Как соединить 3 таблицы в sql
Чтобы соединить три таблицы в SQL, вы можете использовать оператор JOIN . Оператор JOIN объединяет две таблицы на основе общих столбцов, а при необходимости вы можете объединить несколько таблиц.
Для объединения трех таблиц вам нужно выполнить три операции JOIN . Рассмотрим пример:
SELECT t1.column1, t2.column2, t3.column3 FROM table1 t1 JOIN table2 t2 ON t1.column1 = t2.column1 JOIN table3 t3 ON t2.column2 = t3.column2; Здесь мы объединяем три таблицы: table1, table2 и table3. Мы выбираем определенные столбцы из каждой таблицы, а затем используем оператор JOIN для объединения таблицы table1 и table2, а затем таблицы table2 и table3.
Обратите внимание, что для успешного объединения таблиц необходимо наличие общих столбцов в этих таблицах. Кроме того, если таблицы содержат дублирующиеся строки, то результатом объединения могут быть дублирующиеся строки. Чтобы исключить дубли, можно использовать оператор DISTINCT .
Создание связей по внешнему ключу
В этой статье описывается создание связей внешнего ключа в SQL Server с помощью SQL Server Management Studio или Transact-SQL. Связь создается между двумя таблицами, чтобы связать строки одной таблицы со строками другой.
Разрешения
Создание новой таблицы с внешним ключом требует разрешения CREATE TABLE в базе данных и разрешения ALTER на схему, в которой создается таблица.
Создание внешнего ключа в существующей таблице требует разрешения ALTER на таблицу.
Ограничения и ограничения
- Ограничение внешнего ключа не обязательно должно быть связано только с ограничением первичного ключа в другой таблице. Внешние ключи также могут быть определены, чтобы ссылаться на столбцы ограничения UNIQUE в другой таблице.
- Если столбцу, имеющему ограничение внешнего ключа, задается значение, отличное от NULL, такое же значение должно существовать и в указываемом столбце. В противном случае будет возвращено сообщение о нарушении внешнего ключа. Для обеспечения проверки всех значений сложного ограничения внешнего ключа задайте параметр NOT NULL для всех столбцов, участвующих в индексе.
- Ограничения FOREIGN KEY могут ссылаться только на таблицы в пределах той же базы данных на том же сервере. Межбазовую ссылочную целостность необходимо реализовать посредством триггеров. Дополнительные сведения см. в статье об инструкции CREATE TRIGGER.
- Ограничения FOREIGN KEY могут ссылаться на другие столбцы той же таблицы и считаются ссылками на себя.
- Ограничение FOREIGN KEY, определенное на уровне столбцов, может содержать только один ссылочный столбец. Этот столбец должен принадлежать к тому же типу данных, что и столбец, для которого определяется ограничение.
- Ограничение FOREIGN KEY, определенное на уровне таблицы, должно содержать такое же число ссылочных столбцов, какое содержится в списке столбцов в ограничении. Тип данных каждого ссылочного столбца должен также совпадать с типом соответствующего столбца в списке столбцов.
- Ядро СУБД не имеет предопределенного ограничения на количество ограничений FOREIGN KEY, которые могут содержать ссылки на другие таблицы. Ядро СУБД также не ограничивает количество ограничений FOREIGN KEY, принадлежащих другим таблицам, ссылающимся на определенную таблицу. Но фактическое количество используемых ограничений FOREIGN KEY ограничивается конфигурацией оборудования, базы данных и приложения. Максимальное количество таблиц и столбцов, на которые может ссылаться таблица в качестве внешних ключей (исходящих ссылок), равно 253. SQL Server 2016 (13.x) и более поздних версий увеличивает ограничение числа других таблиц и столбцов, которые могут ссылаться на столбцы в одной таблице (входящей ссылки) с 253 до 10 000. (Требуется уровень совместимости не менее 130.) Увеличение имеет следующие ограничения:
- Превышение 253 ссылок на внешние ключи поддерживается только для операций DELETE и UPDATE DML. Операции MERGE не поддерживаются.
- Таблица со ссылкой внешнего ключа на саму себя по-прежнему ограничена 253 ссылками на внешние ключи.
- Превышение числа в 253 ссылки на внешние ключи в настоящее время недоступно для индексов columnstore, оптимизированных для памяти таблиц или Stretch Database.
Stretch Database устарел в SQL Server 2022 (16.x) и База данных SQL Azure. Эта функция будет удалена в будущей версии ядро СУБД. Избегайте использования этого компонента в новых разработках и запланируйте изменение существующих приложений, в которых он применяется.
Создание связи по внешнему ключу в конструкторе таблиц
Использование SQL Server Management Studio
- В обозревателе объектов щелкните правой кнопкой мыши таблицу, которая будет содержать внешний ключ для связи, и выберите пункт Конструктор. Таблица откроется в окне Конструктор таблиц.
- В меню конструктора таблиц выберите Связи. (См. меню Конструктор таблиц в заголовке или щелкните правой кнопкой мыши пустое место определения таблицы и выберите Связи.)
- В диалоговом окне Связи внешнего ключа нажмите кнопку Добавить. Связь отображается в списке выбранных связей с именем, предоставленным системой, в формате FK_tablename_ >, где имя первой таблицы — имя внешней таблицы ключей, а второе имя таблицы — имя таблицы первичного ключа. Это просто принятое по умолчанию и распространенное соглашение об именах для поля (Name) объекта внешнего ключа.
- Выберите нужную связь в списке Выбранные связи.
- Выберите Спецификация таблиц и столбцов в сетке справа и нажмите кнопку с многоточием (…) справа от свойства.
- В диалоговом окне Таблицы и столбы в раскрывающемся списке Первичный ключ выберите таблицу, которая будет находиться на стороне первичного ключа связи.
- В сетке внизу выберите столбцы, составляющие первичный ключ таблицы. В соседней ячейке сетки справа от каждого столбца выберите соответствующий столбец внешнего ключа таблицы внешнего ключа. Конструктор таблиц автоматически предлагает имя для связи. Чтобы его изменить, отредактируйте содержимое текстового поля Имя связи .
- Нажмите кнопку OК , чтобы создать связь.
- Закройте окно конструктора таблиц и сохраните внесенные изменения, чтобы изменения связи внешнего ключа вступили в силу.
Создание внешнего ключа в новой таблице
Использование Transact-SQL
В следующем примере создается таблица и определяется ограничение внешнего ключа для столбца TempID , ссылающегося на столбец SalesReasonID в таблице Sales.SalesReason базы данных AdventureWorks . Предложения ON DELETE CASCADE и ON UPDATE CASCADE используются для обеспечения распространения изменений, вносимых в таблицу Sales.SalesReason на таблицу Sales.TempSalesReason .
CREATE TABLE Sales.TempSalesReason ( TempID int NOT NULL, Name nvarchar(50) , CONSTRAINT PK_TempSales PRIMARY KEY NONCLUSTERED (TempID) , CONSTRAINT FK_TempSales_SalesReason FOREIGN KEY (TempID) REFERENCES Sales.SalesReason (SalesReasonID) ON DELETE CASCADE ON UPDATE CASCADE ) ;Создание внешнего ключа в существующей таблице
Использование Transact-SQL
В следующем примере создается внешний ключ для столбца TempID , ссылающегося на столбец SalesReasonID в таблице Sales.SalesReason базы данных AdventureWorks .
ALTER TABLE Sales.TempSalesReason ADD CONSTRAINT FK_TempSales_SalesReason FOREIGN KEY (TempID) REFERENCES Sales.SalesReason (SalesReasonID) ON DELETE CASCADE ON UPDATE CASCADE ;Следующие шаги
- Ограничения первичных и внешних ключей
- GRANT (разрешения на базу данных)
- ALTER TABLE
- CREATE TABLE
- ALTER TABLE table_constraint.
Объединение таблиц при запросе (JOIN) в SQL
С помощью команды SELECT можно выбрать данные не только из одной таблицы, но и нескольких. Такая задача появляется довольно часто, потому что принято разносить данные по разным таблицам в зависимости от хранимой в них информации. К примеру, в одной таблице хранится информация о пользователях, во второй таблице о должностях компании, а в третьей и четвёртой о поставщиках и клиентах. Данные разбивают на таблицы так, чтобы с одной стороны получить самую высокую скорость выполнения запроса, а с другой стороны избежать ненужных объединений, которые снижают производительность.
Чем больше столбцов в таблице — тем сильнее падает скорость выборки из неё. Поэтому стараются делать в каждой таблице не больше 5-10 столбцов. Но чем сильнее данные разбиваются на разные таблицы, тем больше придётся делать объединений внутри запросов, что тоже снизит скорость получения выборки и увеличит нагрузку на базу.
Приведём пример запроса с объединением данных из двух таблиц. Для этого предположим, что существует две таблицы. Первая таблица будет иметь название USERS и будет иметь два столбца: ID и именами пользователей:
+-----------+ | USERS | +-----------+ | ID | NAME | +----+------+ | 1 | Мышь | +----+------+ | 2 | Кот | +----+------+
Вторая таблица будет называться FOOD и будет содержать два столбца: USER_ID и NAME. В этой таблице будет содержаться список любимых блюд пользователей из первой таблицы. В столбце USER_ID содержится ID пользователя, а в столбце PRODUCT находится название любимого блюда.
+-------------------+ | FOOD | +-------------------+ | USER_ID | PRODUCT | +---------+---------+ | 1 | Сыр | +---------+---------+ | 2 | Молоко | +---------+---------+
Условимся что поле ID в таблице USERS и поле USER_ID в таблице FOOD являются первичными ключами (то есть имеют уникальные значения, которые не повторяются). Теперь попробуем использовать логику и найти любимое блюдо пользователя «Мышь», используя обе таблицы. Для этого мы сначала посмотрим в первую таблицу и найдём ID пользователя под именем «Мышь», а затем найдём название продукта под таким же ID во второй таблице. Объединяющие SQL запросы работают по такой же логике: нужен столбец, в по которому таблицы могут быть объединены.
Продемонстрируем запрос, объединяющий таблицы по столбцам ID и USER_ID:
SELECT * FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;Разберём команду по словам. Начинается она как обычная выборка из одной таблицы со слов «SELECT * FROM USERS». Но затем идёт слово INNER, которое означает тип объединения. Существует три типа объединения таблиц: INNER, LEFT, RIGHT. Все они связаны с тем, что некоторым строкам в одной таблице может не найтись соответствующей строки во второй таблице. В таком случае при использовании «INNER» из результатов запроса будет удалены все строки, которым не нашлась соответствующая пара в другой таблице. Если же использовать вместо «INNER» слово «LEFT» или «RIGHT», то будут удалены строки, которые не нашли совпадение из первой (левой) или второй (правой) таблицы.
После слова «INNER» стоит слово «JOIN» (которое переводится с английского как «ПРИСОЕДИНИТЬ»). После слова «JOIN» стоит название таблицы, которая будет присоединена. В нашем случае это таблица FOOD. После названия таблицы стоит слово «ON» и равенство USERS.ID=FOOD.USER_ID, которое задаёт правило присоединения. При выполнении выборки будут объединены две таблицы так, чтобы значения в столбце ID таблицы USERS равнялось значению USER_ID таблицы FOOD.
В результате выполнения этого SQL запроса мы получим таблицу с четырьмя столбцами:
+----+------+---------+---------+ | ID | NAME | USER_ID | PRODUCT | +----+------+---------+---------+ | 1 | Мышь | 1 | Сыр | +----+------+---------+---------+ | 2 | Кот | 2 | Молоко | +----+------+---------+---------+
Предлагаем модифицировать запрос, потому что нам не нужны все четыре столбца. Уберём столбцы ID и USER_ID. Для этого вместо * в команде SELECT поставим название столбцов. Но необходимо сделать это, ставя сначала название таблицы и через точку название столбца. Чтобы получилось так:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;Теперь результат будет компактнее. И благодаря уменьшенному количеству запрашиваемых данных, результат будет получаться из базы быстрее:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+ | Кот | Молоко | +------+---------+
Если в двух таблицах имеются столбцы с одинаковыми названиями, то будет показан только последний столбце с таким названием. Чтобы этого не происходило, выбирайте определённый столбцы и используйте команду «AS» с помощью которой можно переименовать столбец в результатах выборки.
Давайте теперь решим логическую задачу, которую поставили в начале статьи. Попробуем выбрать в этой объединённой таблице только одну строку, которая соответствует пользователю «Мышь». Для этого используем условие WHERE в SQL запросе:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID` WHERE `USERS`.`NAME` LIKE 'Мышь';Обратите внимание, что в условии WHERE название полей так же необходимо ставить вместе с названием таблицы через точку: USERS.NAME. В результате выполнения этого запроса появится такой результат:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+
Соединение таблиц
Нередко возникает необходимость в одном запросе получить данные сразу из нескольких таблиц. Для сведения данных из разных таблиц мы можем использовать разные способы. В данной статье рассмотрим не самый распространный, однако довольно простой способ, который представляет неявное соединение таблиц.
Допустим, у нас есть следующие таблицы, которые связаны между собой связями:
CREATE TABLE Products ( Id INT AUTO_INCREMENT PRIMARY KEY, ProductName VARCHAR(30) NOT NULL, Manufacturer VARCHAR(20) NOT NULL, ProductCount INT DEFAULT 0, Price DECIMAL NOT NULL ); CREATE TABLE Customers ( Id INT AUTO_INCREMENT PRIMARY KEY, FirstName VARCHAR(30) NOT NULL ); CREATE TABLE Orders ( Id INT AUTO_INCREMENT PRIMARY KEY, ProductId INT NOT NULL, CustomerId INT NOT NULL, CreatedAt DATE NOT NULL, ProductCount INT DEFAULT 1, Price DECIMAL NOT NULL, FOREIGN KEY (ProductId) REFERENCES Products(Id) ON DELETE CASCADE, FOREIGN KEY (CustomerId) REFERENCES Customers(Id) ON DELETE CASCADE );
Здесь таблицы Products и Customers связаны с таблицей Orders связью один ко многим. Таблица Orders в виде внешних ключей ProductId и CustomerId содержит ссылки на столбцы Id из соответственно таблиц Products и Customers. Также она хранит количество купленного товара (ProductCount) и и по какой цене он был куплен (Price). И кроме того, таблицы также хранит в виде столбца CreatedAt дату покупки.
Пусть эти таблицы будут содержать следующие данные:
INSERT INTO Products (ProductName, Manufacturer, ProductCount, Price) VALUES ('iPhone X', 'Apple', 2, 76000), ('iPhone 8', 'Apple', 2, 51000), ('iPhone 7', 'Apple', 5, 42000), ('Galaxy S9', 'Samsung', 2, 56000), ('Galaxy S8', 'Samsung', 1, 46000), ('Honor 10', 'Huawei', 2, 26000), ('Nokia 8', 'HMD Global', 6, 38000); INSERT INTO Customers(FirstName) VALUES ('Tom'), ('Bob'),('Sam'); INSERT INTO Orders (ProductId, CustomerId, CreatedAt, ProductCount, Price) VALUES ( (SELECT Id FROM Products WHERE ProductName='Galaxy S8'), (SELECT Id FROM Customers WHERE FirstName='Tom'), '2018-05-21', 2, (SELECT Price FROM Products WHERE ProductName='Galaxy S8') ), ( (SELECT Id FROM Products WHERE ProductName='iPhone X'), (SELECT Id FROM Customers WHERE FirstName='Tom'), '2018-05-23', 1, (SELECT Price FROM Products WHERE ProductName='iPhone X') ), ( (SELECT Id FROM Products WHERE ProductName='iPhone X'), (SELECT Id FROM Customers WHERE FirstName='Bob'), '2018-05-21', 1, (SELECT Price FROM Products WHERE ProductName='iPhone X') );Теперь соединим две таблицы Orders и Customers:
SELECT * FROM Orders, Customers;
При такой выборке каждая строка из таблицы Orders будет соединяться с каждой строкой из таблицы Customers. То есть, получится перекрестное соединение. Например, в Orders три строки, а в Customers то же три строки, значит мы получим 3 * 3 = 9 строк:
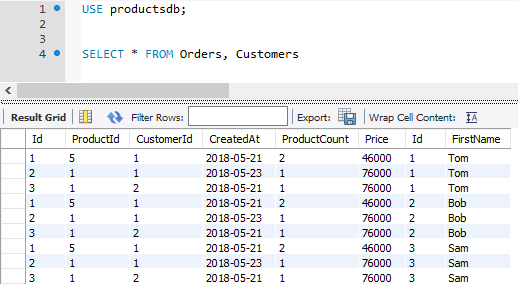
Но вряд ли это тот результат, который хотелось бы видеть. Тем более каждый заказ из Orders связан с конкретным покупателем из Customers, а не со всеми возможными покупателями.
Чтобы решить задачу, необходимо использовать выражение WHERE и фильтровать строки при условии, что поле CustomerId из Orders соответствует полю Id из Customers:
SELECT * FROM Orders, Customers WHERE Orders.CustomerId = Customers.Id;
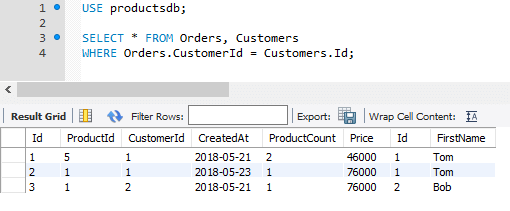
Теперь объединим данные по трем таблицам Orders, Customers и Proucts. То есть получим все заказы и добавим информацию по клиенту и связанному товару:
SELECT Customers.FirstName, Products.ProductName, Orders.CreatedAt FROM Orders, Customers, Products WHERE Orders.CustomerId = Customers.Id AND Orders.ProductId=Products.Id;
Так как здесь нужно соединить три таблицы, то применяются как минимум два условия. Ключевой таблицей остается Orders, из которой извлекаются все заказы, а затем к ней подсоединяется данные по клиенту по условию Orders.CustomerId = Customers.Id и данные по товару по условию Orders.ProductId=Products.Id
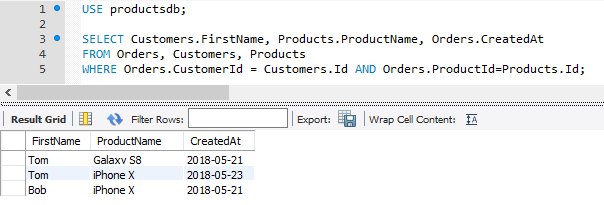
В данном случае названия таблиц сильно увеличивают код, но мы его можем сократить за счет использования псевдонимов таблиц:
SELECT C.FirstName, P.ProductName, O.CreatedAt FROM Orders AS O, Customers AS C, Products AS P WHERE O.CustomerId = C.Id AND O.ProductId=P.Id;
Если необходимо при использовании псевдонима выбрать все столбцы из определенной таблицы, то можно использовать звездочку:
SELECT C.FirstName, P.ProductName, O.* FROM Orders AS O, Customers AS C, Products AS P WHERE O.CustomerId = C.Id AND O.ProductId=P.Id;