Общие сведения о таблицах
Таблицы — это неотъемлемая часть любой базы данных, так как именно в них содержатся все сведения и данные. Например, база данных предприятия может содержать таблицу «Контакты», в которой хранятся имена всех поставщиков, их адреса электронной почты и номера телефонов. Так как другие объекты базы данных в значительной степени зависят от таблиц, всегда начинайте разработку базы данных с создания всех таблиц, а уже затем создавайте другие объекты. Прежде чем создавать таблицы в Access, рассмотрите свои требования и определите все таблицы, которые могут потребоваться. Начальные сведения о планировании и разработке баз базы данных см. в статье Основные сведения о создании баз данных.
В этой статье
- Обзор
- Свойства таблиц и полей
- Типы данных
- Отношения между таблицами
- Ключи
- Преимущества использования отношений
Обзор
Обычно реляционная база данных, такая как Access, состоит из нескольких таблиц. В хорошо спроектированной базе данных в каждой таблице хранятся сведения о конкретном объекте, например о сотрудниках или товарах. Таблица состоит из записей (строк) и полей (столбцов). Поля, в свою очередь, содержат различные типы данных: текст, числа, даты и гиперссылки.
- Запись. Содержит конкретные данные, например информацию об определенном работнике или продукте.
- Поле. Содержит данные об одном аспекте элемента таблицы, например имя или адрес электронной почты.
- Значение поля. Каждая запись содержит значение поля, например Contoso, Ltd. или proverka@example.com .
Свойства таблиц и полей
У таблиц и полей также есть свойства, которые позволяют управлять их характеристиками и работой.
1. Свойства таблицы
2. Свойства поля
В базе данных Access свойствами таблицы называются атрибуты, определяющие ее внешний вид и работу. Свойства таблицы задаются на странице свойств таблицы в Конструкторе. Например, вы можете задать для таблицы свойство Режим по умолчанию, чтобы указать, как она должна отображаться по умолчанию.
Свойство поля применяется к определенному полю в таблице и определяет его характеристики или определенный аспект поведения. Некоторые свойства поля можно задать в Режим таблицы. Вы также можете настраивать любые свойства в Конструкторе с помощью области Свойства поля.
Типы данных
У каждого поля есть тип данных. Тип данных поля определяет данные, которые могут в нем храниться (например, большие объемы текста или вложенные файлы).
Тип данных является свойством поля, однако он отличается от других свойств:
- Тип данных поля задается на бланке таблицы, а не в области Свойства поля.
- Тип данных определяет, какие другие свойства есть у этого поля.
- Тип данных необходимо указывать при создании поля. Чтобы создать новое поле в Access, введите данные в новый столбец в режиме таблицы. В таком случае Access автоматически определяет тип данных для поля в зависимости от введенного значения. Если оно не относится к определенному типу, Access выбирает текстовый тип. При необходимости его можно изменить с помощью ленты.
Примеры автоматического определения типа данных
Ниже показано, как выполняется автоматическое определение типа данных в режиме таблицы.
Вводимые данные
Тип данных для поля, назначаемый Access
Вы можете использовать любой допустимый префикс протокола IP. Например, являются допустимыми префиксы http://, https:// и mailto:.
Число, длинное целое
Число, длинное целое
Распознаваемые форматы даты и времени зависят от языкового стандарта.
31 декабря 2016 г.
Распознаваемое обозначение денежной единицы зависит от языкового стандарта.
Отношения между таблицами
Хотя в каждой из таблиц хранятся данные по отдельному объекту, в базе данных Access все они обычно связаны между собой. Ниже приведены примеры таблиц в базе данных.
- Таблица клиентов, содержащая сведения о клиентах компании и их адреса.
- Таблица продаваемых товаров, включающая цены и изображения каждого из них.
- Таблица заказов, служащая для отслеживания заказов клиентов.
Так как данные по разным темам хранятся в отдельных таблицах, их необходимо как-то связать, чтобы можно было легко комбинировать данные из разных таблиц. Для этого используются связи. Связь — это логическое отношение между двумя таблицами, основанное на их общих полях. Дополнительные сведения см. в статье Руководство по связям между таблицами.
Ключи
Поля, формирующие связь между таблицами, называются ключами. Ключ обычно состоит из одного поля, однако может включать и несколько. Есть два вида ключей.
- Первичный ключ. В таблице может быть только один первичный ключ. Он состоит из одного или нескольких полей, однозначно определяющих каждую запись в этой таблице. Часто в качестве первичного ключа используется уникальный идентификатор, порядковый номер или код. Например, в таблице «Клиенты» каждому клиенту может быть назначен уникальный код клиента. Поле кода клиента является первичным ключом этой таблицы. Если первичный ключ состоит из нескольких полей, он обычно включает уже существующие поля, формирующие в сочетании друг с другом уникальные значения. Например, в таблице с данными о людях в качестве первичного ключа можно использовать сочетание фамилии, имени и даты рождения. Дополнительные сведения см. в статье Добавление и изменение первичного ключа таблицы.
- Внешний ключ. В таблице также может быть один или несколько внешних ключей. Внешний ключ содержит значения, соответствующие значениям первичного ключа другой таблицы. Например, в таблице «Заказы» каждый заказ может включать код клиента, соответствующий определенной записи в таблице «Клиенты». Поле «Код клиента» является внешним ключом таблицы «Заказы».
Соответствие значений между полями ключей является основой связи между таблицами. С помощью связи между таблицами можно комбинировать данные из связанных таблиц. Предположим, есть таблицы «Заказчики» и «Заказы». В таблице «Заказчики» каждая запись идентифицируется полем первичного ключа — «Код».
Чтобы связать каждый заказ с клиентом, вы можете добавить в таблицу «Заказы» поле внешнего ключа, соответствующее полю «Код» в таблице «Заказчики», а затем создать связь между этими двумя ключами. При добавлении записи в таблицу «Заказы» можно было бы использовать значение кода клиента из таблицы «Заказчики». При просмотре каких-либо данных о клиенте, сделавшем заказ, связь позволяла бы определить, какие данные из таблицы «Заказчики» соответствуют тем или иным записям в таблице «Заказы».
1. Первичный ключ, который определяется по значку ключа рядом с именем поля.
2. Внешний ключ (определяется по отсутствию значка ключа)
Если ожидается, что для каждого представленного в таблице уникального объекта потребуется несколько значений поля, такое поле добавлять не следует. Обратимся к приведенному выше примеру: если нужно отслеживать размещенные клиентами заказы, не следует добавлять поле в таблицу, поскольку у каждого клиента будет несколько заказов. Вместо этого создается новая таблица для хранения заказов, а затем создаются связи между этими двумя таблицами.
Преимущества использования связей
Раздельное хранение данных в связанных таблицах обеспечивает указанные ниже преимущества.
- Согласованность . Поскольку каждый элемент данных заносится только один раз в одну таблицу, вероятность появления неоднозначных или несогласованных данных снижается. Например, имя клиента будет храниться только в таблице клиентов, а не в нескольких записях в таблице заказов, которые могут стать несогласованными.
- Эффективность . Хранение данных в одном месте позволяет сэкономить место на диске. Кроме того, данные из небольших таблиц извлекаются быстрее, чем из больших. Наконец, если не хранить данные по различным темам в разных таблицах, возникают пустые значения, указывающие на отсутствие данных, или избыточные данные, что может привести к неэффективному использованию места и снижению производительности.
- Простота . Структуру базы данных легче понять, если данные по различным темам находятся в разных таблицах.
Связи между таблицами необходимо иметь в виду еще на этапе планирования таблиц. С помощью мастера подстановок можно создать поле внешнего ключа, если таблица с соответствующим первичным ключом уже существует. Мастер подстановок помогает создать связь. Дополнительные сведения см. в статье Создание и удаление поля подстановки.
Сколько всего желательно иметь таблиц в базе данных
Есть база данных состоящая из 5 таблиц. В одной храниться порядка 10+ млн записей. Количество записей, кот. нужно еще заполнить, порядка 120-150 млн. Где каждая новая запись записывается на опр. время дольше, чем предыдущая, т.к. идет проверка на дубликаты. И поэтому у меня два пути, оставить как есть и ждать пару недель на сохранения инфы. Или же создать, условно говоря пару тысяч таблиц, для мобильности самой бд, т.к. там используются порядка 2-х тысяч разных типов инфы. И вот для каждого типа инфы, будет использоваться своя таблица. Но не уверен, правильное ли решение. Как поступить? Может есть третье, четвертое и т.д. решение.
Отслеживать
8,984 4 4 золотых знака 19 19 серебряных знаков 28 28 бронзовых знаков
задан 8 июл 2018 в 21:15
277 1 1 золотой знак 3 3 серебряных знака 13 13 бронзовых знаков
что вы подразумеваете под типами инфы. Очевидно, если рецепт кексов вы будете записывать в одну таблицу с характеристиками смартфона, создав для них общий перечень полей. то это не лучшее решение.
8 июл 2018 в 21:39
Информация которая храниться в таблице, это цены на определенные товары, а тип информации, это условно говоря, марка телефона, таких марок около 2-х тысяч
8 июл 2018 в 21:54
2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Если вы можете сразу определить тип инфы с помощью безнес логики то лучше обращаться непосредственно к той таблице у которой этот тип инфы определен. Маленький размер таблицы удобнее использовать. Но если бизнес логика хромает, то время затраченное на поиск нужного типа инфы не окупается по сравнению с индексным поиском этого типа инфы в таблице.
Отслеживать
ответ дан 8 июл 2018 в 21:53
8,984 4 4 золотых знака 19 19 серебряных знаков 28 28 бронзовых знаков
Вся таблица выглядит примерно так (максимально упрощенный вариант), id , type , price , date , где типов порядка 2-х тыс. Поиск же происходит по типу и по времени. А тип записи изначально известен, и я подумал, что если оставить эту структуру дальше такой же, как сейчас, то времени на проверку уходит на порядок больше, чем если создать для каждого типа свою таблицу. Скорость увеличилась более чем в 7 раз. Но вот выглядит это все не эстетично. И думаю, что это не то решение, кот. должно быть.
8 июл 2018 в 22:08
Если вы можете оптимизировать запросы, то это может улучшить время на проверку, но не зная броду не лезь в воду как говорится.
8 июл 2018 в 22:23
Есть база данных состоящая из 5 таблиц. В одной храниться порядка 10+ млн записей. Количество записей, кот. нужно еще заполнить, порядка 120-150 млн. Где каждая новая запись записывается на опр. время дольше, чем предыдущая, т.к. идет проверка на дубликаты.
Если я верно понимаю, то речь идёт о процессе заполнения имеющейся структуры имеющимися данными, и хочется ускорить этот процесс.
В таком случае настоятельно рекомендую выполнить импорт данных во временную структуру без проведения каких-либо проверок (Для MySQL импорт 150кк записей такой простой структуры с применением LOAD DATA INFILE выполняется достаточно быстро), затем выполнить средствами SQL требуемые проверки с удалением дубликатов (и предварительно — необходимые индексирования для быстрого выполнения этих операций), и, наконец, перенос заведомо корректных очищенных данных в боевую таблицу. Для указанных количества и структуры цена вопроса — порядка 3-4 часов.
для каждого типа инфы, будет использоваться своя таблица
А вот тут — полная неясность. Но с учётом того, что
тип информации, это условно говоря, марка телефона, таких марок около 2-х тысяч
скорее всего речь ведётся о простом словаре — тогда вполне достаточно к основной таблице цен иметь ещё одну таблицу с типами телефонов. Но уж никак не две тысячи.
Что такое MySQL
В статье мы расскажем о MySQL — инструменте, который помогает хранить данные и управлять ими. Вы узнаете, что такое MySQL и для чего он нужен, а также основные понятия и термины. Терминология важна в понимании принципов работы баз данных и систем их управления (СУБД).
Что такое СУБД, мы подробно рассказывали в статье.
Что такое база данных
База данных — это упорядоченный набор структурированных данных.
Базу данных можно сравнить с галереей в вашем телефоне. Все фотографии упорядочены по дате, и каждая имеет своё уникальное название. Фотографии можно фильтровать не только по дате, но и по геолокации, событиям, людям, времени суток и множеству других критериев. Получается, что галерея — это база данных, а фотографии — это данные, которые база хранит.
Наличие связей между фотографиями говорит нам о том, что галерея — это реляционная база данных (Relation — связь, отношение). Реляционная БД состоит из связанных между собой таблиц. Каждая таблица содержит описание объектов (сущностей) и состоит из строк и столбцов. Количество таблиц в одной базе данных неограничено.
В качестве примера приведём таблицу с фильмами, которые получили премию Оскар:
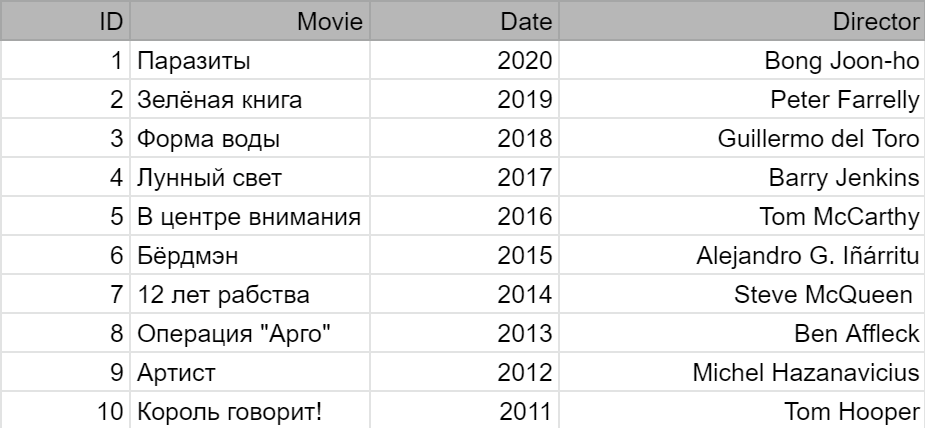
Таблица с данными для примера таблицы SQL
В строке хранится полная информация об объекте. В данном случае объектами являются фильмы. А столбцы содержат часть информации о сущности: имя, год, режиссёр. В базах данных строки часто называют записями, а столбцы колонками или полями.
В каждой таблице может быть уникальное поле, которое идентифицирует запись. Это поле называется первичным ключом. В таблице выше таким ключом является столбец ID. Он является уникальным для каждой записи. Значения в остальных полях могут повторяться, или записи могут полностью совпадать.
Для управления базами данных существуют специальные системы управления — СУБД. Одной из таких систем является MySQL.
Что такое MySQL
MySQL — одна из наиболее используемых систем управления базами данных. MySQL управляет реляционными базами данных, то есть такими, в которых таблицы связаны между собой.
MySQL работает по принципу клиент-сервер. Компьютер пользователя (клиент) отправляет запрос. Сервер баз данных его обрабатывает и предоставляет ответ. Именно поэтому часто можно услышать понятие MySQL-сервер. Это сервер, на котором хранится база данных.
Система MySQL написана на языках программирования C и C++. Для работы MySQL используется язык структурированных запросов SQL.
Что такое SQL
SQL (Structured Query Language) — это язык программирования, при помощи которого можно управлять информацией: добавлять, модифицировать, удалять и получать данные. Запросы к базе данных формируются на языке SQL.
SQL используется не только в MySQL. Многие РСУБД (реляционные системы управления базами данных) используют этот язык для работы с данными. Например:
- Microsoft SQL Server,
- PostgreSQL в облаке,
- Oracle Database,
- MariaDB,
- SQLite.
SQL используется в запросах при обращении к базе данных. Знание SQL позволит вам работать с любой реляционной базой данных, которая использует этот язык.
Как работать с MySQL
Для взаимодействия с базой данных используется специальное ПО. На хостинге Рег.ру используется phpMyAdmin — популярная программа среди разработчиков сайтов. Эта утилита позволяет работать с БД без ввода SQL-запросов. Но умение формировать запросы всё равно не помешает.
Рассмотрим основные команды SQL на примере таблицы с фильмами.
Для создания таблицы используем команду:
CREATE TABLE Movies( ID INT AUTO_INCREMENT PRIMARY KEY, Movie TINYTEXT, Date YEAR, Director TINYTEXT );Добавим запись в таблицу:
INSERT INTO Movies (Movie, Date, Director) VALUES (‘Паразиты’, 2020, ‘Bong Joon-ho’);Выведем содержимое таблицы:
SELECT * FROM Movies;Чтобы внести изменения в запись, выполним команду:
UPDATE Movies SET Movie = ‘Gisaengchung’ WHERE Movie = ‘Паразиты’Почему MySQL популярна
MySQL занимает второе место в рейтинге DB-Engines:
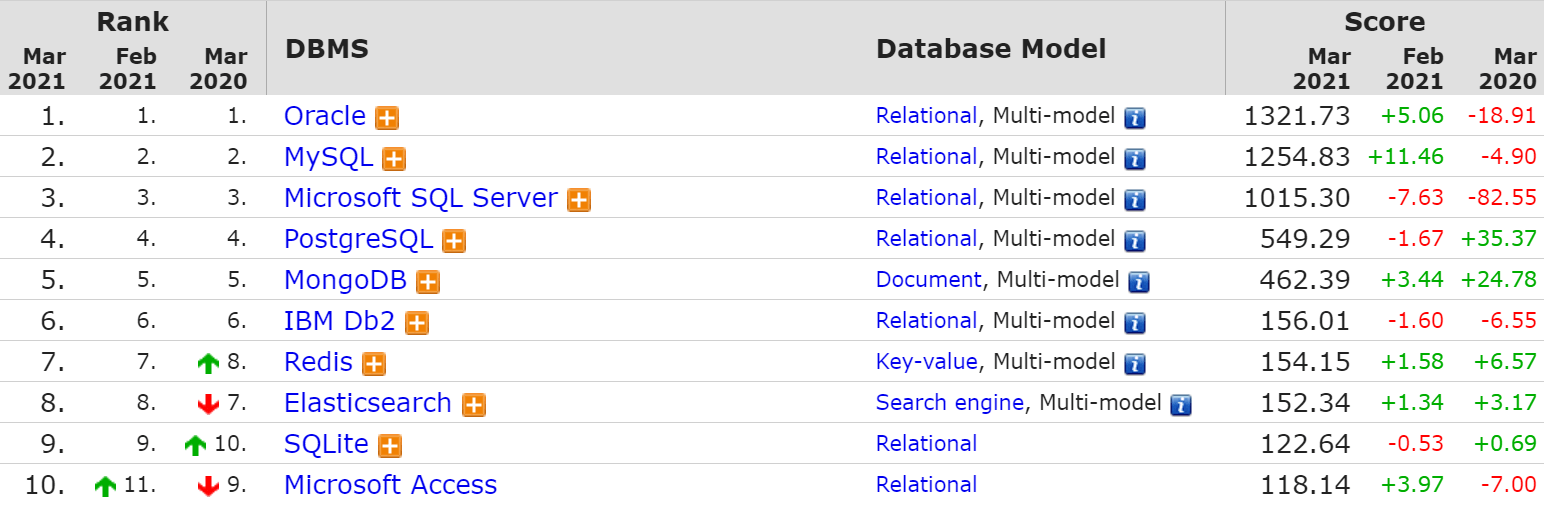
Рейтинг СУБД DB-Engines
Этот рейтинг основан на следующих критериях:
- упоминания в поисковых системах,
- общий интерес,
- вакансии с упоминанием MySQL,
- профили в LinkedIn с упоминанием системы,
- актуальность в социальных сетях.
MySQL поддерживается практически любой CMS. Эта СУБД работает как на Linux, MacOS и Windows, так и на других менее известных операционных системах. Поэтому MySQL очень популярна среди разработчиков сайтов и веб-приложений. Ее используют в своей работе такие крупные компании, как Tesla, Netflix, Cisco, PayPal и другие.
Ни у специалистов с опытом ни у новичков не возникает проблем с поиском ответов на вопросы при работе с MySQL. В сети много обучающей информации и обсуждений на форумах, в том числе на русском языке.
К основным достоинствам MySQL также можно отнести следующие:
- полностью бесплатная СУБД,
- неограниченный многопользовательский режим,
- множество плагинов, облегчающих работу с данной СУБД,
- поддерживает различные типы таблиц (MyISAM, InnoDB, HEAP, MERGE),
- позволяет добавлять до 50 миллионов строк в таблицы.
Однако есть и недостатки:
- ограниченный функционал (не реализованы все возможности SQL);
- возможны проблемы с надежностью хранения и передачи данных из-за открытого исходного кода.
Таким образом, MySQL — это бесплатная простая СУБД с открытым исходным кодом. Конечно, она не лишена минусов, но в большинстве случаев именно MySQL будет оптимальным решением при работе с данными.
Помогла ли вам статья?
Спасибо за оценку. Рады помочь ��
Руководство по проектированию реляционных баз данных (7-9 часть из 15) [перевод]
Я уже показал вам как данные из разных таблиц могут быть связаны при помощи связи по внешнему ключу. Вы видели как заказы связываются с клиентами путем помещения customer_id в качестве внешнего ключа в таблице заказов.
Другой пример связи один-ко-многим – это связь, которая существует между матерью и ее детьми. Мать может иметь множество детей, но каждый ребенок может иметь только одну мать.
(Технически лучше говорить о женщине и ее детях вместо матери и ее детях потому, что, в контексте связи один-ко-многим, мать может иметь 0, 1 или множество потомков, но мать с 0 детей не может считаться матерью. Но давайте закроем на это глаза, хорошо?)
Когда одна запись в таблице А может быть связана с 0, 1 или множеством записей в таблице B, вы имеете дело со связью один-ко-многим. В реляционной модели данных связь один-ко-многим использует две таблицы.
Схематическое представление связи один-ко-многим. Запись в таблице А имеет 0, 1 или множество ассоциированных ей записей в таблице B.
Как опознать связь один-ко-многим?
Если у вас есть две сущности спросите себя:
1) Сколько объектов и B могут относится к объекту A?
2) Сколько объектов из A могут относиться к объекту из B?
Если на первый вопрос ответ – множество, а на второй – один (или возможно, что ни одного), то вы имеете дело со связью один-ко-многим.
Примеры.
Некоторые примеры связи один-ко-многим:
- Машина и ее части. Каждая часть машины единовременно принадлежит только одной машине, но машина может иметь множество частей.
- Кинотеатры и экраны. В одном кинотеатре может быть множество экранов, но каждый экран принадлежит только одному кинотеатру.
- Диаграмма сущность-связь и ее таблицы. Диаграмма может иметь больше, чем одну таблицу, но каждая из этих таблиц принадлежит только одной диаграмме.
- Дома и улицы. На улице может быть несколько домов, но каждый дом принадлежит только одной улице.
В данном случае все настолько просто, что только поэтому может оказаться трудным понимание. Возьмем последний пример с домами. На улице ведь действительно может быть любое количество домов, но у каждого дома именно на этой улице может быть только одна улица (не берем дома, которые на практике принадлежат разным улицам, возьмем, к примеру, дом в центре улицы). Ведь не может конкретно этот дом быть одновременно в двух местах, на двух разных улицах, а мы говорим не про какой-то абстрактный дом вообще, а про конкретный.
8. Связь многие-ко-многим.
Связь многие-ко-многим – это связь, при которой множественным записям из одной таблицы (A) могут соответствовать множественные записи из другой (B). Примером такой связи может служить школа, где учителя обучают учащихся. В большинстве школ каждый учитель обучает многих учащихся, а каждый учащийся может обучаться несколькими учителями.
Связь между поставщиком пива и пивом, которое они поставляют – это тоже связь многие-ко-многим. Поставщик, во многих случаях, предоставляет более одного вида пива, а каждый вид пива может быть предоставлен множеством поставщиков.
Обратите внимание, что при проектировании базы данных вы должны спросить себя не о том, существуют ли определенные связи в данный момент, а о том, возможно ли существование связей вообще, в перспективе. Если в настоящий момент все поставщики предоставляют множество видов пива, но каждый вид пива предоставляется только одним поставщиком, то вы можете подумать, что это связь один-ко-многим, но… Не торопитесь реализовывать связь один-ко-многим в этой ситуации. Существует высокая вероятность того, что в будущем два или более поставщиков будут поставлять один и тот же вид пива и когда это случится ваша база данных — со связью один-ко-многим между поставщиками и видами пива – не будет подготовлена к этому.
Создание связи многие-ко-многим.
Связь многие-ко-многим создается с помощью трех таблиц. Две таблицы – “источника” и одна соединительная таблица. Первичный ключ соединительной таблицы A_B – составной. Она состоит из двух полей, двух внешних ключей, которые ссылаются на первичные ключи таблиц A и B.
Все первичные ключи должны быть уникальными. Это подразумевает и то, что комбинация полей A и B должна быть уникальной в таблице A_B.
Пример проект базы данных ниже демонстрирует вам таблицы, которые могли бы существовать в связи многие-ко-многим между бельгийскими брендами пива и их поставщиками в Нидерландах. Обратите внимание, что все комбинации beer_id и distributor_id уникальны в соединительной таблице.
Таблицы “о пиве”.

Таблицы выше связывают поставщиков и пиво связью многие-ко-многим, используя соединительную таблицу. Обратите внимание, что пиво ‘Gentse Tripel’ (157) поставляют Horeca Import NL (157, AC001) Jansen Horeca (157, AB899) и Petersen Drankenhandel (157, AC009). И vice versa, Petersen Drankenhandel является поставщиком 3 видов пива из таблицы, а именно: Gentse Tripel (157, AC009), Uilenspiegel (158, AC009) и Jupiler (163, AC009).
Еще обратите внимание, что в таблицах выше поля первичных ключей окрашены в синий цвет и имеют подчеркивание. В модели проекта базы данных первичные ключи обычно подчеркнуты. И снова обратите внимание, что соединительная таблица beer_distributor имеет первичный ключ, составленный из двух внешних ключей. Соединительная таблица всегда имеет составной первичный ключ.
Есть еще одна важная вещь на которую нужно знать. Связь многие-ко-многим состоит из двух связей один-ко-многим. Обе таблицы: поставщики пива и пиво – имеют связь один-ко-многим с соединительной таблицей.
Другой пример связи многие-ко-многим: заказ билетов в отеле.
В качестве последнего примера позвольте мне показать как бы могла быть смоделирована таблица заказов номеров гостиницы посетителями.

Соединительная таблица связи многие-ко-многим имеет дополнительные поля.
В этом примере вы видите, что между таблицами гостей и комнат существует связь многие-ко-многим. Одна комната может быть заказана многими гостями с течением времени и с течением времени гость может заказывать многие комнаты в отеле. Соединительная таблица в данном случае является не классической соединительной таблицей, которая состоит только из двух внешних ключей. Она является отдельной сущностью, которая имеет связи с двумя другими сущностями.
Вы часто будете сталкиваться с такими ситуациями, когда совокупность двух сущностей будет являться новой сущностью.
9. Связь один-к-одному.
В связи один-к-одному каждый блок сущности A может быть ассоциирован с 0, 1 блоком сущности B. Наемный работник, например, обычно связан с одним офисом. Или пивной бренд может иметь только одну страну происхождения.
В одной таблице.
Связь один-к-одному легко моделируется в одной таблице. Записи таблицы содержат данные, которые находятся в связи один-к-одному с первичным ключом или записью.
В отдельных таблицах.
В редких случаях связь один-к-одному моделируется используя две таблицы. Такой вариант иногда необходим, чтобы преодолеть ограничения РСУБД или с целью увеличения производительности (например, иногда — это вынесение поля с типом данных blob в отдельную таблицу для ускорения поиска по родительской таблице). Или порой вы можете решить, что вы хотите разделить две сущности в разные таблицы в то время, как они все еще имеют связь один-к-одному. Но обычно наличие двух таблиц в связи один-к-одному считается дурной практикой.
Примеры связи один-к-одному.
- Люди и их паспорта. Каждый человек в стране имеет только один действующий паспорт и каждый паспорт принадлежит только одному человеку.

Проект реляционной базы данных – это коллекция таблиц, которые перелинковываются (связываются) первичными и внешними ключами. Реляционная модель данных включает в себя ряд правил, которые помогают вам создать верные связи между таблицами. Эти правила называются “нормальными формами”. В следующих частях я покажу как нормализовать вашу базу данных.
Какой же вид связи вам нужен?
Примеры связей таблиц на практике. Когда какие-то данные являются уникальными для конкретного объекта, например, человек и номера его паспортов, то имеем дело со связью один-ко-многим. Т.е. в одной таблице мы имеем список неких людей, а в другой таблице у нас есть перечисление номеров паспортов этого человека (напр., паспорт страны проживания и загранпаспорт). И эта комбинация данных уникальная для каждого человека. Т.е. у каждого человека может быть несколько номеров паспортов, но у каждого паспорта может быть только один владелец. Итого: нужны две таблицы.
А если есть некие данные, которые могу быть присвоены любому человеку, то имеем дело со связью многие-ко-многим. Например, есть таблица со списком людей и мы хотим хранить информацию о том, какие страны посетил каждый человек. В данном случае имеется две сущности: люди и страны. Любой человек может посетить любое количество стран равно, как и любая страна может быть посещена любым человеком. Т.е., в данном случае, страна не является уникальными данными для конкретного человека и может использоваться повторно.
В таких случаях использование связи многие-ко-многим с использованием трех таблиц и с хранением общей информации централизованно очень удобно. Ведь если общие данные меняются, то для того, чтобы информация в базе данных соответствовала действительности достаточно подправить ее только в одном месте, т.к. хранится она только в одном месте (таблице), в остальных таблицах имеются лишь ссылки на нее.
А когда у вас есть набор уникальных данных, которые имеют отношение только друг к другу, то храните все в одной таблице. Ваш выбор – связь один-к-одному. Например, у вас есть небольшая коллекция автомобилей и вы хотите хранить информацию о них (цвет, марка, год выпуска и пр.).
- sql
- mysql
- проектирование баз данных