я имею в виду, что вы можете напрямую использовать команды Celery, чтобы управлять приложением и проверять статус рабочего процесса.Заключение
В этой статье я рассказал об основных аспектах Celery. Надеюсь, что после прочтения вы стали лучше понимать процесс работы с ним. Исходный код проекта доступен по ссылке в начале статьи.