Как работает HashMap?
Один из популярнейших вопросов, потому что содержит много нюансов. Лучше всего подготовиться к нему помогает чтение исходного кода HashMap . Реализация подробно рассмотрена во множестве статей, например на хабре.
Нюансы которые стоит повторить и запомнить:
�� Общий принцип: внутренний массив table , содержащий бакеты (корзины) – списки элементов с одинаковыми пересчитанными хэш-суммами;
�� Пересчет хэш-суммы для умещения int индексов в capacity ячейках table ;
�� rehash – удвоение размера table при достижении threshold ( capacity*loadFactor ) занятых бакетов;
�� Невозможность сжать однажды раздувшийся table ;
�� Два способа разрешения коллизий: используемый в HashMap метод цепочек и альтернатива – открытая адресация;
�� Варианты для многопоточного использования: пересинхронизированная Hashtable и умная ConcurrentHashMap ;
�� Оптимизация Java 8: превращение списка в бакете в дерево при достижении 8 элементов – при большом количестве коллизий скорость доступа растет с O(n) до O(log(n));
�� Явное использование бакета 0 для ключа null ;
�� Связь с HashSet – HashMap , в котором используются только ключи;
�� Нет гарантий порядка элементов;
Обсуждая этот вопрос на интервью вы обязательно затронете особенности методов equals/hashCode. Возможно придется поговорить об альтернативных хранилищах ключ-значение – TreeMap, LinkedHashMap.
Что происходит внутри HashMap.put()?
Мы уже рассматривали хэш-таблицы в целом, теперь рассмотрим в деталях, как новые ключ и значение складываются в HashMap.
1. Вычисляется хэш ключа. Если ключ null , хэш считается равным 0 . Чтобы достичь лучшего распределения, результат вызова hashCode() «перемешивается»: его старшие биты XOR-ятся на младшие.
2. Значения внутри хэш-таблицы хранятся в специальных структурах данных – нодах, в массиве. Из хэша высчитывается номер бакета – индекс для значения в этом массиве. Полученный хэш обрезается по текущей длине массива. Длина – всегда степень двойки, так что для скорости используется битовая операция & .
3. В бакете ищется нода. В ячейке массива лежит не просто одна нода, а связка всех нод, которые туда попали. Исполнение проходит по этой связке (цепочке или дереву), и ищет ноду с таким же ключом. Ключ сравнивается с имеющимися сначала на == , затем на equals .
4. Если нода найдена – её значение просто заменяется новым. Работа метода на этом завершается.
5. Если ноды с таким же ключом в бакете пока нет – добавляемая пара ключ-значение запаковывается в новый объект типа Node, и прикрепляется к структуре существующих нод бакета. Ноды составляют структуру за счет того, что в ноде хранится ссылка на следующий элемент (для дерева – следующие элементы). Кроме самой пары и ссылок, чтобы потом не считать заново, записывается и хэш ключа.
6. В случае, когда структурой была цепочка а не дерево, и длина цепочки превысила 7 элементов – происходит процедура treeification – превращение списка в самобалансирующееся дерево. В случае коллизии это ускоряет доступ к элементам на чтение с O(n) до O(log(n)). У comparable-ключей для балансировки используется их естественный порядок. Другие ключи балансируются по порядку имен их классов и значениям identityHashCode-ов. Для маленьких хэш-таблиц (< 64 бакетов) «одеревенение» заменяется увеличением (см. п.8).
7. Если новая нода попала в пустую ячейку, заняла новый бакет – увеличивается счетчик структурных модификаций. Изменение этого счетчика сообщит всем итераторам контейнера, что при следующем обращении они должны выбросить ConcurrentModificationException .
8. Когда количество занятых бакетов массива превысило пороговое (capacity * load factor), внутренний массив увеличивается вдвое, а для всего содержимого выполняется рехэш – все имеющиеся ноды перераспределяются по бакетам по тем же правилам, но уже с учетом нового размера.
HashMap
HashMap — структура данных, одна из коллекций языка Java. Представляет собой хэш-таблицу. Так называется набор из пар «ключ-значение», где у ключей есть хэши, то есть числовые уникальные идентификаторы. Они высчитываются для каждого ключа.

Освойте профессию «Java-разработчик»
Общее название сущности, которая хранит в себе ключи и значения, — ассоциативный массив. То есть структура данных, похожая на массив, где вместо индексов — ключи. Самый очевидный пример — простая таблица, где заголовок является ключом.
В HashMap ключом может быть практически что угодно, но важен в первую очередь хэш ключа.
Профессия / 14 месяцев
Java-разработчик
Освойте востребованный язык

Для чего нужен HashMap
HashMap пользуются разработчики на Java. Как и все структуры, относящиеся к коллекциям, он нужен в первую очередь для хранения информации и работы с ней. HashMap быстро работает, и большинство операций в нем выполняется за фиксированное время — это происходит благодаря оптимизированному доступу к данным. Как и практически все структуры из Collections Framework, он динамический, то есть его размер не фиксирован — туда можно добавить практически любое количество объектов.
HashMap используется, когда разработчику нужно хранить где-то пары «ключ-значение», при этом иметь возможность быстро получить значение по ключу. Например, имя пользователя и номер его телефона. Если нужно хранить просто список значений, лучше подойдет ArrayList или похожая структура.
Как устроены хэш-таблицы
HashMap — структура из пар «ключ-значение». Внутри это динамический массив ключей. Каждый элемент массива — своеобразная «корзинка», которая хранит связанный список со значением. О том, что собой представляет каждая из этих сущностей, можно почитать в статьях про ArrayList и коллекции.
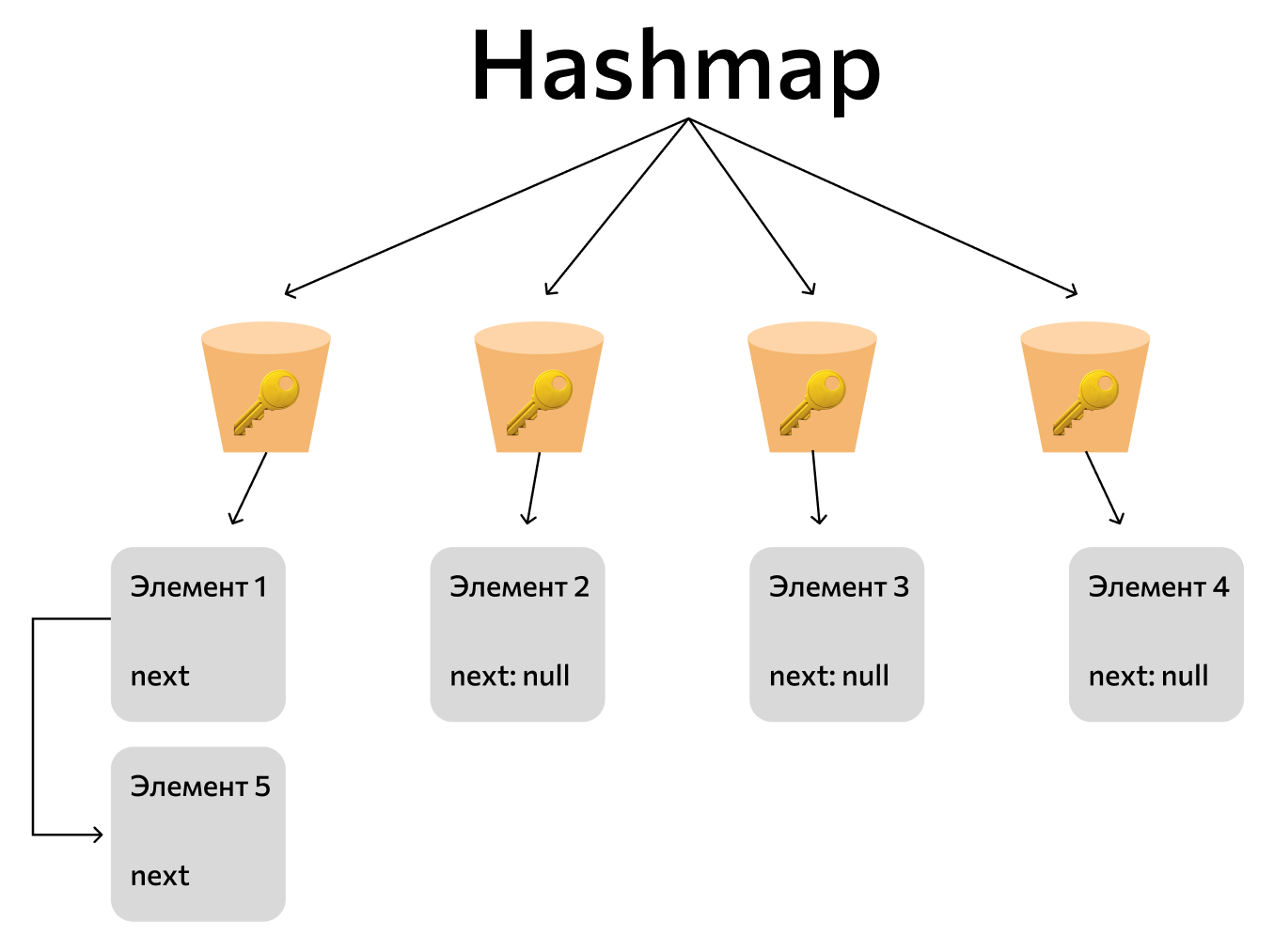
Но HashMap используют для хранения пар — на каждый ключ приходится только одно значение. То есть связанный список будет состоять из одного элемента, а ссылаться этот элемент будет на null — специальное «пустое» значение. Если бы в такой структуре значений было несколько, первое ссылалось бы на второе и так далее — так устроен связанный список.
Связанный список нужен, чтобы избежать коллизий. Мы подробнее расскажем об этом ниже.
Для оптимизации доступа используется хэш ключа. Когда в HashMap добавляют ключ и значение, для ключа сразу высчитывается хэш. По нему определяется позиция в массиве для этой пары: для расчета есть специальные формулы.

Станьте Java-разработчиком
и создавайте сложные сервисы
на востребованном языке
Реализация и свойства HashMap
HashMap — динамическая структура, то есть количество «корзинок» может изменяться. По умолчанию сущность создается с 16 «корзинками», но это поведение можно поменять при создании, для чего надо задать хэш-таблице начальный размер вручную. Когда элементов в ней становится больше, чем корзинок, структура удлиняется — перезаписывает массив на новый, с большей длиной. По умолчанию длина увеличивается вдвое.
У HashMap, как и у всех подобных структур, есть набор своих методов — функций, которые позволяют удобно работать с данными. Для добавления, поиска, перезаписи или удаления элемента есть свои команды; также можно перебирать элементы и ключи и делать многое другое. Благодаря использованию хэшей эти методы работают очень быстро, и для самых популярных из них время выполнения константно, если нет коллизий.
Коллизии и их предотвращение
В идеальной ситуации хэш полностью индивидуален для каждого уникального объекта. Но в реальности хэши могут совпадать у совершенно разных объектов. Это происходит из-за несовершенства существующих алгоритмов.
Может случиться так, что у двух разных ключей окажется одинаковый хэш. Или хэш будет разным, но по формуле позиция для обоих хэшей будет одинаковой. Тогда значения обоих ключей окажутся записаны в одну «корзинку». Это и есть коллизия. Именно из-за коллизий для хранения значений используется связанный список: если бы в массиве просто хранился объект, любая коллизия перезаписала бы текущее значение, а это опасно. А при текущей реализации, даже если случится коллизия, новое значение просто запишется в начало той же «корзинки», не изменив старое.
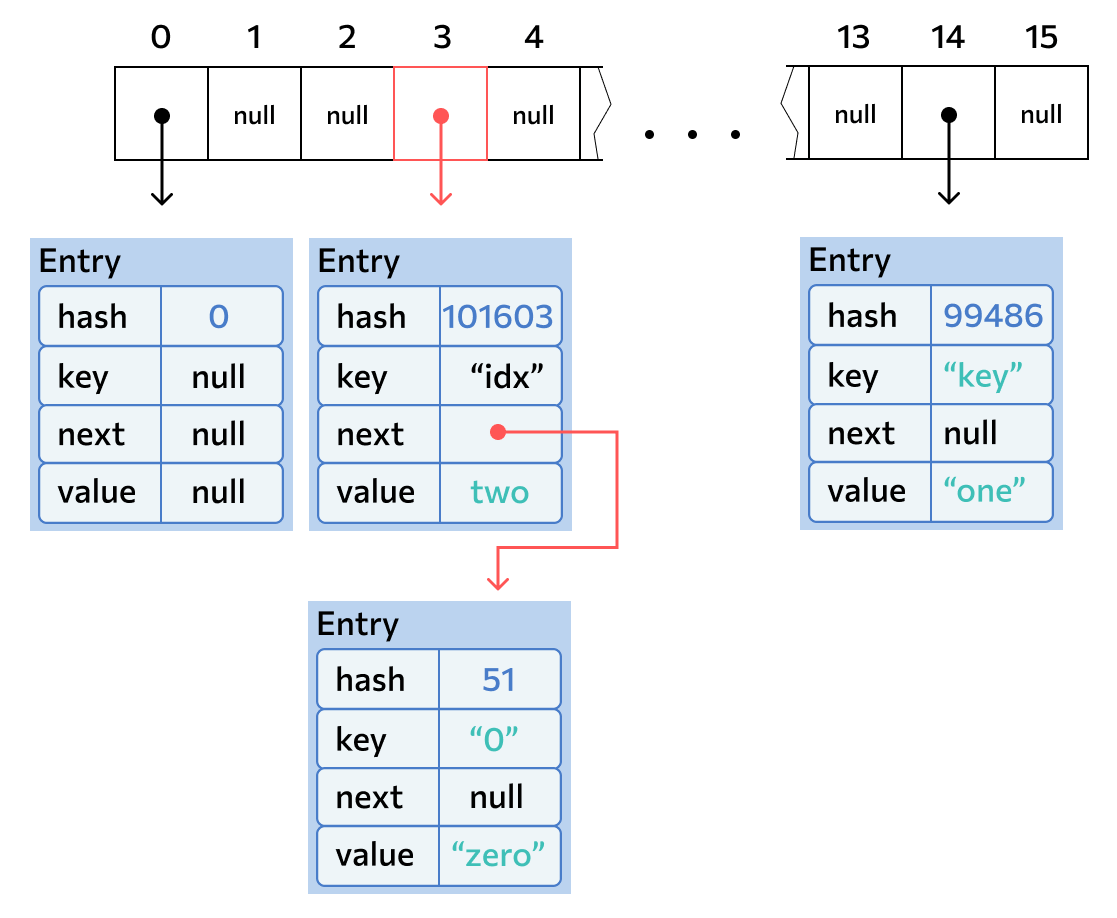
Если такое случится, структура потеряет эффективность и будет работать медленнее, поэтому коллизий все равно лучше не допускать, но сами данные останутся целы.
Отличие от перезаписи
HashMap умеет отличать коллизию от реальной перезаписи элемента. Когда структуре дают новую пару «ключ-значение», она проверяет, есть ли в массиве такие хэши и такие ключи. Результат такой:
- если таких хэшей и ключей нет, в хэш-таблицу просто добавляется новая пара;
- если такой ключ есть, это перезапись — структура переписывает элемент с таким же ключом;
- если такого ключа нет, но хэш есть — это коллизия, новое значение записывается в ту же «корзинку» за предыдущим.
Вы можете узнать больше про структуры данных в Java. Получите новую профессию на курсах и станьте разработчиком на популярном языке.
Java-разработчик
Java уже 20 лет в мировом топе языков программирования. На нем создают сложные финансовые сервисы, стриминги и маркетплейсы. Освойте технологии, которые нужны для backend-разработки, за 14 месяцев.
Map в Java. Hashmap в Java

Привет! Это статья про Карты (Map), один из способов хранения данных в Java.
Что такое карта (Map)
К сожалению, карта (Map) в Java не имеет никакого отношения к картам из реального мира �� Ну или почти никакого.
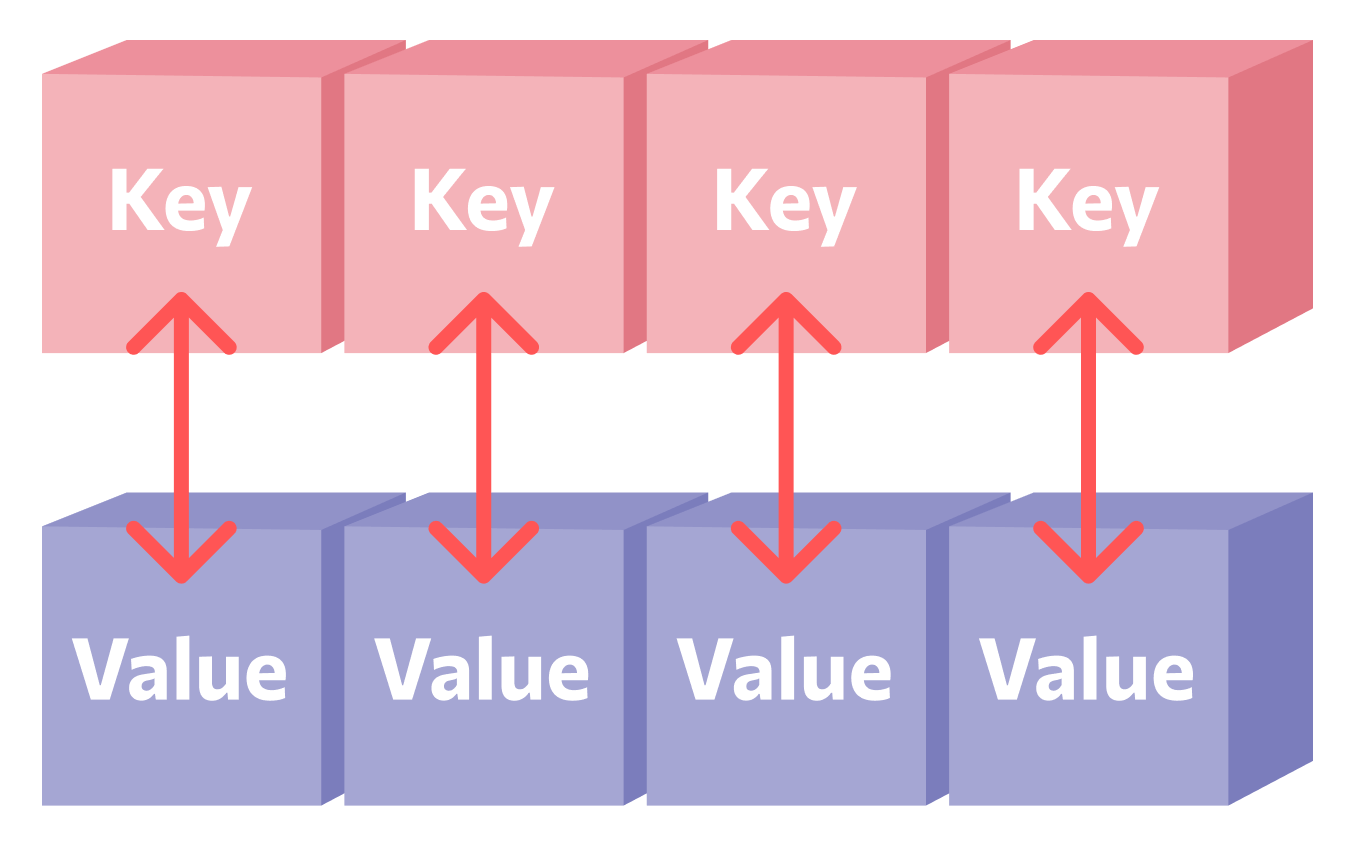
В программировании, карта (Map) — это структура данных, в которой объекты хранятся не по одному, как во всех остальных, а в паре «ключ — значение».

Ну вот представьте, что у нас есть обычный массив строк, в котором хранятся, например, имена людей — Вася, Катя, Лена:

Тем не менее, в карте мы храним пары «ключ-значение» — и обращаться к элементам мы будем не по индексам, а по ключам. В нашем случае ключ — это дата рождения:

Причем ключем может быть что угодно — число, строка или какой-нибудь другой объект.
Какие есть виды карт (map) в Java
Cреди основных реализаций можно назвать:
Если представить в виде диаграммы, будет выглядеть так:
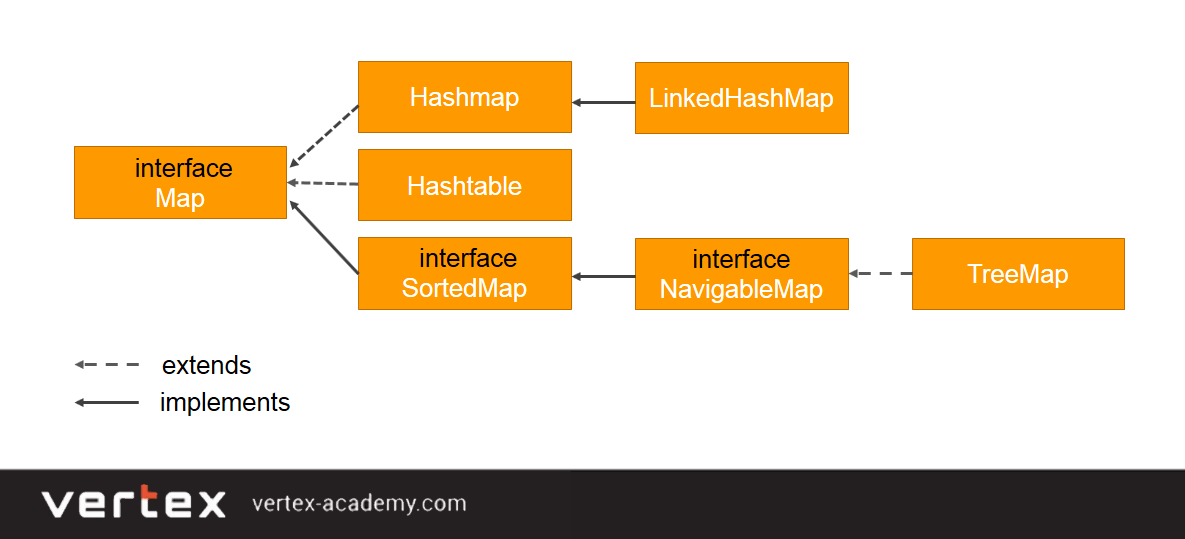
Но для начала этого явно многовато �� Поэтому по теме «map в Java» мы чуть позже напишем несколько статей. А пока эта статья будет как вводная с основным акцентом на HashMap.
Давайте посмотрим, чем они друг от друга отличаются.
- HashMap — хранит значения в произвольном порядке, но позволяет быстро искать элементы карты. Позволяет задавать ключ или значение ключевым словом null.
- LinkedHashMap — хранит значения в порядке добавления.
- TreeMap — сама сортирует значения по заданному критерию. TreeMap используется либо с Comparable элементами, либо в связке с Comparator. Смотрите статью «Интерфейсы Comparable и Comparator».
- Hashtable — как HashMap, только не позволяет хранить null и синхронизирован с точки зрения многопоточности — это значит, что много потоков могут работать безопасно с Hashtable. Но данная реализация старая и медленная, поэтому сейчас уже не используется в новых проектах.
Можно сказать, что для начала Вам хватит знать и уметь работать с HashMap. Именно на ней мы и будем приводить примеры.
Синтаксис HashMap
Создание объекта типа Map похоже на создание коллекций — только мы должны задавать два типа — тип ключа и тип значения: