В чем состоит процесс установки gnu проекта
Эти рекомендации предназначены для того, чтобы объяснить, что требуется от дистрибутива устанавливаемой системы (такого, как дистрибутив GNU/Linux), чтобы он мог считаться свободным, и помочь разработчикам дистрибутивов привести свои дистрибутивы в соответствие этим требованиям.
Эти рекомендации не полны. Мы упомянули аспекты, о которых нам сейчас известно, но мы уверены, что есть и другие. Мы будем добавлять их по мере того, как мы будем с ними сталкиваться.
Мы хотели бы поблагодарить проект Fedora за помощь в формулировке этих критериев и разрешение воспользоваться его рекомендациями по лицензированию дистрибутива как основой для этого документа.
Эту страницу поддерживает Лаборатория лицензирования Фонда свободного программного обеспечения. Вы можете поддержать нашу работу пожертвованием в ФСПО. Есть вопрос, на который здесь не ответили? Обратитесь к нашим материалам по лицензированию или свяжитесь с лабораторией по адресу licensing@fsf.org.
Полнота дистрибутива
В нашем списке дистрибутивов показано, какие системы вы можете установить на компьютере. Таким образом, список включает только дистрибутивы, которые полны сами по себе и готовы к применению. Если дистрибутив неполон — если он требует дополнительной доработки или предполагается установка других программ — то он в этом списке не перечисляется, даже если это свободные программы.
В частности, свободный дистрибутив должен быть самостоятелен. Это значит, что вы должны быть в состоянии разрабатывать и собирать систему средствами, которые вам предоставляет система. Как следствие, свободный дистрибутив системы не может включать свободные программы, которые могут быть оттранслированы только с использованием несвободных программ.
Мы делаем исключение из этого требования для дистрибутивов небольших систем, которые проектируются для устройств с ограниченными ресурсами, например беспроводных маршрутизаторов. Для свободных дистрибутивов небольших систем не обязательно быть самостоятельными или полными, потому что вести разработку на такой системе непрактично; но должна быть возможность разрабатывать и собирать ее на установленном свободном дистрибутиве полной системы из нашего списка дистрибутивов, возможно, с помощью свободных средств, распространяемых вместе с самим дистрибутивом небольшой системы.
Правила лицензирования
В “практически значимую информацию” входят программы, документация, шрифты и другие данные, которые имеют прямое функциональное приложение. В нее не входят художественные работы, имеющие эстетическое (а не функциональное) назначение, а также выражения мнений или суждений.
Вся практически значимая информация в свободном дистрибутиве должна быть доступна в исходной форме. (“Исходная форма” означает форму информации, предпочтительную для внесения в нее изменений.)
Информация и ее исходная форма должны предоставляться под соответствующей лицензией свободных программ. Мы оцениваем конкретные лицензии и заносим наши заключения в наш список лицензий, где отдельно перечислены лицензии, подходящие для программ, документации, шрифтов и других полезных работ. Если такая работа выпускается под дизъюнкцией лицензий, она свободна, если свободна по меньшей мере одна из ее лицензий; разработчики системы должны следовать условиям соответствующих лицензий свободных программ, когда распространяют или модифицируют эту работу.
Дистрибутив свободной системы не должен ни подталкивать пользователей к получению какой бы то ни было несвободной практически значимой информации, ни поощрять их к этому. В системе не должно быть ни “разделов” для несвободных программ, ни конкретных указаний по установке несвободных программ. Также дистрибутив не должен ссылаться на каталоги программ третьих сторон, у которых нет намерения размещать только свободные программы; даже если сегодня в них есть только свободные программы, завтра это может измениться. Программы в системе не должны предлагать установку несвободных дополнений, документации и так далее.
Например, дистрибутив свободной системы не может содержать браузеры, которые реализуют EME — функции браузера, спроектированные для загрузки модулей цифрового управления ограничениями.
Некоторые несвободные дистрибутивы предлагают возможность исключения несовободных пакетов. Это большой шаг вперед, поскольку становится гораздо легче избегать их, при условии что возможность реализована в дистрибутиве правильно. Однако несвободные пакеты, тем не менее, включаются в дистрибутив. Более того, мы знаем, что большинство пользователей не очень привержены свободе программ и не будут отвергать пакеты, которые кажутся удобными, только потому, что они несвободны. Говоря практически, перечислять эти дистрибутивы как свободные означало бы по большей части вести людей к установке несвободных программ. По этим причинам мы не включаем их в этот список.
Сейчас в большинстве свободных дистрибутивов систем очень много файлов; для большинства коллективов практически невозможно переучесть их все. В прошлом некоторые несвободные файлы случайно были включены в дистрибутивы свободных систем. Мы не вычеркиваем дистрибутив из списка на этом основании; вместо этого мы только просим, чтобы разработчики дистрибутива впредь добросовестно прилагали усилия к тому, чтобы не включались новые несвободные программы, и намеревались удалять такие программы, если они впоследствии будут обнаружены.
Определенные случаи лицензирования заслуживают особого внимания людей, создающих или обсуждающих свободные дистрибутивы программ; они обсуждаются ниже.
Несвободные программы в устройствах
Некоторые приложения и драйверы требуют программ для устройств, чтобы функционировать, и бывает, что такие программы поставляются только в виде машинного кода под несвободной лицензией. Мы называем такие программы для устройств “кляксами”. В большинстве систем GNU/Linux они обычно прилагаются к некоторым драйверам в Linux (ядре). Такие программы для устройств из свободных дистрибутивов систем нужно удалять.
Кляксы могут принимать разные формы. Иногда они поставляются в отдельных файлах. Иногда они вкрапляются в сам исходный текст драйвера — например, она может быть закодирована как большой массив чисел. Но независимо от того, как она закодирована, любую несвободную программу нужно из свободной системы удалять.
(Пояснение: не любой массив чисел в драйвере представляет собой программу для устройства. Важно понимать назначение данных, чтобы решить, допустимы ли они в свободной системе.)
Брайан Брейзил, Джефф Моу и Александр Олива разработали ряд программ для удаления клякс из обычной версии Linux. Они могут быть вам полезны, если вы хотите разрабатывать собственный свободный дистрибутив GNU/Linux — хотя мы рекомендуем присоединиться к разработке существующего свободного дистрибутива, а не дробить усилия, создавая новый. Полный исходный текст свободной от клякс версии Linux тоже доступен; вы можете узнать об этом подробнее из “Каталога свободных программ”.
Нефункциональные данные
Данные нефункционального назначения, которые не выполняют практических задач, являются скорее украшением программ системы, чем их частью. Таким образом, мы не настаиваем на критериях свободы лицензии для нефункциональных данных. Их можно включать в свободный дистрибутив системы постольку, поскольку их лицензия позволяет вам копировать и распространять их как в коммерческих, так и в некоммерческих целях. Например, есть базовые программы для игр, которые выпущены под GNU GPL и которые сопровождает игровая информация — карта вымышленного мира, графика для игры и так далее,— выпущенная под такой лицензией на буквальное распространение. Такого рода данные могут быть частью свободного дистрибутива системы, даже если их лицензия не является свободной, потому что это нефункциональные данные.
Товарные знаки
С некоторыми программами ассоциируются товарные знаки. Например, название программы может быть товарным знаком или программа может демонстрировать товарный знак-эмблему. Часто применение этих знаков некоторым образом контролируется; в частности, разработчиков обычно просят удалить ссылки на товарный знак из программы, когда они вносят в нее изменения.
В предельных случаях эти ограничения могут по существу сделать программу несвободной. Просить вас удалить товарный знак из модифицированной программы будет нечестно, если этот товарный знак рассеян повсюду в первоначальном исходном тексте. Однако пока практические требования не чрезмерны, свободные дистрибутивы могут включать эти программы, как с товарными знаками, так и без них.
Подобным образом и сам дистрибутив может содержать известные товарные знаки. Не имеет значения, требуется ли удалять эти знаки при модификации, до тех пор, пока их можно легко удалить без потери функциональности.
Однако недопустимо применять товарные знаки для ограничения буквального копирования и перераспространения всего дистрибутива или любой его части.
Документация
Вся документация в свободном дистрибутиве системы должна выпускаться под соответствующей свободной лицензией. Кроме того, в ней должно уделяться внимание тому, чтобы не рекомендовались несвободные программы.
В общем случае допустимо то, что помогает людям, уже применяющим несвободные программы, лучше применять совместно с ними свободные программы, но то, что поощряет пользователей свободных программ устанавливать несвободные программы, неприемлемо.
Например, в свободном дистрибутиве системы может быть документация по установке системы двойной загрузки. Эта документация может объяснять, как получить доступ к файловым системам несвободной операционной системы, импортировать из нее настройки и так далее. Это помогло бы людям установить свободный дистрибутив системы на машину, где уже есть такие несвободные программы, а это хорошо.
Недопустимо для документации было бы давать людям инструкции, как установить несвободную программу в системе, или упоминать удобства, которые им это могло бы дать.
В предельно допустимом случае ясный и серьезный призыв не применять несвободную программу перемещает его от границы в сторону допустимого.
Патенты
Для разработчиков и поставщиков свободных программ фактически невозможно узнать, не нарушает ли данная программа какие-либо патенты: их слишком много, они варьируются от страны к стране, они часто нарочно сформулированы так, чтобы было трудно понять, к чему они относятся, а к чему — нет, и нелегко сказать, какие из них действительны. Поэтому мы в общем случае не просим, чтобы свободные дистрибутивы систем исключали программы в связи с возможной угрозой со стороны патентов. С другой стороны, мы также и не возражаем против того, чтобы поставщик исключал некоторые программы, чтобы избежать патентного риска.
Отсутствие вредоносных программ
В дистрибутиве не должно быть цифрового управления ограничениями, черных ходов и программ-шпионов.
Намерение исправлять ошибки
У большинства коллективов разработчиков дистрибутивов нет средств, чтобы целиком и полностью проверить свой дистрибутив на соответствие всем этим критериям. И у нас — тоже. Так что мы допускаем, что в дистрибутивах время от времени будут появляться ошибки: проскользнувшие несвободные программы и т.д. Мы не отвергаем дистрибутив из-за ошибок. Наше требование — чтобы у разработчиков дистрибутива было твердое намерение немедленно исправлять любые ошибки, о которых им сообщают.
Поддержка
Чтобы попасть в список, дистрибутив должен активно поддерживаться; он должен предоставить проекту GNU свой собственный конкретный канал для сообщения о проблемах с несвободными программами, о которых мы узнаем. Он также должен информировать нас, когда будут решены проблемы, о которых мы сообщили.
Путаница в названиях
Мы не заносим в список дистрибутивы, название которых легко спутать с названием несвободного дистрибутива. Например, если “Foobar любителей” — свободный дистрибутив, а “Foobar” — несвободный дистрибутив, мы не внесем в список “Foobar для любителей”, поскольку мы предполагаем, что различие между этими двумя дистрибутивами будет потеряно в процессе передачи сообщения.
В частности, основа названия свободного дистрибутива (в данном примере “Foobar”) не должно быть частью названия никакого несвободного дистрибутива.
У некоторых возникала мысль добавить название “GNU” к названию свободного дистрибутива, чтобы отличать его от несвободного. Здесь есть две проблемы. Во-первых, два названия не были бы достаточно различны, поскольку слово-основа в обоих названиях была бы одна и та же.
Во-вторых, это распространяло бы неверное понимание того, что означает “GNU”. GNU — это операционная система, типично применяемая с Linux в качестве ядра, и по существу все так называемые дистрибутивы “Linux” в действительности являются дистрибутивами GNU/Linux. В рассматриваемом случае обе системы являются GNU/Linux, если бы “GNU” в названии одного из них опускалось, это вводило бы в заблуждение.
Связь распространителей с разработчиками
Для разработчиков дистрибутива или кого-нибудь еще, кто присылает важный отчет об ошибке в одном из пакетов GNU: если лицо, ответственное за поддержку, оставляет отчет без внимания в течение достаточно длительного времени (пожалуйста, подождите хотя бы две недели), вы можете поднять вопрос на более высокий уровень, написав по адресу . В особенности это имеет смысл, если активности ответственного за поддержку пакета лица давно не наблюдалось.
Пожалуйста, рассказывайте о свободных программах пользователям
Чтобы установить продолжительную свободу, недостаточно просто давать свободу пользователям. Необходимо также приучать их к пониманию того, что означает свобода, и к потребности в ней. Итак, мы настоятельно рекомендуем, чтобы свободные дистрибутивы объявляли заметным образом на экране, перед входом в систему и по умолчанию после входа, заметное сообщение о свободе, такое, как “Эта система состоит из свободных программ, уважающих свободу”, или какое-нибудь сопоставимое, и демонстрировали ссылку или пиктограмму, указывающую на gnu.org или gnu.org/philosophy для более подробных сведений о вопросе.
Пожалуйста, не повторяйте пропаганду и путаницу
Пожалуйста, ознакомьтесь с нашим списком слов, которых следует избегать: они либо необъективны и вводят в заблуждение; старайтесь избегать их в своих публичных заявлениях и дискуссиях.
Окончательные замечания
Мы также перечисляем свободные дистрибутивы систем, отличных от GNU, на тех же этических основаниях.
Если у вас есть вопросы или замечания по самим этим рекомендациям, присылайте их по адресу < licensing@fsf.org>. Мы надеемся, что они помогут всем лучше понять вопросы, важные для свободных дистрибутивов систем, и мы хотим оказывать поддержку большему их числу в будущем.
Компиляция и установка программ из исходников
Не редко необходимые пакеты можно найти только в виде исходных текстов, в данной статье описывается метод установки пакета из исходных текстов.
Распаковка
Программы обычно распространяются в упакованных архивах, это файлы с расширениями
.tar.gz (иногда .tgz) .tar.bz2
Нужно понимать отличие между архиватором и упаковщиком.
Для архивации директорий и файлов используется программа tar; результатом её работы является файл с расширением .tar. Грубо говоря, это копия файловой системы — директорий и файлов с их атрибутами и правами доступа, помещённая в один файл.
Данный файл по размеру будет чуть больше, чем суммарный размер файлов, которые были архивированы. Поэтому (а может и по другой причине) используют упаковщики — программы, которые позволяют уменьшить размер файла без потери данных.
Программа tar умеет распаковывать, поэтому не нужно вызывать gunzip, а можно просто указать программе tar, что файл нужно cначала распаковать. Например, команда
tar -xvf some_app_name>.tar.gz
сразу распакует и разархивирует. Отличие файлов с расширениями
.tar.gz
.tar.bz2
лишь в том, что использовались разные упаковщики, программа tar определяет метод сжатия автоматически и дополнительных опций в данном случае не требуется.
После распаковки необходимо перейти в полученный каталог, все описываемые ниже команды выполняются в каталоге с исходными текстами пакета.
cd имя_пакета>*
Сборка пакета
Для сборки программ в GNU/Linux используется (в основном) программа make, которая запускает инструкции из Makefile, но поскольку дистрибутивов GNU/Linux много, и они все разные, то для того чтобы собрать программу, нужно для каждого дистрибутива отдельно прописывать пути,где какие лежат библиотеки и заголовочные файлы. Программисты не могут изучать каждый дистрибутив и для каждого отдельно создавать Makefile. Поэтому придумали конфигураторы, которые «изучают» систему, и в соответствии с полученными знаниями создают Makefile. Но на конфигураторе они не остановились и придумали конфигураторы конфигураторов ![]() …на этом они остановились
…на этом они остановились ![]()
Для сборки нам нужны компиляторы: они прописаны в зависимостях пакета build-essential, так что достаточно установить его со всеми зависимостями. Ещё нужны autoconf и automake.
Итак, чтобы собрать что-то из исходников, нужно сначала собрать конфигуратор; как собрать конфигуратор, описано в файле configure.in. Для сборки конфигуратора необходимо выполнить
./bootstrap
./autogen.sh
Если таких скриптов в архиве не оказалось, то можно выполнить последовательно следующие команды:
aclocal autoheader automake --gnu --add-missing --copy --foreign autoconf -f -Wall
Все эти команды используют файл configure.in. После выполнения этих команд создастся файл configure. После этого необходимо запустить конфигуратор для проверки наличия всех зависимостей, а также установки дополнительных опций сборки (если возможно) и просмотра результата установки (опционально- может не быть)
./configure
Конфигуратор построит Makefile основываясь на полученных знаниях и файле makefile.am. Можно передать конфигуратору опции, предусмотренные в исходниках программы, которые позволяют включать/отключать те или иные возможности программы, обычно узнать о них можно командой
./configure --help
Также есть набор стандартных опций, вроде
--prefix=
, которая указывает, какой каталог использовать для установки. Для Ubuntu обычно
--prefix=/usr
--prefix=/usr/local
БЕЗ слеша в конце! Теперь можно запустить процесс сборки самой программы командой
make
Для сборки достаточно привелегий обычного пользователя. Окончанием сборки можно считать момент, когда команды в консоли перестанут «беспорядочно» выполняться и не будет слова error. Теперь всё скомпилировано и готово для установки.
Установка
Усилия потраченные на Правильную установку в последствии с лихвой окупятся в случае удаления или обновления устанавливаемого программного обеспечения.
Правильная установка(Вариант №1)
Установка при помощи утилиты checkinstall. Для установки выполните
sudo apt-get install checkinstall
Минус данного способа: checkinstall понимает не все исходники, поскольку автор программы может написать особые скрипты по установке и checkinstall их не поймёт.
Для создания и установки deb-пакета необходимо выполнить
sudo checkinstall
Правильная установка(Вариант №2)
Быстрое создание deb-пакета «вручную».
Основное отличие от предыдущего способа заключается в том, что в данном случае вы создаете пакет вручную и отслеживаете все вносимые изменения. Так же этот способ подойдет вам, если исходники не поддерживают сборку пакета с checkinstall.
Производим установку во временную директорию, где получаем весь набор устанавливаемых файлов:
fakeroot make install DESTDIR=`pwd`/tempinstall
Создадим в «корне пакета» директорию DEBIAN и сложим в DEBIAN/conffiles список всех файлов, которые должны попасть в /etc:
сd tempinstall mkdir DEBIAN find etc | sed "s/^/\//" > DEBIAN/conffiles
После чего создаём файл DEBIAN/control следующего содержания:
Package: имя_пакета Version: 1.2.3 Architecture: amd64/i386/armel/all Maintainer: Можете вписать своё имя, можете дребедень, но если оставить пустым, то dpkg будет ругаться Depends: Тут можно вписать список пакетов через запятую. Priority: optional Description: Тоже надо что-нибудь вписать, чтобы не кидало предупреждения
При необходимости там же можно создать скрипты preinst, postinst, prerm и postrm.
Создаем deb-пакет, для чего выполняем:
dpkg -b tempinstall
Получаем на выходе tempinstall.deb, который и устанавливаем
sudo dpkg -i tempinstall.deb
Сборка проекта на С++ в GNU/Linux
Язык С++ является компилируемым, то есть трансляция кода с языка высокого уровня на инструкции машинного кода происходит не в момент выполнения, а заранее — в процессе изготовления так называемого исполняемого файла (в ОС Windows такие файлы имеют расширение .exe , а в ОС GNU/Linux чаще всего не имеют расширения).
hello.cpp
Пример простой программы на С++, которая печатает «Привет, Мир!»:
#include int main() std::cout <"Hello, World!" <std::endl; return 0; >
Для вывода здесь используется стандартная библиотека iostream , поток вывода std::cout .
Исполняемые операторы в программах на С++ не могут быть сами по себе — они должны быть обязательно заключены в функции.
Функция main() — это главная функция, выполнение программы начинается с её вызова и заканчивается выходом из неё. Возвращаемое значение main() в случае успешных вычислений должно быть равно 0, что значит «ошибка номер ноль», то есть «нет ошибки». В противном процесс, вызвавший программу, может посчитать её выполнившейся с ошибкой.
Чтобы выполнить программу, нужно её сохранить в текстовом файле hello.cpp и скомпилировать следующей командой:
$ g++ -o hello hello.cpp
Опция -o сообщает компилятору, что итоговый исполняемый файл должен называться hello . g++ — это компилятор языка C++, входящий в состав проекта GCC (GNU Compiler Collection). g++ не является единственным компиляторм языка C++. Помимо него в ходе курса мы будет использовать компилятор clang , поскольку он обладает рядом преимуществ, из которых нас больше всего интересует одно — этот компилятор выдаёт более понятные сообщения об ошибках по сравнению с g++ .
Упражнение №1
Скомпилируйте и выполните данную программу.
Ввод и вывод на языке С++
В Python и в С ввод и вывод синтаксически оформлены как вызов функции, а в С++ — это операция над объектом специального типа — потоком.
Потоки определяются в библиотеке iostream, где определены операции ввода и вывода для каждого встроенного типа.
Вывод
Все идентификаторы стандартной библиотеки определены в пространстве имен std , что означает необходимость обращения к ним через квалификатор std:: .
std::cout "mipt"; std::cout 2018; std::cout '.'; std::cout true; std::cout std::endl;
Заметим, что в С++ мы не прописываем типы выводимых значений, компилятор неким (пока непонятным) способом разбирается в типе выводимого значения и выводит его соответствующим образом.
Вывод в один и тот же поток можно писать в одну строчку:
std::cout "mipt" 2018 '.' true std::endl;
Для вывода в поток ошибок определён поток std::cerr .
Ввод
Поток ввода с клавиатуры называется std::cin , а считывание из потока производится другой операцией — >> :
std::cin >> x;
Тип считываемого значения определяется автоматически по типу переменной x .
Для всех типов, кроме char , считывание будет производиться с пропуском символов-разделителей и до следующего символа-разделителя. При этом пробел и табуляция так же, как и символ перевода каретки, являются корректными разделителями. Считывание в char происходит посимвольно независимо от типа символа.
Например для введенной строки «Иван Иванович Иванов»,
std::string name; std::cin >> name;
считает в name только первое слово «Иван».
Считать всю строку целиком можно с помощью функции getline() :
std::string name; std::getline(std::cin, name);
Считывать несколько значений можно и в одну строку:
std::cin >> x >> y >> z;
Упражнение №2
Напишите программу, которая считает гипотенузу прямоугольного треугольника по двум катетам. Ввод и вывод стандартные.
| Ввод | Вывод |
| 3 4 | 5 |
Сумма первых n натуральных чисел
Пример программы, которая подсчитывает сумму первых n натуральных чисел:
#include int main() int n = 0; std::cin >> n; int sum = 0; for (int i = 1; i n; i++) sum += i; > std::cout <sum <std::endl; return 0; >
Как известно, если сложную задачу разбить на несколько простых подзадач, то её решение сильно упрощается. Поэтому не стоит писать весь код в одной функции main() . Лучше разбивать код на отдельные функции, каждая из которых решает свою несложную подзадачу, но делает это хорошо. Например, в предыдущем примере можно вынести функциональность подсчёта суммы первых n натуральных чисел в отдельную функцию:
#include int GetNaturalsSum(const int n) int sum = 0; for (int i = 1; i n; i++) sum += i; > return sum; > int main() int n = 0; std::cin >> n; std::cout <GetNaturalsSum(n) <std::endl; return 0; >
Эмперическое правило: каждая функция не должна превышать по размеру 1 экран вашего монитора.
Этапы сборки: препроцессинг, компиляция, компоновка
Компиляция исходных текстов на Си в исполняемый файл происходит в три этапа.
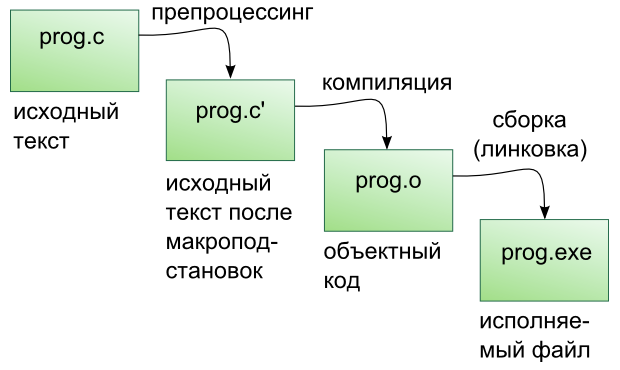
Препроцессинг
Эту операцию осуществляет текстовый препроцессор.
Исходный текст частично обрабатывается — производятся:
- Замена комментариев пустыми строками
- Текстовое включение файлов — #include
- Макроподстановки — #define
- Обработка директив условной компиляции — #if , #ifdef , #elif , #else , #endif
Компиляция
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. Последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла.
- Генерация кода. Из промежуточного представления порождается объектный код.
Результатом компиляции является объектный код.
Объектный код — это программа на языке машинных кодов с частичным сохранением символьной информации, необходимой в процессе сборки.
При отладочной сборке возможно сохранение большого количества символьной информации (идентификаторов переменных, функций, а также типов).
Компоновка
Компоновка также называется связывание или линковка. На этом этапе отдельные объектные файлы проекта соединяются в единый исполняемый файл.
На этом этапе возможны так называемые ошибки связывания: если функция была объявлена, но не определена, ошибка обнаружится только на этом этапе.
Упражнение №3
Выполните в консоли для ранее созданного файла hello.cpp последовательно операции препроцессинга, компиляции и компоновки:
$ g++ -E -o hello1.cpp hello.cpp
- Компиляция:
$ g++ -c -o hello.o hello1.cpp
- Компоновка:
$ g++ -o hello hello.o
Принцип раздельной компиляции
Компиляция — алгоритмически сложный процесс, для больших программных проектов требующий существенного времени и вычислительных возможностей ЭВМ. Благодаря наличию в процессе сборки программы этапа компоновки (связывания) возникает возможность раздельной компиляции.
В модульном подходе программный код разбивается на несколько файлов .cpp , каждый из которых компилируется отдельно от остальных.
Это позволяет значительно уменьшить время перекомпиляции при изменениях, вносимых лишь в небольшое количество исходных файлов. Также это даёт возможность замены отдельных компонентов конечного программного продукта, без необходимости пересборки всего проекта.
Пример модульной программы с раздельной компиляцией на С++
Рассмотрим пример: есть желание вынести часть кода в отдельный файл — пользовательскую библиотеку.
program.cpp
#include "mylib.hpp" const int MAX_DIVISORS_NUMBER = 10000; int main() int number = read_number(); int Divisor[MAX_DIVISORS_NUMBER]; int Divisor_top = 0; factorize(number, Divisor, &Divisor_top); print_array(Divisor, Divisor_top); return 0; >
Подключение пользовательской библиотеки в С++ на самом деле не так просто, как кажется.
Сама библиотека должна состоять из двух файлов: mylib.hpp и mylib.cpp :
mylib.hpp
#ifndef MY_LIBRARY_H_INCLUDED #define MY_LIBRARY_H_INCLUDED #include //считываем число int read_number(); //получаем простые делители числа // сохраняем их в массив, чей адрес нам передан void factorize(int number, int *Divisor, int *Divisor_top); //выводим число void print_number(int number); //распечатывает массив размера A_size в одной строке через TAB void print_array(int A[], size_t A_size); #endif // MY_LIBRARY_H_INCLUDED
mylib.cpp
#include #include "mylib.hpp" //считываем число int read_number() int number; std::cin >> number; return number; > //получаем простые делители числа // сохраняем их в массив, чей адрес нам передан void factorize(int x, int *Divisor, int *Divisor_top) for (int d = 2; d x; d++) while (x%d == 0) Divisor[(*Divisor_top)++] = d; x /= d; > > > //выводим число void print_number(int number) std::cout <number <std::endl; > //распечатывает массив размера A_size в одной строке через TAB void print_array(int A[], size_t A_size) for(int i = A_size-1; i >= 0; i--) std::cout <A[i] <'\t'; > std::cout <std::endl; >
Препроцессор С++, встречая #include «mylib.hpp» , полностью копирует содержимое указанного файла (как текст) вместо вызова директивы. Благодаря этому на этапе компиляции не возникает ошибок типа Unknown identifier при использовании функций из библиотеки.
Файл mylib.cpp компилируется отдельно.
А на этапе компоновки полученный файл mylib.o должен быть включен в исполняемый файл program .
Cреда разработки обычно скрывает весь этот процесс от программиста, но для корректного анализа ошибок сборки важно представлять себе, как это делается.
Упражнение №4
Давайте сделаем это руками:
$ g++ -c mylib.cpp # 1 $ g++ -c program.cpp # 2 $ g++ -o program mylib.o program.o # 3
Теперь, если изменения коснутся только mylib.cpp , то достаточно выполнить только команды 1 и 3. Если только program.cpp, то только команды 2 и 3. И только в случае, когда изменения коснутся интерфейса библиотеки, т.е. заголовочного файла mylib.hpp , придётся перекомпилировать оба объектных файла.
Утилита make и Makefile
Утилита make предназначена для автоматизации преобразования файлов из одной формы в другую. По отметкам времени каждого из имеющихся объектных файлов (при их наличии) она может определить, требуется ли их пересборка.
Правила преобразования задаются в скрипте с именем Makefile , который должен находиться в корне рабочей директории проекта. Сам скрипт состоит из набора правил, которые в свою очередь описываются:
- целями (то, что данное правило делает);
- реквизитами (то, что необходимо для выполнения правила и получения целей);
- командами (выполняющими данные преобразования).
В общем виде синтаксис Makefile можно представить так:
# Отступ (indent) делают только при помощи символов табуляции, # каждой команде должен предшествовать отступ : .
То есть, правило make это ответы на три вопроса:
—> [Как делаем? (команды)] —>
Несложно заметить что процессы трансляции и компиляции очень красиво ложатся на эту схему:
Простейший Makefile
Для компиляции hello.cpp достаточно очень простого мэйкфайла:
hello: hello.cpp gcc -o hello hello.cpp
Данный Makefile состоит из одного правила, которое в свою очередь состоит из цели — hello , реквизита — hello.cpp , и команды — gcc -o hello hello.cpp .
Теперь, для компиляции достаточно дать команду make в рабочем каталоге. По умолчанию make станет выполнять самое первое правило, если цель выполнения не была явно указана при вызове:
Makefile для модульной программы
program: program.o mylib.o g++ -o program program.o mylib.o program.o: program.cpp mylib.hpp g++ -c program.cpp mylib.o: mylib.cpp mylib.hpp g++ -c hylib.cpp
Попробуйте собрать этот проект командой make или make hello . Теперь измените любой из файлов .cpp и соберите проект снова. Обратите внимание на то, что во время повторной компиляции будет транслироваться только измененный файл.
После запуска make попытается сразу получить цель program , но для ее создания необходимы файлы program.o и mylib.o , которых пока еще нет. Поэтому выполнение правила будет отложено и make станет искать правила, описывающие получение недостающих реквизитов. Как только все реквизиты будут получены, make`вернется к выполнению отложенной цели. Отсюда следует, что `make выполняет правила рекурсивно.
Фиктивные цели
На самом деле в качестве make целей могут выступать не только реальные файлы. Все, кому приходилось собирать программы из исходных кодов, должны быть знакомы с двумя стандартными в мире UNIX командами:
$ make $ make install
Командой make производят компиляцию программы, командой make install — установку. Такой подход весьма удобен, поскольку все необходимое для сборки и развертывания приложения в целевой системе включено в один файл (забудем о скрипте configure ). Обратите внимание на то, что в первом случае мы не указываем цель, а во втором целью является вовсе не создание файла install , а процесс установки приложения в систему. Проделывать такие фокусы нам позволяют так называемые фиктивные (phony) цели. Вот краткий список стандартных целей:
all — является стандартной целью по умолчанию. При вызове make ее можно явно не указывать; clean — очистить каталог от всех файлов полученных в результате компиляции; install — произвести инсталляцию; uninstall — и деинсталляцию соответственно.
Для того чтобы make не искал файлы с такими именами, их следует определить в Makefile , при помощи директивы .PHONY . Далее показан пример Makefile с целями all , clean , install и uninstall :
.PHONY: all clean install uninstall all: program clean: rm -rf mylib *.o program.o: program.cpp mylib.hpp gcc -c -o program.o program.cpp mylib.o: mylib.cpp mylib.hpp gcc -c -o mylib.o mylib.cpp program: program.o mylib.o gcc -o mylib program.o mylib.o install: install ./program /usr/local/bin uninstall: rm -rf /usr/local/bin/program
Теперь мы можем собрать нашу программу, произвести ее инсталлцию/деинсталляцию, а так же очистить рабочий каталог, используя для этого стандартные make цели.
Обратите внимание на то, что в цели all не указаны команды; все что ей нужно — получить реквизит program . Зная о рекурсивной природе make, не сложно предположить, как будет работать этот скрипт. Также следует обратить особое внимание на то, что если файл program уже имеется (остался после предыдущей компиляции) и его реквизиты не были изменены, то команда make ничего не станет пересобирать. Это классические грабли make. Так, например, изменив заголовочный файл, случайно не включенный в список реквизитов (а надо включать!), можно получить долгие часы головной боли. Поэтому, чтобы гарантированно полностью пересобрать проект, нужно предварительно очистить рабочий каталог:
$ make clean $ make
P.S. Неплохая статья с описанием мейкфайлов.
Сайт построен с использованием Pelican. За основу оформления взята тема от Smashing Magazine. Исходные тексты программ, приведённые на этом сайте, распространяются под лицензией GPLv3, все остальные материалы сайта распространяются под лицензией CC-BY-SA.
Анатомия GNU/Linux
Какое-то время назад на Хабре была небольшая волна постов на тему «Почему я [не] выбрал Linux». Как порядочный фанатик я стриггерился, однако решил, что продуктивнее что-нибудь рассказать о своей любимой системе, чем ломать копии в комментариях.
У меня сложилось впечатление, что многие пользователи GNU/Linux слабо представляют, из чего сделана эта операционная система, поэтому утверждают, что она сляпана из попавшихся под руку кусков. В то же время, архитектура большинства дистрибутивов является устоявшейся и регламентируется рядом стандартов, включая стандарт графического окружения freedesktop.org и Linux Standard Base, расширяющий стандарты Unix. Мне при знакомстве с GNU/Linux несколько лет назад для погружения не хватало простой анатомической карты типичного дистрибутива, поэтому я попробую рассказать об этом сам.
Загрузчик
Сеанс операционной системы начинается с загрузчика, как театр с вешалки. Дефолтным загрузчиком сегодня является GNU GRUB, известный так же как GRUB 2. По-прежнему доступна первая ветка, называемая теперь «GRUB Legacy». Другой загрузчик с давней историей — Syslinux.
Задача загрузчика — инициализировать ядро Linux. Для этого, в общем случае, нужно знать, где ядро лежит, и уметь прочитать это место (раздел Ext4, скажем). Ядру в помощь загрузчик обычно так же подтягивает начальный образ загрузки, о котором скажем позже. GRUB умеет много прочего, типа построения весьма сложных меню и чейнлоадинга других загрузчиков (Windows Boot Manager например). GRUB имеет конфигурационный синтаксис, отдалённо напоминающий шелл, и расширяется модулями.
GRUB велик и могуч, порой даже слишком, и встраиваемые системы часто используют компактный Das U-Boot.
Ядро
Могучий Linux («не оставляй нас, монолит!»). Ядро операционной системы, созданное, чтобы работать с POSIX-совместимыми окружениями. Обычно лежит в /boot/ и содержит в названии слово vmlinuz , где «vm» напоминает нам о поддержке виртуальной памяти, а «z» указывает, что файл сжат.
В рамках одного дистрибутива может поддерживаться несколько вариантов ядра, например:
- mainline («основное»);
- LTS (с расширенной поддержкой);
- rt (патченное для поддержки исполнения в режиме реального времени);
- с различными патчами для повышения производительности или защищённости (zen, hardened etc);
- libre (почищенное от проприетарных блобов ядро, ожидаемо поддерживающее мало оборудования).
- совсем экзотичные варианты с не-Linux ядром типа Debian GNU/Hurd (с ядром GNU Hurd) и Debian GNU/kFreeBSD (с ядром FreeBSD соответственно). Это уже, конечно, не GNU/Linux.
Начальный образ загрузки
Начальный образ загрузки известен так же как initrd и initramfs. Представляет собой архив с образом файловой системы, развёртываемой в оперативную память в начале процесса загрузки. Несёт в себе различные драйверы и скрипты, позволяющие инициализировать оборудование и смонтировать файловые системы.
Содержимое начального образа загрузки зависит от версии ядра и потребностей пользователя (кто-то использует ZFS, а у кого-то корень зашифрован LUKS). Поэтому образ не поставляется в дистрибутивах. В дистрибутивах поставляются фреймворки для создания начальных образов по мере необходимости. Так, обычно создание свежего образа инициируется при обновлении ядра. Вот несколько популярных фреймворков:
- initramfs-tools — детище Debian.
- Dracut (произносится созвучно с сушёной кошкой) — в RHEL и производных (CentOS, Scientific Linux etc.). Наиболее гибкий и современный инструмент из перечисленных, если спросите меня.
- mkinitcpio поставляется в Archlinux, хотя мейнтейнеры подумывают о Dracut, который уже включён в репозиторий и установочные образы.
- make-initrd — свой путь у замечательного отечественного дистрибутива Alt Linux.
Тут же упомянем Plymouth, размещаемый в начальном образе. Это заставка (сплэш-скрин), позволяющая заменить вывод ядра при загрузке на произвольную анимированную картинку, например логотип дистрибутива, что принято в «дружелюбных к пользователю»™ дистрибутивах типа Ubuntu и Fedora.
Init
Система инициализации — это пастырь процессов. Она стартует раньше всех и имеет PID 1. Она определяет уровень запуска системы и жизненный цикл большинства служб. Независмо от того, что за система инициализации представлена, она предлагает исполняемые файлы /sbin/init (или /usr/bin/init , или в том же духе, ну вы поняли).
Холиварный элемент. Много лет с нами была Sysvinit, пришедшая из варианта ОС Unix System V. Sysvinit полагалась в огромной степени на скрипты инициализации. Служил этот инит, в общем, исправно, но постепенно некоторым инженерам стало мозолить глаза последовательное исполнение скриптов и собственно скрипты, известные в жарких спорах за свою распростёртость как «баш-портянки». В конце 00-ых-начале 10-ых как грибы после дождя расплодились альтернативные системы инициализации: OpenRC от Gentoo, Upstart от Canonical, Systemd от Red Hat за авторством Леннарта Поттеринга. В конце концов по причинам техническим и политическим всех сожрала Systemd. Её восхваляют и ненавидят. Восхваляют в основном за простой и лаконичный синтаксис служб. Так, скрипт запуска веб-сервера Apache для классического инита занимает 153 строки включая комментарии, а файл службы из пакета apache в Arch Linux — 15 строк. Недолюбливают в основном за то, что эта система инициализации подрабатывает ещё и резолвером, планировщиком, менеджером сети, менеджером монтирования и Бог весть ещё чем, попирая дзен Unix.
Командная оболочка
Командная оболочка, она же командный интерпретатор или просто шелл. Неискушённый пользователь скажет — «в гробу я этот шелл видал, можно в графическом режиме жить», и будет неправ, поскольку шелл прописан в стандарте POSIX и необходим для работоспособности системы. Есть понятие «оболочка входа» (login shell) — это первый процесс, запускамый при входе пользователя. Он подтягивает опции и переменные окружения из конфигурационных файлов, все последующие процессы запускаются в контексте этого шелла. Что будет запущено в качестве оболочки входа, определяется в /etc/passwd .
Наиболее распространены сегодня следующие оболочки:
- Bourne shell (sh) — «тот самый шелл», сложно найти дистрибутив без него.
- Bourne again shell (bash) — принят по умолчанию в качестве пользователькой оболочки в большинстве GNU/Linux дистрибутивов и предлагает ряд удобств по сравнению с sh.
- Debian Almquist shell (dash) — компактная облочка, совместимая с sh. Традиционно используется в Debian, где /usr/bin/sh на неё ссылается.
- Z shell (zsh) — похож на bash, но предлагает оригинальные фишечки для интерактивного ввода. Редко идёт из коробки, но обычно поставляется в репозитории.
- BusyBox — утилита для встраиваемых систем, которая предоставляет целое пользовательское окружение, в том числе — POSIX-совместимый шелл (вызывается так: $ busybox sh ).
Графический сервер
Демон, отвечающий за отрисовку окошек. Золотой стандарт графического сервера — X Window System с нами аж с 1984 года. Это именно стандарт, архитектура и набор протоколов. Реализаций за прошедшие годы была уйма, в каждой собственнической Unix-системе была своя. В GNU/Linux (и BSD) долгое время применялся Xfree86. Теперь с нами X.Org Server, или просто Xorg, он отпочковался от XFree86.
X Window System — мощная и богатая система, так, одна из возможностей — сетевая прозрачность. Вы можете запустить на своём хосте графическое приложение с другой машины, даже когда на той машине графический сервер не запущен. При помощи SSH это можно сделать, например, так (может потребоваться небольшая донастройка sshd):
$ ssh -X hostname firefoxНадо сказать, терминология X Window System контринтуитивна: клиентом называется графическое приложение, а сервером — отрисовывающее. На этот счёт прошлись в классической монографии «The UNIX-HATERS Handbook».
Другая возможность X, отрисовка графических примитивов и текстовых глифов, использовалась в старые времена, когда мужчины были мужчинами и рисовали окошки сами, без тулкитов.
В окружениях рабочих столов активно используется X keyboard extension, расширение, отображающее нажатие клавиш на различные раскладки.
«Иксам» пророчат скорую кончину. Именно обширность и сложность стандарта побудила разработчиков СПО начать работу над новым стандартом — протоколом Wayland. Wayland достиг определённой стадии зрелости и с переменным успехом внедряется дистрибутивами как графический сервер по умолчанию. Тем не менее, проект Wayland начат в 2008 году, а стандарт X ещё не спешит уходить с голубых экранов.

На скриншоте Weston — эталонная реализация композитного менеджера Wayland. Умеет крутить окошки. А ещё его можно запустить внутри другого рабочего стола, просто выполнив в терминале weston .
После старта графический сервер обслуживает иерархию окон. Существует понятие «корневое окно» (root window), оно, в свою очередь, «владеет» окнами панелей, приложений. Окна приложений «владеют» своими модальными окнами. Обычно обои рабочего стола отрисовываются в корневом окне.
Дисплейный менеджер
Не вполне интуитивно названные, дисплейные менеджеры (DM) рисуют для нас приветливое окошко входа в систему. Обычно, помимо ввода логина и пароля, они позволяют выбрать сессию (при наличии выбора в вашей системе) и задать язык сеанса. Дисплейные менеджеры делают плюс-минус одну и ту же нехитрую работу, их многообразие оправдано консистентностью с различными средами рабочего стола (что зависит, по большей части, от графического тулкита и утилит настройки). Можно жить без дисплейного сервера, как в старые добрые времена. Для этого потребуется настроить ваш ~/.xinitrc на запуск необходимого сеанса рабочего стола. Это позволит входить через ядерную консоль и запускать рабочий стол командой startx .


Типичные представители дисплейных менеджеров:
- GDM из набора GNOME;
- SDDM из комплекта KDE;
- LightDM — универсальный вариант;
- FlyDM — из поставки Astra Linux.
Окружение рабочего стола
Окружения рабочего стола (DE) состоит из ряда стандартных компонентов, таких, как:
- диспетчер окон;
- файловый менеджер;
- панель с треем и меню запуска приложений;
- эмулятор терминала;
- хранитель экрана, он же блокировщик экрана;
- менеджер питания;
- браузер, которым никто не пользуется;
- почтовый клиент (у зажиточных окружений);
- и проч., и проч.
Два могучих окружения, GNOME и KDE, сражаются за сердца простых пользователей, а остальные массовые десктопы им завидуют нередко пользуются их наработками. Некоторые хардкорные пользователи предпочитают собирать окружение рабочего стола самостоятельно на базе оконных менеджеров типа Awesome и i3.

На скриншоте оконный менеджер Window Maker из состава GNUstep. GNUstep воспроизводит окружение NeXTSTEP. Поставляется в репозиториях большинства дистрибутивов.
Графические тулкиты
Графический тулкит — библиотека или фреймворк, упрощающая рисование формочек и кнопочек, причём в едином стиле. То, чем занимается Windows Forms на ОС другого производителя, а так же занимался некогда полулярный Motif на старых юниксах (Open Motif доступен поныне).
Флагманами в этой категории долгое время были и остаются GTK и Qt. GTK родился как тулкит для свободного графического редактора GIMP и позже переполз под крыло GNOME. Написан на чистом C с классами, имеет официальные байндинги к Python и C++, а ещё породил целый язык общего назначения Vala. Qt — изначально коммерческий проприетарный тулкит, сейчас является свободным ПО (но по-прежнему коммерческим). Написан на C++ с размахом, заменяя стандартную библиотеку и кучу других библиотек и предлагая метаобъектный компилятор (кодогенератор). Имеет байндинги к куче языков. KDE гордо зиждется на этом великолепии.
Графическое API
Mesa — это каркас для видеовывода. Меза предоставляет API OpenGL и, с не столь давних пор, Vulkan (и несколько других API типа VDPAU и VAAPI). Можно сказать, что Mesa берёт на себя вопросы графики, которыми обычно занимается DirectX в ОС другого производителя.
Безопасность
Обширная часть системы, и я недостаточно компетентен, чтобы в неё углубляться, тем не менее, обзорно рассмотрим.
PAM — Pluggable Authentication Modules — модульная система авторизации. Отвечает, как понятно из названия, за авторизацию пользователей в системе, причём разными способами. Через PAM авторизуются в том числе доменные пользователи, в таком случае PAM действует в связке с имплементацией Kerberos (обычно MIT’овский krb5), поскольку сам по себе PAM не работает с удалёнными клиентами. Модули представляют собой разделяемые библиотеки (исполняемые файлы с суффиксом so ) и позволяют делать интересные штуки при входе пользователя. Например, можно создавать домашнюю директорию при первом входе ( pam_mkhomedir.so ) или монтировать файловые системы ( pam_mount.so ).
Классическая утилита su и более молодая sudo предназначены для исполнения комманд от имени другого пользователя (по умолчанию root ). Наиболее значимая разница — su требует пароль пользователя, из-под которого вы хотите работать, а sudo — ваш пароль. sudo гибко настраивается, позволяя запускать только определённые команды определённым пользователям из-под других определённых пользователей, как-то так.
Менеджер авторизации Polkit позволяет непривилегированным процессам взаимодействовать с привилегированными. По сути он похож на sudo, но обладает превосходящей гибкостью и предназначен в первую очередь для приложений, в то время как sudo — утилита для пользователя. Правила пишутся, внезапно, на JavaScript’е.
Linux Security Modules (LSM) — фреймворк внутри ядра Linux, позволяющий накладывать на систему дополнительные моде́ли безопасности. Это достигается при помощи мо́дулей безопасности, не путать с модулями ядра. Наиболее популярные модули безопасности — SELinux и AppArmor. Первый явлен миру АНБ и развивается Red Hat, второй рождён в рамках ОС Immunix и сегодня развивается Canonical Ltd. Соответственно, SELinux поставляется в RHEL и производных, а AppArmor — в Ubuntu. Оба модуля имеют сходное назначение и привносят в систему мандатное управление доступом. Оба модуля повышают безопасность системы, не позволяя приложениям делать то, что от них не ожидается. Так, сконфигурированные модули безопасности не дадут веб-серверу шариться по диску вне нескольких ожидаемых директорий. Обратной стороной является необходимость конфигурировать систему безопасности для каждого мало-мальски нестандартно настроенного приложения. Не у многих на это хватает энтузиазма, так что обычно модуль безопасности просто переключается в разрешающий режим.
Антивирусные программы для GNU/Linux существуют, но мне не встречались дистрибутивы, где бы они шли из коробки, кроме специализированных решений для сканирования системы.
Подсистема печати
CUPS — «общая система печати UNIX», рождённая компанией Apple. Система модульная, поддерживает огромное количество устройств и, насколько мне известно, на сегодня не имеет альтернатив. А ещё CUPS имеет веб-интерфейс (по умолчанию на localhost:631).

CUPS работает только с печатающими устройствами, сканеры поддерживаются фреймворком SANE. К сожалению, спектр поддерживаемых устройств у SANE не очень широк. Некоторые вендорские драйверы для МФУ обеспечивают одновременно работоспособность сканера и работоспособность принтера через CUPS. Так, например, делает HPLIP от HP Inc. Благдаря HPLIP GNU/Linux может похвастаться отличной поддержкой печатающих устройств от HP. В то же время, HPLIP прикручен к CUPS немного сбоку, и часто проблематично настроить устройства HP только утилитами CUPS, как многие другие принтеры. Приходится использовать hp-setup .
Звуковая подсистема
Продолжительное время основной звуковой подсистемой ядра является ALSA. Некоторые пользователи ошибочно считают, что PulseAudio заменил ALSA. Это не так, PulseAudio — это звуковой сервер, являющийся лишь слоем абстракции, упрощающим управление аудиопотоками. Другим аудиосервером является JACK, который предназначен для профессиональной работы с аудио. Он не столь удобен для пользователя, но обеспечивает низкие задержки и предоставляет гибкую маршрутизацию MIDI-потоков.
Red Hat готовит нам PipeWire на замену PulseAudio и JACK. Следим за событиями.
Межпроцессное взаимодействие
Здесь речь не про низкоуровневые POSIX-штуки типа разделяемой памяти и сокеты. За свой век GNU/Linux повидал несколько подсистем, призванных упростить межпроцессное взаимодействие (IPC) десктоп-приложений. Сейчас правит бал шина сообщений D-Bus, а об остальных позабыли. Для чего это нужно? Например, некая служба посылает в шину сообщение об изменении своего состояния, а апплет панели слушает его и изменяет свой индикатор. Так обычно работают апплеты громкости и клавиатурной раскладки.
Сеть
Традиционно в различных дистрибутивах GNU/Linux сеть настраивалась скриптами (причём различными). NetworkManager — детище Red Hat, созданное, чтобы править всеми интерфейсами. В годы юности NM вызывал приступы фрустрации у пользователей, но потом всё стало неплохо. NetworkManager позволяет управлять проводными и беспроводными интерфейсами, всевозможными тунелями, виртуальными мостами, VLAN’ами и аггрегированными каналами, причём как при помощи графических фронтендов, так и псевдографического nmtui и текстового nmcli . Вещь удобная и универсальная, в дистрибутивах Red Hat, ожидаемо идёт по умолчанию, в Debian и производных идёт только с рабочим столом, а в «безголовом исполнении» NM опционален. Есть альтернативы попроще, например — Wicd.
Работоспособность WiFi-устройств, как правило, обеспечивает демон WPA supplicant, у которого есть конкурент iwd, написанный ни много ни мало, компанией Intel.
Тут же хочется упомянуть демон Bluez, обеспечивающий работу с Bluetooth-устройствами.
Межсетевой экран
Слава iptables гремит далеко за узким кругом бородатых админов. Это не фильтр сам по себе, а лишь набор утилит в пространстве пользователя, работающий с подсистемой Linux Netfilter. Недавно (в историческом масштабе) добавилась подсистема ядра nftables и соответствующая пользовательская утилита nft. Это было сделано, в первую очередь, для унификации интерфейсов таблиц маршрутизации IPv4, IPv6, ARP и софтовых L2-коммутаторов. В современных дистрибутивах команды iptables являются лишь обёрткой для nftables и не рекомендуются к использованию. В целом, конфиг nft выглядит опрятнее дампа iptables.
Существует пачка высокоуровневых фаерволлов-обёрток над nftables (в том числе графических), так в RHEL и производых из коробки идёт firewalld, а в Ubuntu — UFW.
Пакетный менеджер
Пакетный менеджер — это сердце дистрибутива. Наиболее именитые и с длинной историей — это RPM из мира Red Hat и dpkg из семества Debian. Пример более современного — pacman из Arch Linux. Старожилы RPM и dpkg работают только с локальными пакетами: они их распаковывают, устанавливают и проверяют, что все зависимости удовлетворены. Работой с репозиториями занимаются другие утилиты, являющиеся как бы фронтендом к самому пакетному менеджеру. В RHEL ранее поставлялась утилита yum, на замену которой пришла dnf, в Debian раньше были apt-get и apt-cache, затем их увязали в одну команду apt. Более молодой pacman не имеет видимого пользователю разделения на несколько утилит и предлагает очень простой формат пакетов, которые можно собирать буквально на коленке. Есть и множество других, со своими особенностями. Например nix, который позволяет иметь в системе несколько версий одного пакета.
Новое в исторических масштабах явление — кросс-дистрибутивные системы поставки приложений. Появились в попытке преодолеть ад зависимостей, облегчить труд разработчиков и мейнтейнеров (избавив их от необходимости создавать десятки пакетов под разные версии и ветки GNU/Linux). Наиболее популярные проекты: Flatpack от Gnome, Snap от Canonical и AppImage сам по себе. Они несколько отличаются подходами, но в общем случае обеспечивают установку приложений со всем рантаймом и некоторой степенью изоляции от системы. Штуки удобные, однако подход несколько напоминает традиции тащить все зависимости с устанавливаемой программой в популярной ОС другого производителя. Простоты и порядка в систему не добавляют.
Для перечисленного добра есть красивые обёртки в виде магазинов приложений, два самых ходовых — GNOME Software и KDE Discover.


Заключение
Краткая результирующая диаграмма:

Если присмотреться к перечисленным составляющим GNU/Linux, можно заметить, что львиная доля технологий привносится несколькими крупными организациями. К ним относятся:
- проект GNU под эгидой Free Software Foundation;
- Red Hat, производитель коммерческого дистрибутива, недавно вошедший в состав IBM;
- сообщество kernel.org при поддержке Linux Foundation.
В интернете ради флейма часто вкидывают, мол, поглядите — эти ваши линуксы делают клятые корпорации, где ваше хвалёное сообщество? Я думаю, не стоит противопоставлять отдельных энтузиастов и организации: все они вращают колесо open source. В конце концов, в больших организациях трудятся обычные люди. В итоге мы имеем очень динамичную систему, в которой не без причины компоненты сменяются один за другим, всё это куда-то движется, и, в общем-то, год от года хорошеет. Я надеюсь, в этом очерке удалось дать представление об анатомии GNU/Linux, а может быть и заинтересовать кого-нибудь закопаться поглубже.
Большое спасибо @ajijiadduh, который отловил огромное количество опечаток сразу после публикации, и всем прочим пользователям, указавшим на ошибки.
Правки и предложения вы можете присылать по адресу https://gitlab.com/bergentroll/gnu-linux-anatomy.
Copyright © 2020 Антон «bergentroll» Карманов.